This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcing DataOps Data Quality TestGen 3.0: Open-Source, Generative Data Quality Software. It assesses your data, deploys production testing, monitors progress, and helps you build a constituency within your company for lasting change. Imagine an open-source tool thats free to download but requires minimal time and effort.
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? Over the years of working with data analytics teams in large and small companies, we have been fortunate enough to observe hundreds of companies. We want to share our observations about data teams, how they work and think, and their challenges.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern data architectures.
Innovation/Ideation/Design for UI/X: In traditional software engineering projects, product managers are key stakeholders in the activities that influence product and feature innovation. As a result, designing, implementing, and managing AI experiments (and the associated software engineering tools) is at times an AI product in itself.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. The new category is often called MLOps. The new category is often called MLOps. Why: Data Makes It Different.
I previously explained that data observability software has become a critical component of data-driven decision-making. Data observability addresses one of the most significant impediments to generating value from data by providing an environment for monitoring the quality and reliability of data on a continual basis.
In todays economy, as the saying goes, data is the new gold a valuable asset from a financial standpoint. A similar transformation has occurred with data. More than 20 years ago, data within organizations was like scattered rocks on early Earth.
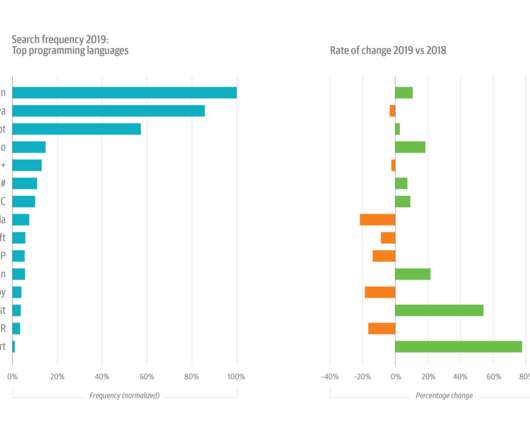
It’s also the data source for our annual usage study, which examines the most-used topics and the top search terms. [1]. This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. A drill-down into data, AI, and ML topics.
Whether it’s controlling for common risk factors—bias in model development, missing or poorly conditioned data, the tendency of models to degrade in production—or instantiating formal processes to promote data governance, adopters will have their work cut out for them as they work to establish reliable AI production lines.
Anant Agarwal, an MIT professor and of the founders of the EdX educational platform, recently created a stir by saying that prompt engineering was the most important skill you could learn. But before discussing why, it’s important to think about what prompt engineering means. And that you could learn the basics in two hours.
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. However, it also offers additional optimizations that you can use to further improve this performance and achieve even faster query response times from your data warehouse.
Outputs from trained AI models include numbers (continuous or discrete), categories or classes (e.g., When transitioning to developing a bigger AI vision and strategy, we may create a prioritized product roadmap consisting of a suite of recommendation engines and an AI-based personalized loyalty program, for example.
We suspected that data quality was a topic brimming with interest. The responses show a surfeit of concerns around data quality and some uncertainty about how best to address those concerns. Key survey results: The C-suite is engaged with data quality. Data quality might get worse before it gets better.
Broadcom and Google Clouds continued commitment to solving our customers most pressing challenges stems from our joint goal to enable every organizations ability to digitally transform through data-powered innovation with the highly secure and cyber-resilient infrastructure, platform, industry solutions and expertise.
I wrote an extensive piece on the power of graph databases, linked data, graph algorithms, and various significant graph analytics applications. You should still get the book because it is a fantastic 250-page masterpiece for data scientists!) How does one express “context” in a data model? It’s all here.
This is not surprising given that DataOps enables enterprise data teams to generate significant business value from their data. Companies that implement DataOps find that they are able to reduce cycle times from weeks (or months) to days, virtually eliminate data errors, increase collaboration, and dramatically improve productivity.
These required specialized roles and teams to collect domain-specific data, prepare features, label data, retrain and manage the entire lifecycle of a model. Companies can enrich these versatile tools with their own data using the RAG (retrieval-augmented generation) architecture. An LLM can do that too.
Quality depends not just on code, but also on data, tuning, regular updates, and retraining. Those involved with ML usually want to experiment with new libraries, algorithms, and data sources—and thus, one must be able to put those new components into production. Metadata and artifacts needed for a full audit trail.
Amazon Redshift is a fully managed, AI-powered cloud data warehouse that delivers the best price-performance for your analytics workloads at any scale. It provides a conversational interface where users can submit queries in natural language within the scope of their current data permissions. Your data is not shared across accounts.
Traditionally, financial data analysis could require deep SQL expertise and database knowledge. Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. or Give me details of all accounts for a specific customer.
Allow better quality control by analyzing data from sensors, inspecting products in real-time, and reducing overall human error in the QA process. It defines when orders need to be made to order, made to stock, or engineered to order, and includes production management and bill of materials, as well as all necessary equipment and facilities.
Third, any commitment to a disruptive technology (including data-intensive and AI implementations) must start with a business strategy. These changes may include requirements drift, data drift, model drift, or concept drift. A business-disruptive ChatGPT implementation definitely fits into this category: focus first on the MVP or MLP.
In todays data-driven world, tracking and analyzing changes over time has become essential. As organizations process vast amounts of data, maintaining an accurate historical record is crucial. History management in data systems is fundamental for compliance, business intelligence, data quality, and time-based analysis.
2024 Gartner Market Guide To DataOps We at DataKitchen are thrilled to see the publication of the Gartner Market Guide to DataOps, a milestone in the evolution of this critical software category. At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data.
Machine learning solutions for data integration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. The problem is even more magnified in the case of structured enterprise data.
Enterprise data is brought into data lakes and data warehouses to carry out analytical, reporting, and data science use cases using AWS analytical services like Amazon Athena , Amazon Redshift , Amazon EMR , and so on. This function hard codes the model’s parameters and model ID for demonstrating the basic functionality.
In June 2021, we asked the recipients of our Data & AI Newsletter to respond to a survey about compensation. The average salary for data and AI professionals who responded to the survey was $146,000. We didn’t use the data from these respondents; in practice, discarding this data had no effect on the results.
The hope is to have shared guidelines and harmonized rules: few rules, clear and forward-looking, says Marco Valentini, group public affairs director at Engineering, an Italian company that is a member of the AI Pact. We hope to work closely with the AI Office to achieve these goals.
1) What Is Data Interpretation? 2) How To Interpret Data? 3) Why Data Interpretation Is Important? 4) Data Analysis & Interpretation Problems. 5) Data Interpretation Techniques & Methods. 6) The Use of Dashboards For Data Interpretation. Business dashboards are the digital age tools for big data.
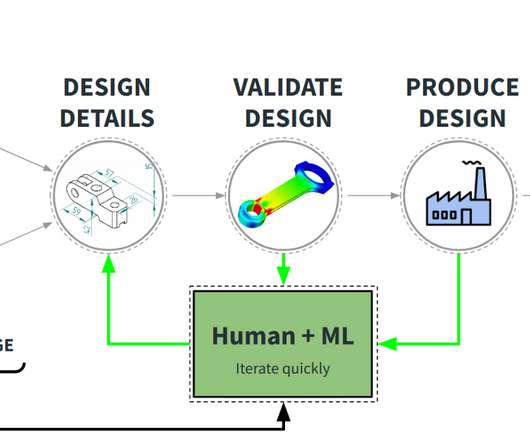
Designers' and engineers' creativity in exploring and developing the design space is limited by how fast they can iterate and generate new designs. The annotations were effectively a tree of parts, categories, and subparts which can easily lead to unnaturally formulaic descriptions that are specific, but too cryptic to be useful.
These opportunities fall under the umbrella category of climate technology and involve full-time careers, part-time jobs, and volunteer opportunities. In especially high demand are IT pros with software development, data science and machine learning skills.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
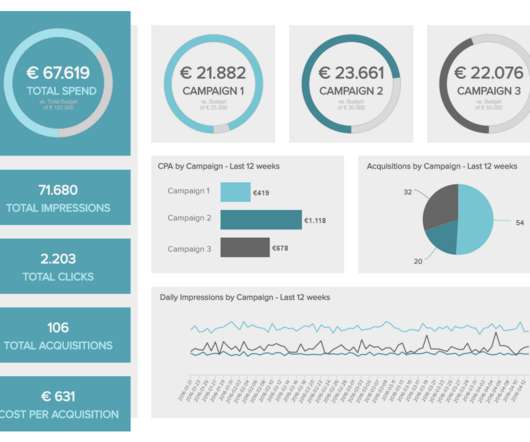
Today’s digital data has given the power to an average Internet user a massive amount of information that helps him or her to choose between brands, products or offers, making the market a highly competitive arena for the best ones to survive. First things first – organizing and prioritizing your marketing data.
As a technology company you can imagine how easy it is to think of data-first modernization as a technology challenge. Data fabric, data cleansing and tagging, data models, containers, inference at the edge – cloud-enabled platforms are all “go-to” conversation points. and “how to do it?” and “how to do it?”,
eCommerce AI is a data-driven trend that allows companies to manage and analyze consumer information easily. This data can also be used to identify shopper segmentation parameters. These eCommerce search engines are able to think the way humans do. Artificial intelligence is improving customer search engines on eCommerce sites.
Analyzing the hiring behaviors of companies on its platform, freelance work marketplace Upwork has AI to be the fastest growing category for 2023, noting that posts for generative AI jobs increased more than 1000% in Q2 2023 compared to the end of 2022, and that related searches for AI saw a more than 1500% increase during the same time.
The partners say they will create the future of digital manufacturing by leveraging the industrial internet of things (IIoT), digital twin , data, and AI to bring products to consumers faster and increase customer satisfaction, all while improving productivity and reducing costs. Data and AI as digital fundamentals.
In a related post we discussed the Cold Start Problem in Data Science — how do you start to build a model when you have either no training data or no clear choice of model parameters. The above example (clustering) is taken from unsupervised machine learning (where there are no labels on the training data).
Data architect role Data architects are senior visionaries who translate business requirements into technology requirements and define data standards and principles, often in support of data or digital transformations. Data architects are frequently part of a data science team and tasked with leading data system projects.
The Syntax, Semantics, and Pragmatics Gap in Data Quality Validate Testing Data Teams often have too many things on their ‘to-do’ list. They have a backlog full of new customer features or data requests, and they go to work every day knowing that they won’t and can’t meet customer expectations.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned data warehouse. For more information, refer to Amazon Redshift clusters.
Decision support systems definition A decision support system (DSS) is an interactive information system that analyzes large volumes of data for informing business decisions. A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. Data-driven DSS.
But it could also draw on the detailed information SAP’s enterprise applications hold about orders and inventory, for instance, to identify which products to promote or help field service engineers optimize repairs, said Ritu Bhargava, SAP’s chief product officer for industries and customer experience. It’s not a reactive chatbot,” she said.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content