This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this analyst perspective, Dave Menninger takes a look at datalakes. He explains the term “datalake,” describes common use cases and shares his views on some of the latest market trends. He explores the relationship between data warehouses and datalakes and share some of Ventana Research’s findings on the subject.
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and businessintelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
When encouraging these BI best practices what we are really doing is advocating for agile businessintelligence and analytics. Therefore, we will walk you through this beginner’s guide on agile businessintelligence and analytics to help you understand how they work and the methodology behind them.
Data warehousing, businessintelligence, data analytics, and AI services are all coming together under one roof at Amazon Web Services. It combines SQL analytics, data processing, AI development, data streaming, businessintelligence, and search analytics.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of businessintelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Organizations are collecting data from multiple data sources and a variety of systems to enrich their analytics and businessintelligence (BI). But collecting data is only half of the equation. As the data grows, it becomes challenging to find the right data at the right time.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
It has a drag and drop visual interface and can connect to databases, enterprise data warehouses, datalakes, cloud storage, business applications and social media. The platform also supports push-down processing for data prep and ETL inside databases to minimize data movement and optimize performance.
Organizations are dealing with exponentially increasing data that ranges broadly from customer-generated information, financial transactions, edge-generated data and even operational IT server logs. A combination of complex datalake and data warehouse capabilities are required to leverage this data.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a businessintelligence dashboard and take action on immediately.
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. Eventually, transactional datalakes emerged to add transactional consistency and performance of a data warehouse to the datalake.
Amazon Redshift is a fast, fully managed petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing businessintelligence (BI) tools. Amazon Redshift also supports querying nested data with complex data types such as struct, array, and map.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular businessintelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
This amalgamation empowers vendors with authority over a diverse range of workloads by virtue of owning the data. This authority extends across realms such as businessintelligence, data engineering, and machine learning thus limiting the tools and capabilities that can be used. 5 seconds $0.08 8 seconds $0.07
Our research shows that external data sources are also a routine part of data preparation processes, with 80% of organizations incorporating one or more external data sources. And a similar proportion of participants in our research (84%) include external data in their datalakes.
Enterprise businessintelligence (BI) continues to be the last mile to insights-driven business (IDB) capabilities. No matter what technology foundation you’re using – a datalake, a data warehouse, data fabric, data mesh, etc.
La firma de consultoría también deberá crear un datalake que permita almacenar y compartir fácilmente los datos de todo el ecosistema deportivo español, para lograr sinergias en torno a los distintos proyectos que se realicen.
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your datalake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable).
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other businessdata, as well as support the use of businessintelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications.
First-generation – expensive, proprietary enterprise data warehouse and businessintelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular businessintelligence (BI) and analytics tools, including partner solutions like Tableau.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
Organizations of all sizes are dealing with exponentially increasing data volume and data sources, which creates challenges such as siloed information, increased technical complexities across various systems and slow reporting of important business metrics.
I previously wrote about the importance of open table formats to the evolution of datalakes into data lakehouses. The concept of the datalake was initially proposed as a single environment where data could be combined from multiple sources to be stored and processed to enable analysis by multiple users for multiple purposes.
Over the years, the adoption of cloud computing has gained momentum with more and more organizations trying to make use of applications, data, analytics and self-service businessintelligence (BI) tools running on top of cloud-computing infrastructure in order to improve efficiency.
Uniteds embrace of SageMaker and Bedrock as well as Amazon Q is going to be a game changer for building data products, said Mai-LanTomsenBukovec, AWS vice president of technology, who pointed to United Data Hub as a transformational component in its AI journey at re:Invent.
In this post, we show you how EUROGATE uses AWS services, including Amazon DataZone , to make data discoverable by data consumers across different business units so that they can innovate faster. We encourage you to read Amazon DataZone concepts and terminology to become familiar with the terms used in this post.
Giving the mobile workforce access to this data via the cloud allows them to be productive from anywhere, fosters collaboration, and improves overall strategic decision-making. Connecting mainframe data to the cloud also has financial benefits as it leads to lower mainframe CPU costs by leveraging cloud computing for data transformations.
AWS Glue provides an extensible architecture that enables users with different data processing use cases. A common use case is building datalakes on Amazon Simple Storage Service (Amazon S3) using AWS Glue extract, transform, and load (ETL) jobs.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing businessintelligence (BI) tools. He was the CEO and co-founder of DataRow, which was acquired by Amazon in 2020.
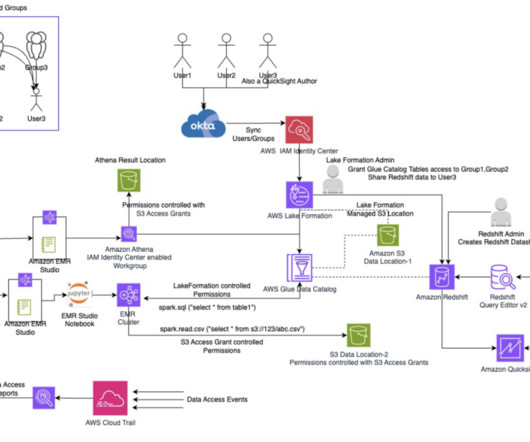
Grant access to User1 in Lake Formation Sign in to the Lake Formation console, choose Datalake permissions in the navigation pane, and grant access to the user group on the database oktank_tipblog_temp and table customer. Refer to the Lake Formation access grants steps performed for User1 and User2 if needed.
We pulled these people together, and defined use cases we could all agree were the best to demonstrate our new data capability. Once they were identified, we had to determine we had the right data. Then we migrated the data to our new datalake, and stood up the new platform.
One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the datalake.
In the context of comprehensive data governance, Amazon DataZone offers organization-wide data lineage visualization using Amazon Web Services (AWS) services, while dbt provides project-level lineage through model analysis and supports cross-project integration between datalakes and warehouses.
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. That team makes sure business cases are aligned with our corporate goals.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content