This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
In this post, we show you how EUROGATE uses AWS services, including Amazon DataZone , to make data discoverable by data consumers across different business units so that they can innovate faster. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 2 shows this workflow.
Managing large-scale datawarehouse systems has been known to be very administrative, costly, and lead to analytic silos. The good news is that Snowflake, the cloud data platform, lowers costs and administrative overhead. The post Birst automates the creation of datawarehouses in Snowflake appeared first on Birst.
The recent announcement of the Microsoft IntelligentData Platform makes that more obvious, though analytics is only one part of that new brand. Azure Data Factory. Azure Data Lake Analytics. Datawarehouses are designed for questions you already know you want to ask about your data, again and again.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. The program manager should lead the vision for quality data and ROI. date, month, and year).
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities.
In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.
Federated queries are useful for use cases where organizations want to combine data from their operational systems with data stored in Amazon Redshift. Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines.
Given the importance of sharing information among diverse disciplines in the era of digital transformation, this concept is arguably as important as ever. The aim is to normalize, aggregate, and eventually make available to analysts across the organization data that originates in various pockets of the enterprise.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible datatransforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their datatransform logic separate from storage and engine.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Datatransformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), businessintelligence (BI), and reporting tools. All columns should masked for them.
Central to the success of this strategy is its support for each division’s autonomy and freedom to choose their own domain structure, which is closely aligned to their business needs. These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products.
For files with known structures, a Redshift stored procedure is used, which takes the file location and table name as parameters and runs a COPY command to load the raw data into corresponding Redshift tables. She helps customers architect data analytics solutions at scale on AWS.
These tools empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and analytic engines. No more lock-in, unnecessary datatransformations, or data movement across tools and clouds just to extract insights out of the data.
“Digitizing was our first stake at the table in our data journey,” he says. That step, primarily undertaken by developers and data architects, established data governance and data integration. That step, primarily undertaken by developers and data architects, established data governance and data integration.
The modern data stack is a data management system built out of cloud-based data systems. A given modern data stack will usually include components for data ingestion from your data sources, datatransformation, data storage, data analysis and reporting.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera DataWarehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ). Cloudera Data Engineering (Spark 3) with Airflow enabled. Cloudera Machine Learning .
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Extract, load, Transform (ELT) tools. Data ingestion/integration services. Data orchestration tools. Better Data Culture.
We will create a glue studio job, add events and venue data from the SFTP server, carry out datatransformations and load transformeddata to s3. Shengjie Luo is a Big data architect of Amazon Cloud Technology professional service team. Select Visual ETL in the central pane.
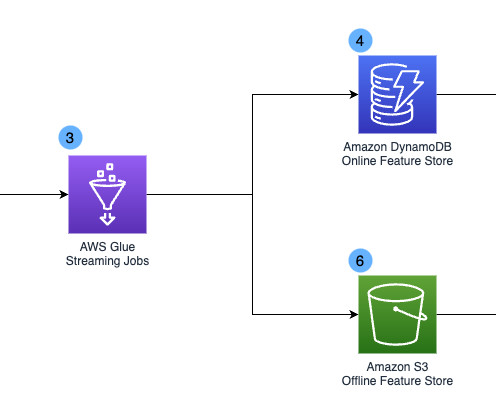
However, our legacy datawarehouse-based solution was not equipped for this challenge. It was designed to manage complex queries and businessintelligence (BI) use cases on a large scale. The AWS Glue streaming jobs generate derived fields and risk profiles that get stored in Amazon DynamoDB.
As well as keeping its current data accurate and accessible, the company wants to leverage decades of historical data to identify potential risks to ship operations and opportunities for improvement. Each of the acquired companies had multiple data sets with different primary keys, says Hepworth. “We
Here at Sisense, we think about this flow in five linear layers: Raw This is our data in its raw form within a datawarehouse. We follow an ELT ( E xtract, L oad, T ransform) practice, as opposed to ETL, in which we opt to transform the data in the warehouse in the stages that follow. Dig into AI.
The integration of Talend Cloud and Talend Stitch with Amazon Redshift Serverless can help you achieve successful business outcomes without datawarehouse infrastructure management. Prerequisites To complete the integration, you need a Redshift Serverless datawarehouse. Add a tRedshiftOutput database component.
Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other businessdata, as well as support the use of businessintelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Choose Update.
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
To fuel self-service analytics and provide the real-time information customers and internal stakeholders need to meet customers’ shipping requirements, the Richmond, VA-based company, which operates a fleet of more than 8,500 tractors and 34,000 trailers, has embarked on a datatransformation journey to improve data integration and data management.
With these features, you can now build data pipelines completely in standard SQL that are serverless, more simple to build, and able to operate at scale. Typically, datatransformation processes are used to perform this operation, and a final consistent view is stored in an S3 bucket or folder.
Attempting to learn more about the role of big data (here taken to datasets of high volume, velocity, and variety) within businessintelligence today, can sometimes create more confusion than it alleviates, as vital terms are used interchangeably instead of distinctly. displaying BI insights for human users).
How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and businessintelligence.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Amazon Redshift enables you to run complex SQL analytics at scale and performance on terabytes to petabytes of structured and unstructured data, and make the insights widely available through popular businessintelligence (BI) and analytics tools.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
From addressing implementation challenges to conducting a comparative analysis of leading options, we delve into how embedded BI tools empower organizations to make informed decisions and drive businessintelligence initiatives with unprecedented efficiency and precision. What Are Embedded BI Tools?
. Request a live demo or start a proof of concept with Amazon RDS for Db2 Db2 Warehouse SaaS on AWS The cloud-native Db2 Warehouse fulfills your price and performance objectives for mission-critical operational analytics, businessintelligence (BI) and mixed workloads.
Any time new test cases or test results are created or modified, events trigger such that processing is immediate and new snapshot files are available via an API or data is pulled at the refresh frequency of the reporting or businessintelligence (BI) tool. Fixed-size data files avoid further latency due to unbound file sizes.
Learn in 12 minutes: What makes a strong use case for data virtualisation How to come up with a solid Proof of Concept How to prepare your organisation for data virtualisation You’ll have read all about data virtualisation and you’ve.
Extract, Transform and Load (ETL) refers to a process of connecting to data sources, integrating data from various data sources, improving data quality, aggregating it and then storing it in staging data source or data marts or datawarehouses for consumption of various business applications including BI, Analytics and Reporting.
Data pipelines are designed to automate the flow of data, enabling efficient and reliable data movement for various purposes, such as data analytics, reporting, or integration with other systems. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content