This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Imagine a filing cabinet for data, with drawers for different categories of information. The “CREATE TABLE” statement in SQL is like building a new drawer in that cabinet. SQL also lets you copy […] The post Guide to SQL CREATE TABLE Statement and Table Operations appeared first on Analytics Vidhya.
Amazon Q generative SQL brings the capabilities of generative AI directly into the Amazon Redshift query editor. Amazon Q generative SQL for Amazon Redshift was launched in preview during AWS re:Invent 2023. You receive the generated SQL code suggestions within the same chat interface.
These data processing and analytical services support Structured Query Language (SQL) to interact with the data. Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values.
Accelerating SQL code migration from Google BigQuery to Amazon Redshift can be a complex and time-consuming task. This post explores how you can use BladeBridge , a leading data environment modernization solution, to simplify and accelerate the migration of SQL code from BigQuery to Amazon Redshift.
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Sign in to the AWS Management Console , go to Amazon Athena , and execute the following SQL to create a database in an AWS Glue catalog. SELECT * FROM "dev"."iceberg_schema"."category";
Traditionally, financial data analysis could require deep SQL expertise and database knowledge. Amazon Bedrock Knowledge Bases automatically translates these natural language queries into optimized SQL statements, thereby accelerating time to insight, enabling faster discoveries and efficient decision-making.
They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML. Just because the work is data-centric or SQL-heavy does not warrant a free pass. Finally, it is important to emphasize the Engineering aspect of this pillar.
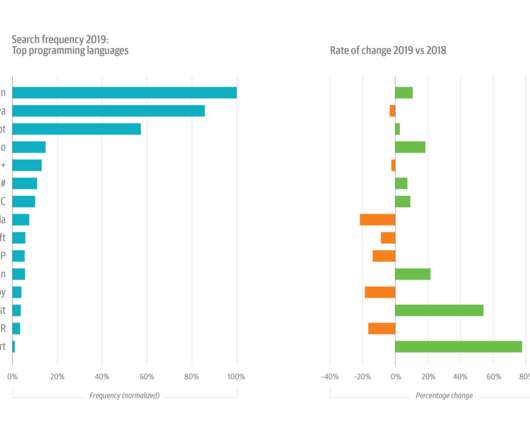
When we looked at the most popular programming languages for data and AI practitioners, we didn’t see any surprises: Python was dominant (61%), followed by SQL (54%), JavaScript (32%), HTML (29%), Bash (29%), Java (24%), and R (20%). The tools category includes tools for building and maintaining data pipelines, like Kafka.
To interact with and analyze data stored in Amazon Redshift, AWS provides the Amazon Redshift Query Editor V2 , a web-based tool that allows you to explore, analyze, and share data using SQL. The Query Editor V2 offers a user-friendly interface for connecting to your Redshift clusters, executing queries, and visualizing results.
This example shows additional information for the net profit: the top 5 product categories by using a drill-through. Sometimes referred to as nested charts, they are especially useful in tables, where you can access additional drilldown options such as aggregated data for categories/breakdowns (e.g. 8) Advanced Data Options.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL, business intelligence (BI), and reporting tools. Wait a few seconds and run the following SQL query to see integration in action.
Because it is such a new category, both overly narrow and overly broad definitions of DataOps abound. Redgate — SQL tools to help users implement DataOps, monitor database performance, and provision of new databases. . To date, we count over 100 companies in the DataOps ecosystem. Sandbox Creation and Management.
Starting with data engineering, the backbone of all data work (the category includes titles covering data management, i.e., relational databases, Spark, Hadoop, SQL, NoSQL, etc.). This slowdown suggests that cloud as a category has achieved such a large share that (mathematically) any additional growth must occur at a slower rate.
The groups for the illustration can be broadly classified into the following categories: Regional sales managers will be granted access to view sales data only for the specific country or region they manage. Args: sql (str): The SQL query to execute. redshift_client (boto3.client): client): The Redshift Data API client.
NoSQL databases are the alternative to SQL databases. A “NoSQL database” is an umbrella term that covers all types of non-relational databases – that is, all non SQL databases, as the name suggests. While SQL databases store data in rigid relational tables, NoSQL databases provide more flexibility. Ease of use. Fast queries.
The bar chart below shows the sales of each category of products, and the line chart above shows the annual sales of a certain category of products. In the upper right corner of the dashboard is a word cloud diagram showing the categories of Christmas gifts people most want. We can also customize the style of the flow lines.
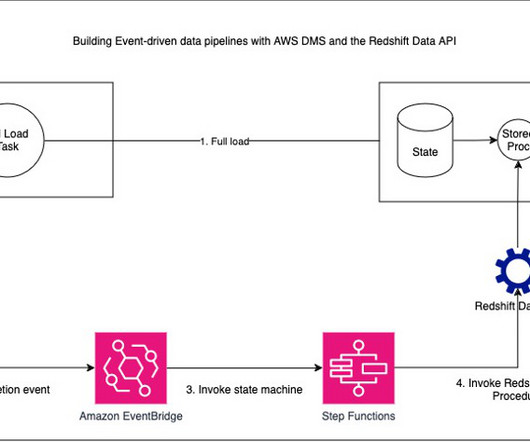
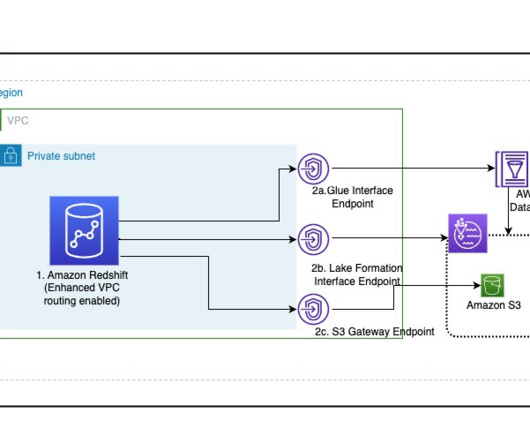
Solution overview To explain this setup, we present the following architecture, which integrates Amazon S3 for the data lake (Iceberg table format), Lake Formation for access control, AWS Glue for ETL (extract, transform, and load), and Athena for querying the latest inventory data from the Iceberg tables using standard SQL.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
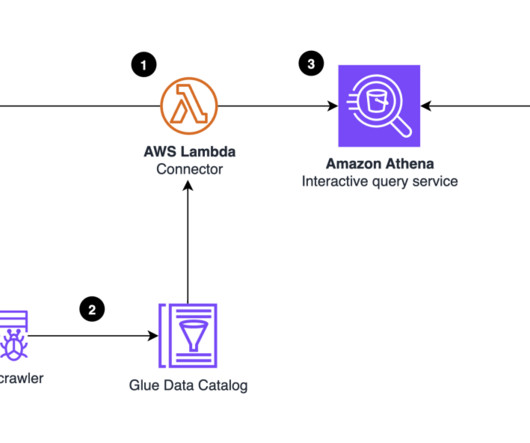
Its generative BI capabilities enable you to ask questions about your data using natural language, without having to write SQL queries or learn a BI tool. This post shows how you can use the Athena DynamoDB connector to easily query data in DynamoDB with SQL and visualize insights in QuickSight. Choose Next.
Apache Iceberg overview Iceberg is an open-source table format that brings the power of SQL tables to big data files. It enables ACID transactions on tables, allowing for concurrent data ingestion, updates, and queries, all while using familiar SQL.
Three Different Analysts Data analysis as a whole is a very broad concept which can and should be broken down into three separate, more specific categories : Data Scientist, Data Engineer, and Data Analyst. Before moving into the hiring process though, it would be helpful to narrow down what type of data your business is managing.
Amazon Redshift Spectrum enables you to run Amazon Redshift SQL queries on data stored in Amazon S3. For Service category , select AWS services. For Service category , select AWS services. For Service category , select AWS services. Redshift Spectrum uses the AWS Glue Data Catalog as a Hive metastore. Congratulations!
It is considered a “complex to license and expensive tool” that often overlaps with other products in this category. AWS Data Pipeline : AWS Data Pipeline can be used to schedule regular processing activities such as SQL transforms, custom scripts, MapReduce applications, and distributed data copy. Conclusion.
Next, the function will summarize recommendations by each provisioned cluster (for all clusters in the account or a single cluster, depending on your settings) based on the impact on performance and cost as HIGH, MEDIUM, and LOW categories. SQL commands are included as part of the Advisor’s recommended action.
Octopai has recently expanded its offerings by introducing unique and comprehensive DAX (Data Analysis Expressions) coverage support for Power BI, SSRS (SQL Server Reporting Services), and Tabular Analysis Services.
Key categories of tools and a few examples include: Data Sources. SQL based) to big data stores (e.g. Languages are typically broken into two categories, commercial and open source. Some are very specialized and others are much more of a “swiss army knife” type that can perform a wide variety of functions. Snowflake ).
The funnel shows the total amount of users, leads, MQL, SQL, and customers, compared to the previous period and in relation to the set goal. On the right side of this marketing report format, you can dig deeper into relevant costs: per lead, per MQL, SQL and customer as well as total costs and net income of each metric.
The result is an emerging paradigm shift in how enterprises surface insights, one that sees them leaning on a new category of technology architected to help organizations maximize the value of their data. Moonfare selected Dremio in a proof-of-concept runoff with AWS Athena, an interactive query service that enables SQL queries on S3 data.
It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. spark.sql.extensions – Adds support to Iceberg Spark SQL extensions, which allows you to run Iceberg Spark procedures and some Iceberg-only SQL commands (you use this in a later step).
As another example, if your sales went up by 10%, Sisense might explain that the increase was attributable to both a specific product category and a certain age group of customer with a visual display of the breakdown. For every query, Sisense translates live widget information into SQL data.
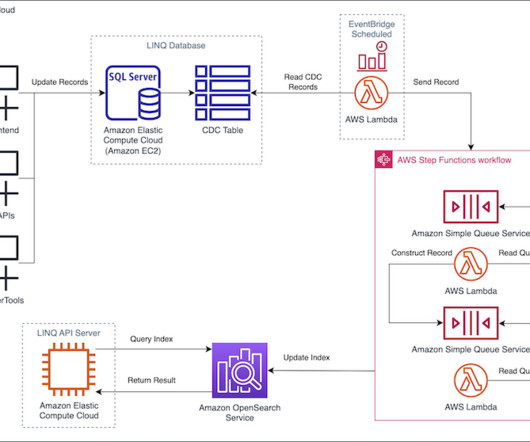
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. For example, let’s explore a use case of a refrigerator listed in the SQL Server database.
Purchasing analysis is usually represented as dashboards, reports, and data graphs, analyzing the company’s spending on suppliers by category or location. The following example contains the profit and category contribution rate, the sales, and directs for the next stage of the procurement plan. Purchasing Reports Samples.
Flink SQL is a data processing language that enables rapid prototyping and development of event-driven and streaming applications. Flink SQL combines the performance and scalability of Apache Flink, a popular distributed streaming platform, with the simplicity and accessibility of SQL. You can view the code here.
Visualize all the services you use Power BI has hundreds of content packs, templates, and integrations for hundreds of data services, apps, and services — and not just Microsoft ones such as Dynamics 365 and SQL Server. You can also create manual metrics to update yourself.
Then we can write the SQL statement. Here we use SQL statements to create 3 datasets that indicate the sales performance from different perspectives. (In Define Category using year and Series using total_sales : Category in line charts can be seen as each label along the x-axis. Click the button + to add a new dataset.
In these problems, we attempt to predict whether an object or an event belongs to a certain category. In this post, we will build a sentiment analyzer using Python after preparing text data using SQL. This is best done using SQL, the most popular language for data analysts. Let’s get started. The ML Learning Process.
Let’s add the partition field category to the Iceberg table using the AWS Glue ETL job icebergdemo1-GlueETL2-partition-evolution : ALTER TABLE glue_catalog.icebergdb1.ecomorders ecomorders ADD PARTITION FIELD category ; On the AWS Glue console, run the ETL job icebergdemo1-GlueETL2-partition-evolution. DESCRIBE icebergdb1.ecomorders
dbt enables you to write SQL select statements, and then it manages turning these select statements into tables or views in Amazon Redshift. dbt’s SQL-based framework made it straightforward to learn and allowed the existing development team to scale up quickly.
The model should be able to showcase to LOBs their categories and capabilities. In the following sample data model, each business LOB has several business categories and capabilities, and each capability can be mapped to multiple APIs. The following screenshot visualizes LOBs, category, and capabilities.
While we’re widely credited with driving the creation of the data catalog category 1 , Alation isn’t just a data catalog company. Today, we are also leaders in data governance , data lineage , and data operations – all of which are part of a broader category that IDC and others call “data intelligence.” Visibility is essential.
Users only need to include the respective path in the SQL query to get to work. In addition to supporting standard SQL, Apache Drill lets you keep depending on business intelligence tools you may already use, such as Qlik and Tableau. It allows secure and interactive SQL analytics at the petabyte scale.
We use the following services: Amazon Redshift is a cloud data warehousing service that uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and machine learning (ML) to deliver the best price/performance at any scale.
So, whether you’ve been using Excel, SQL, CRMs, or other platforms to keep track of your data, this new technology will make accessing and configuring your data simpler. Here’s a list of contextual value examples a dimensional table may include: Products (product category, features, etc.)
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content