This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
select mv_name, status, start_time, end_time from SYS_MV_REFRESH_HISTORY where mv_name='customer_mv' order by start_time DESC; Retrieve the current number of rows present in the materialized view customer_mv. It should now have one record as present in the customer.tbl.2 category"; Create a materialized view using the external schema.
The idea that presents itself is having this kind of catalog of the actions that can be done, and having an AI that is intelligent enough,” he says. For example, a bank customer will be able to say, “Take money from my account that has the most money in it and move it to my checking account.”
In our recent report examining technical debt in the age of generative AI , we explored how companies need to break their technical debt down into four categories. Breaking it down into these categories also shows the impact on the business in a way that every board member will understand.
However, managing schema evolution at scale presents significant challenges. This new iteration adds a text-based classification capability through a 'category' field (string type) to the sentiment structure. Building on the schema evolution example, we now introduce a third enhancement to the sensor data structure.
Dimension-Focused Dashboards Bergh described these dashboards as providing a broad overview of data quality across standard categories, facilitating consistent evaluations. Each type serves a unique role in driving changes in data quality. By focusing on their needs, data consumers can become allies in driving data quality improvements.
The AWS solution we present here, in addition to these data assets, will import AWS projects and will link them to the assets ingested here that are published in these projects. Some business terms are also linked to data categories that are associated with data privacy, regulatory policies, and standards.
Binary quantization Byte quantization FP16 quantization Product quantization These techniques fall within the broader category of scalar and product quantization that we discussed earlier. This value presents a critical trade-off between accuracy and search efficiency.
. # Step 1: Preparing and Exporting Excel Spreadsheets Lets consider a quarterly business report with data on sales, expenses, profit, and customer satisfaction scores across different regions and product categories. NotebookLM first provides detailed calculations and then presents the final answer.
Cyber resilience has become a top-of-mind priority for our customers, as the data shows that it presents a challenge most today are ill-equipped to address. With our longstanding technology and go-to-market partnership, we are yet again innovating to deliver value in the space of cyber and disaster recovery.
Results Here you can find the tables that present cost, speed, and quality evaluation for different prompts on AIDA and BioRED. The experiments were run five times to account for the non-deterministic nature of LLM outputs, and the averaged results are presented below. We benchmarked GPT-4o 3 and Llama-3.1-70b-Instruct sec Llama 87.4
Coverage: Automated Consistency Testing Comprehensive test coverage encompasses multiple categories of validation, each addressing specific aspects of data quality. Modern data environments typically include 50 or more tools across various categories, each requiring monitoring for errors, performance issues, and timing problems.
no blank cells or mixed formats) Use data validation to create dropdowns for categories or statuses Include a timestamp column if you plan to track trends over time # 2. Bar and Column Charts Bar and column charts are the best option to compare values across different categories. One for the category axis (Product Category).
Traditionally, such an application might have used a specially trained ML model to classify uploaded receipts into accounting categories, such as DATEV. In-depth analysis: LLMs can go beyond simple data presentation to identify and explain complex patterns in the data.
Run the following queries in sequence (provide your S3 bucket name): -- Create database for the demo CREATE DATABASE glue5_fta_demo; -- Create external table in input CSV files. The main IAM permission to verify is that the AWS Glue job execution role has lakeformation:GetDataAccess. Modify the Spark session configurations in the script.
They pointed out that, while AI wasnt generally a keyword in job descriptions before 2022 , many skills required for AI have already been present in jobs such as IT, data science, and computer engineering.
The next section reviews features in Amazon Redshift that help improve query performance on data lakes even when table statistics aren’t present or are limited. In the following example, you want to find the total sales amount for products in the Electronics category in December 2024.
Common LLM benchmarks by category The world of LLM benchmarks is constantly evolving. Some well-known benchmarks are presented below: Reasoning and language comprehension MMLU (Massive Multitask Language Understanding) : This benchmark tests a models breadth of knowledge across 57 academic and professional disciplines.
From there, you can break your list into categories that make email writing more focused. Imperfect sentence #1) Integrating email capture best practices within segmentation strategies converts casual visitors into subscribers by presenting optimized sign-up forms and compelling lead magnets.
Whether you’re a developer new to search or looking to understand OpenSearch fundamentals, this hands-on post shows you how to build a search application from scratch—starting with the initial setup; diving into core components such as indexing, querying, result presentation; and culminating in the execution of your first search query.
This article presents ideas in four categories focusing on a reliability culture, the deploy trade-off, resilient teams, and sustaining progress. I want to share something important (while keeping the underlying meaning unchanged) that you should find useful wherever your softwares stability and performance is essential.
Guided by this philosophy, the company merged its previously separate online and offline MD teams into a unified organization and restructured them by product category. To do so, he asked internal engineers to rehearse explaining their work in plain language before presenting it to non-technical teams.
There are several consistent patterns Ive observed across transformation programs, and they often fall into one of four categories: data quality, data silos, governance gaps and cloud cost sprawl. Whats holding us back? Each one on its own can derail momentum. Together, they become insurmountableunless addressed head-on.
An enterprise may have a wide variety of user-facing, general-purpose purpose or specialized agents versus specialized agents, even leading up to the next category of developer-facing agents as a service. AI agents introduce even more complex layers of interaction and coordination. a complexity tradeoff).
They tend to cluster into four categories. Executives communicate data needs and ideas in natural language text in emails, conversations and presentations. To each his/her own To understand why, we need to take a closer look at the different groups who work with data in the enterprise.
For example, when asking for the visualization of product ratings and revenue from product sales, a user might be presented with a bubble chart where the bubbles are proportional to a third dimension of data. To avoid cluttering their analysis, they might remove that dimension to zero in on the two-dimensional relationship they are exploring.
This paper presents a bold re-architecture of the Spotify model through the lenses of composite teams, liquid workflows, cognitive meshes and agentic governance. Category managers test and localize strategies, feeding results back into the mesh. Have them present learnings at guilds, all-hands and onboarding.
Shed present these to the engineering team, who would then translate her expertise into prompts. While these dimensions will vary based on your specific needs, I find it helpful to think about three broad categories: Features: What capabilities does your AI need to support? But heres the thing: Prompts are just English.
But were still looking for more reports from the trenches, presented as five-minute lightning talks (a format Nat Torkington originally developed for our Perl Conference nearly 30 years ago, and that was a beloved feature of all our conferences thereafter). You can find more information and our call for presentations here.
While most customers still rely on filters and categories today, there is a clear shift underway — toward discovery driven by questions, needs and intent-based prompts. From AI-driven recommendations to dynamic bundles and replenishment nudges, we’re already seeing the building blocks of agentic commerce emerge across categories.
Depending on the stage of development of the AI model, the data used falls into one of three categories: training data, test data and validation data. At present, AI companies source their data in multiple ways. The patterns and interdependencies that machine learning (ML) algorithms identify and apply form the basis of their use case.
You can find more information and our call for presentations here. What categories of errors are we seeing? If youre in the trenches building tomorrows development practices today and interested in speaking at the event, wed love to hear from you by March 5. Does the AI have the proper context to help users? How is this being measured?
Rapid artificial intelligence (AI) growth among enterprises is driving the next phase of digital transformation, with the technology presenting unprecedented business opportunities. This enthusiasm has seen applications grow tenfold due to AI-powered cloud migration, with over 80 percent of services now on the cloud.
They explicitly model different AI categories (e.g., During the summit, industry executives and practitioners addressed and presented case studies on the following: FinOps and TBM: FinOps and TBM have complementary strengths. agentic, prescriptive, and predictive), based on practical input and practices from global TBM Council members.
From marketing, to operations, to sales, and everything in between, dashboards present users with a simple, succinct view, allowing them to explore, analyze, monitor and act on their data. Retail Sales Performance Dashboard The Retail Sales Performance Dashboard highlights sales trends, targets, and KPIs in a visually engaging format.
Gone are the days of static presentations, stagnate reports, and waiting on analysts to pull reports and then having out-of-date data. While Excel and PowerPoint, and various other spreadsheet and presentation applications, remain important business tools for many, their interactivity options are limited. 8) Advanced Data Options.
Will dashboard be viewed on-the-go, in silence at the office desk or will it be displayed as a presentation in front of a large audience? If your dashboard will be displayed as a presentation or printed, make sure it’s possible to contain all key information within one page. The modern dashboard is minimalist and clean.
The annual awards , presented by IDC and Brightstar with support from CIO New Zealand, celebrate individuals and teams showing exceptional leadership, innovation, and foresight in their contributions to ICT and business. This years program features both established categories and new additions.
However, today’s business world still lacks a way to present market-based research results in an efficient manner – the static, antiquated nature of PowerPoint makes it a bad choice in the matter, yet it is still widely used to present results. How To Present Your Results: 3 Market Research Example Dashboards. c) Brand image.
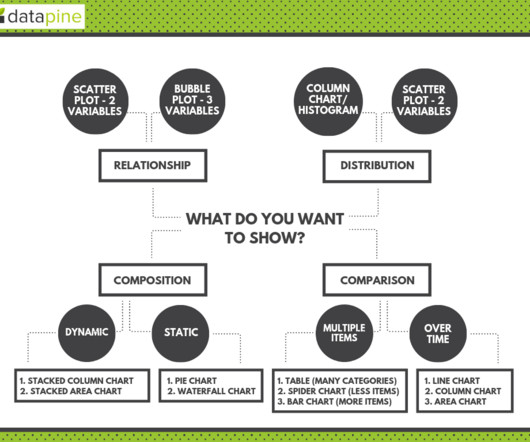
2) Charts And Graphs Categories 3) 20 Different Types Of Graphs And Charts 4) How To Choose The Right Chart Type Data and statistics are all around us. Below we will discuss the graph and chart categories. These categories will build a solid foundation that will help you pick the right visual for your analytical aims.
In this post, we will examine ways that your organization can separate useful content into separate categories that amplify your own staff’s performance. Do you present your employees with a present for their innovative ideas? Before we start, I have a few questions for you. Can you find them all?
If critical data is present, the automated orchestration executes the builds. A report titled “Daily Build Summary” presents the status of analytics builds that instantiate data and analytics for users, such as, for example, data mart schemas employed by users for self-service analytics. Any one of these sources could have a problem.
While there are several different types of processes that are implemented based on individual data nature, the two broadest and most common categories are “quantitative analysis” and “qualitative analysis”. The varying scales include: Nominal Scale: non-numeric categories that cannot be ranked or compared quantitatively.
Digital data not only provides astute insights into critical elements of your business but if presented in an inspiring, digestible, and logical format, it can tell a tale that everyone within the organization can get behind. Data visualization methods refer to the creation of graphical representations of information. Set Your Goals.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content