


Expand data access through Apache Iceberg using Delta Lake UniForm on AWS
AWS Big Data
NOVEMBER 14, 2024
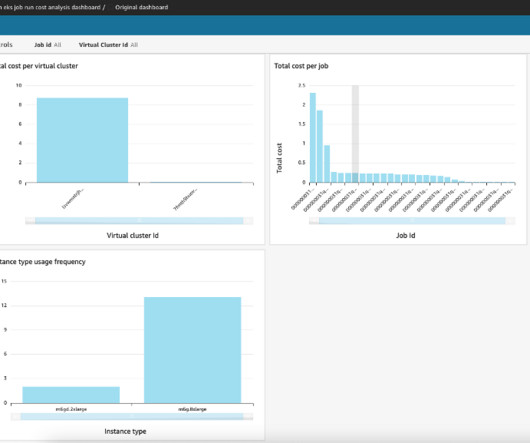
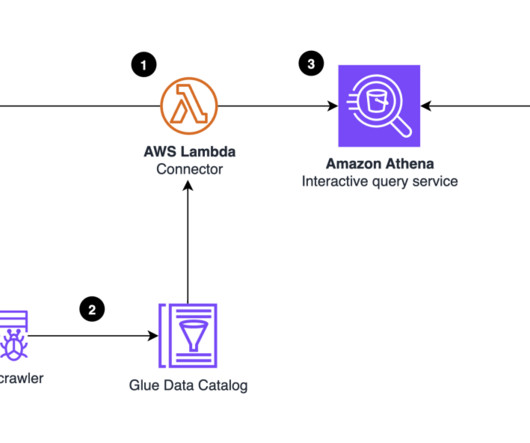
This post explores how to start using Delta Lake UniForm on Amazon Web Services (AWS). Note that the extra package ( delta-iceberg ) is required to create a UniForm table in AWS Glue Data Catalog. Amazon S3 and AWS Glue Data Catalog : These are used to manage the underlying files and the catalog of the Delta Lake UniForm table.













































Let's personalize your content