This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data is becoming more valuable and more important to organizations. At the same time, organizations have become more disciplined about the data on which they rely to ensure it is robust, accurate and governed properly.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a businessintelligence dashboard and take action on immediately.
Amazon Redshift is a fast, fully managed petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing businessintelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
This amalgamation empowers vendors with authority over a diverse range of workloads by virtue of owning the data. This authority extends across realms such as businessintelligence, data engineering, and machine learning thus limiting the tools and capabilities that can be used. 5 seconds $0.08 8 seconds $0.07
Giving the mobile workforce access to this data via the cloud allows them to be productive from anywhere, fosters collaboration, and improves overall strategic decision-making. Connecting mainframe data to the cloud also has financial benefits as it leads to lower mainframe CPU costs by leveraging cloud computing for data transformations.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
In this post, we show you how EUROGATE uses AWS services, including Amazon DataZone , to make data discoverable by data consumers across different business units so that they can innovate faster. This agility accelerates EUROGATEs insight generation, keeping decision-making aligned with current data.
For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external datalake are marked as delayed. Sharing Customer 360 insights back without data replication.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Organizations of all sizes are dealing with exponentially increasing data volume and data sources, which creates challenges such as siloed information, increased technical complexities across various systems and slow reporting of important business metrics.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
AWS Glue is a serverless, scalable dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources. AWS Glue provides an extensible architecture that enables users with different data processing use cases.
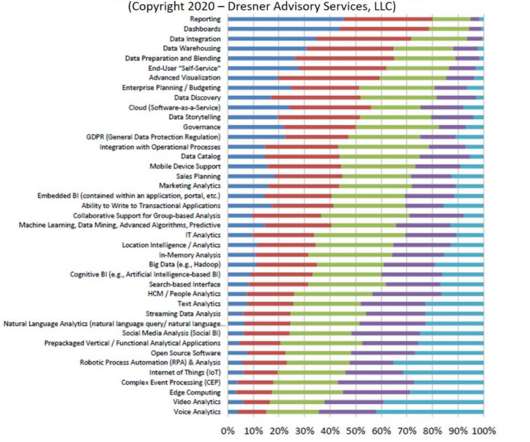
Dresner Advisory Services’ report about self-service businessintelligence uncovered a surprising result. Among all the hot analytics initiatives to choose from (big data, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. Let that sink in.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
In light of these considerations, it has become a growing imperative for business and IT teams to collaborate and align their business priorities for AI use. How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance?
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. Dataintegrity presented a major challenge for the team, as there were many instances of duplicate data.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and datalakes based on operational data.
Data also needs to be sorted, annotated and labelled in order to meet the requirements of generative AI. No wonder CIO’s 2023 AI Priorities study found that dataintegration was the number one concern for IT leaders around generative AI integration, above security and privacy and the user experience.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing businessintelligence tools.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
The desire to modernize technology, over time, leads to acquiring many different systems with various data entry points and transformation rules for data as it moves into and across the organization. Distribute cloud data: erwin DI’s Business User Portal provides self-service access to cloud data asset discovery and reporting tools.
Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Data warehouse Centralized, structured and curated data repository. Inflexible schema, poor for unstructured or real-time data. Datalake Raw storage for all types of structured and unstructured data.
It is noteworthy that business users in particular consider the inability to provide required data and the lack of user acceptance as even more important than enhanced self-service. In particular executives (31 percent) and businessintelligence/analytics teams (30 percent) agree that software licenses are too expensive in general.
We have seen a strong customer demand to expand its scope to cloud-based datalakes because datalakes are increasingly the enterprise solution for large-scale data initiatives due to their power and capabilities. The team uses dbt-glue to build a transformed gold model optimized for businessintelligence (BI).
This post focuses on such schema changes in file-based tables and shows how to automatically replicate the schema evolution of structured data from table formats in databases to the tables stored as files in cost-effective way. Apache Hudi supports ACID transactions and CRUD operations on a datalake. and save it.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing. For more information on AWS Glue, visit AWS Glue.
The data lakehouse is a relatively new data architecture concept, first championed by Cloudera, which offers both storage and analytics capabilities as part of the same solution, in contrast to the concepts for datalake and data warehouse which, respectively, store data in native format, and structured data, often in SQL format.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Set up unified data governance rules and processes.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. Kamen Sharlandjiev is a Sr.
Of course, the value of a strong data foundation is not new and the need for one spans well beyond generative AI. You also need services to store data for analysis and machine learning (ML) like Amazon Simple Storage Service (Amazon S3). Customers have created hundreds of thousands of datalakes on Amazon S3.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Over the last decade, we have often heard about the proliferation of data creating sources (mobile applications, laptops, sensors, enterprise apps) in heterogeneous environments (cloud, on-prem, edge) resulting in the exponential growth of data being created.
You can extend the solution in directions such as the businessintelligence (BI) domain with customer 360 use cases, and the risk and compliance domain with transaction monitoring and fraud detection use cases. The application gets prompt templates from an S3 datalake and creates the engineered prompt.
Synapse services are powerful tools for bringing data together for analytics, machine learning, reporting needs, and more. How Synapse works with DataLakes and Warehouses. Synapse services, datalakes, and data warehouses are often discussed together. Streamline Data with Atlas.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Further, data management activities don’t end once the AI model has been developed. Addressing the Challenge.
The challenge for CIOs who want to improve their company’s analytics capabilities is a familiar one: dataintegrity versus innovation. “In In IT, we have traditionally focused on protecting the single source of truth, but our business functions want to experiment with the data,” says Deepak Kaul, CIO of Zebra Technologies. “To
They can connect to multiple data streams and pull data directly into Amazon Redshift without staging it in Amazon Simple Storage Service (Amazon S3). After running analytics, the insights can be made available broadly across the organization with Amazon QuickSight , a cloud-native, serverless businessintelligence service.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content