This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and businessintelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
Initially, data warehouses were the go-to solution for structureddata and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructured data. In practice, OTFs are used in a broad range of analytical workloads, from businessintelligence to machine learning.
In this post, we show you how EUROGATE uses AWS services, including Amazon DataZone , to make data discoverable by data consumers across different business units so that they can innovate faster. This agility accelerates EUROGATEs insight generation, keeping decision-making aligned with current data.
As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Newer datalakes are highly scalable and can ingest structured and semi-structureddata along with unstructured data like text, images, video, and audio.
Previously, Walgreens was attempting to perform that task with its datalake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. Lakehouses redeem the failures of some datalakes.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Solution overview Amazon Redshift is an industry-leading cloud data warehouse.
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing businessintelligence (BI) tools. The Amazon Redshift service must be running in the same Region where the Salesforce Data Cloud is running.
Business needs often drive table structure, such as schema evolution (the addition of new columns, removal of existing columns, update of column names, and so on) for some of these tables in one business function that requires other business functions to replicate the same. and save it. Run the Lambda function.
For instance, a Data Cloud-triggered flow could update an account manager in Slack when shipments in an external datalake are marked as delayed. Sharing Customer 360 insights back without data replication. Currently, Data Cloud leverages live SQL queries to access data from external data platforms via zero copy.
The data lakehouse is a relatively new data architecture concept, first championed by Cloudera, which offers both storage and analytics capabilities as part of the same solution, in contrast to the concepts for datalake and data warehouse which, respectively, store data in native format, and structureddata, often in SQL format.
Collect, filter, and categorize data The first is a series of processes — collecting, filtering, and categorizing data — that may take several months for KM or RAG models. Structureddata is relatively easy, but the unstructured data, while much more difficult to categorize, is the most valuable.
Modernizing data operations CIOs like Woodring know well that the quality of an AI model depends in large part on the quality of the data involved — and how that data is injected from databases, data warehouses, cloud datalakes, and the like into large language models.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption. This is the Data Mart stage.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
She decided to bring Resultant in to assist, starting with the firm’s strategic data assessment (SDA) framework, which evaluates a client’s data challenges in terms of people and processes, data models and structures, data architecture and platforms, visual analytics and reporting, and advanced analytics.
In today’s fast-paced business environment, making informed decisions based on accurate and up-to-date information is crucial for achieving success. With the advent of BusinessIntelligence Dashboard (BI Dashboard), access to information is no longer limited to IT departments.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a datalake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and datalakes can coexist in an organization, complementing each other.
Selling the value of data transformation Iyengar and his team are 18 months into a three- to five-year journey that started by building out the data layer — corralling data sources such as ERP, CRM, and legacy databases into data warehouses for structureddata and datalakes for unstructured data.
Advancements in analytics and AI as well as support for unstructured data in centralized datalakes are key benefits of doing business in the cloud, and Shutterstock is capitalizing on its cloud foundation, creating new revenue streams and business models using the cloud and datalakes as key components of its innovation platform.
Following its acquisition of Neustar, a Google Cloud Platform customer, TransUnion embraced a multicloud infrastructure that also supports GCP, but the crown jewel of its technology modernization is OneTru, and its 50 petabytes of data assets amassed over decades.
Data warehousing provides a business with several benefits such as advanced businessintelligence and data consistency. Amazon Redshift is a fast, fully managed, cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata.
The release of intellectual property and non-public information Generative AI tools can make it easy for well-meaning users to leak sensitive and confidential data. Once shared, this data can be fed into the datalakes used to train large language models (LLMs) and can be discovered by other users.
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
This process has been scheduled to run daily, ensuring a consistent batch of fresh data for analysis. AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 datalake. You can also use features like auto-copy from Amazon S3 (feature under preview) to ingest data from Amazon S3 to Amazon Redshift.
Aimee Oz, a software development engineer at Capital Group, started in 2021 as an intern and participated in the data engineering bootcamp that was offered to all new team members. The bootcamp broadened my understanding of key concepts in data engineering. Investing in future leaders.
Most commonly, we think of data as numbers that show information such as sales figures, marketing data, payroll totals, financial statistics, and other data that can be counted and measured objectively. This is quantitative data. It’s “hard,” structureddata that answers questions such as “how many?”
Structured vs unstructured data. Structureddata is far easier for programs to understand, while unstructured data poses a greater challenge. However, both types of data play an important role in data analysis. Structureddata. Structureddata is organized in tabular format (ie.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structuredata for use, train machine learning models and develop artificial intelligence (AI) applications.
The reasons for this are simple: Before you can start analyzing data, huge datasets like datalakes must be modeled or transformed to be usable. According to a recent survey conducted by IDC , 43% of respondents were drawing intelligence from 10 to 30 data sources in 2020, with a jump to 64% in 2021! Dig into AI.
Amazon Redshift is a recommended service for online analytical processing (OLAP) workloads such as cloud data warehouses, data marts, and other analytical data stores. You can use simple SQL to analyze structured and semi-structureddata, operational databases, and datalakes to deliver the best price/performance at any scale.
Cloud-based data warehouses can also perform complex analytical queries much faster due to the use of massively parallel processing (MPP), which uses multiple processors—each with its own operating system and memory—to simultaneously perform a set of coordinated computations.
The majority of data produced by these accounts is used downstream for businessintelligence (BI) purposes and in Amazon Athena , by hundreds of business users every day. The solution Acast implemented is a data mesh, architected on AWS.
In a prior blog , we pointed out that warehouses, known for high-performance data processing for businessintelligence, can quickly become expensive for new data and evolving workloads. Similarly, the relational database has been the foundation for data warehousing for as long as data warehousing has been around.
Finally, a data catalog can help data scientists find answers to their questions (and avoid re-asking questions that have already been answered). Modern data catalogs surface a wide range of data asset types. Data scientists often have different requirements for a data catalog than data analysts.
A modern information lifecycle management approach Today’s ILM approach recognizes the enterprise value of all digitized and enriched assets , avoiding the habituated, narrow reliance ontraditional structureddata. When data is stored in a modern, accessible repository, organizations gain newfound capabilities.
If the point of BusinessIntelligence (BI) data governance is to leverage your datasets to support information transparency and decision-making, then it’s fair to say that the data catalog is key for your BI strategy. At least, as far as data analysis is concerned. The Benefits of StructuredData Catalogs.
I have since run and driven transformation in Reference Data, Master Data , KYC [3] , Customer Data, Data Warehousing and more recently DataLakes and Analytics , constantly building experience and capability in the Data Governance , Quality and data services domains, both inside banks, as a consultant and as a vendor.
Data Swamp vs DataLake. When you imagine a lake, it’s likely an idyllic image of a tree-ringed body of reflective water amid singing birds and dabbling ducks. I’ll take the lake, thank you very much. But when it’s dirty, stagnant, or hard to unleash, your business will suffer. Benefits of a DataLake.
Let’s look at the data architecture journey to understand why and how data lakehouses help to solve complexity, value and security. Traditionally, data warehouses have stored curated, structureddata to support analytics and businessintelligence, with fast, easy access to data.
Data pipelines are designed to automate the flow of data, enabling efficient and reliable data movement for various purposes, such as data analytics, reporting, or integration with other systems. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Trino has quickly emerged as one of the most formidable SQL query engines, widely recognized for its ability to connect to diverse data sources and execute complex queries with remarkable efficiency. This is particularly valuable for teams that require instant answers from their data.
This unification is perhaps best exemplified by a new offering inside Amazon SageMaker, Unified Studio , which combinesSQLanalytics, data processing, AI development, data streaming, businessintelligence, and search analytics. On the storage front, AWS unveiled S3 Table Buckets and the S3 Metadata features.
This is the final part of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. The following diagram illustrates the different layers of the datalake.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































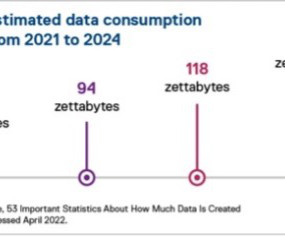












Let's personalize your content