This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. Delete the bucket.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
A modern data architecture is an evolutionary architecture pattern designed to integrate a datalake, data warehouse, and purpose-built stores with a unified governance model. The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. Refer to Catalogs for more information.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making. CDP Private Cloud’s new approach to data management and analytics would allow HBL to access powerful self-service analytics.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. sql_path SQL file name.
By 2025, it’s estimated we’ll have 463 million terabytes of data created every day,” says Lisa Thee, data for good sector lead at Launch Consulting Group in Seattle. But what they really need to do is fundamentally rethink how data is managed and accessed,” he says. And key to this is the metadata management.”
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
The client had recently engaged with a well-known consulting company that had recommended a large data catalog effort to collect all enterprise metadata to help identify all data and business issues. Modern data (and analytics) governance does not necessarily need: Wall-to-wall discovery of your data and metadata.
Cloudera Data Warehouse is a highly scalable service that marries the SQL engine technologies of Apache Impala and Apache Hive with cloud-native features to deliver best-in-class price-performance for users running data warehousing workloads in the cloud. The benchmark run by McKnight Consulting Group used the Impala engine.
HR&A Advisors —a multi-disciplinary consultancy with extensive work in the broadband and digital equity space is helping its state, county, and municipal clients deliver affordable internet access by analyzing locally specific digital inclusion needs and building tailored digital equity plans.
Data curation is important in today’s world of data sharing and self-service analytics, but I think it is a frequently misused term. When speaking and consulting, I often hear people refer to data in their datalakes and data warehouses as curated data, believing that it is curated because it is stored as shareable data.
Optimized for all data, analytics and AI workloads, watsonx.data combines the flexibility of a datalake with the performance of a data warehouse, helping businesses to scale data analytics and AI anywhere their data resides. Put AI to work in your business with IBM today IBM is infusing watsonx.ai
Tagging Consider tagging your Amazon Redshift resources to quickly identify which clusters and snapshots contain the PII data, the owners, the data retention policy, and so on. Tags provide metadata about resources at a glance. Refer to AWS Lake Formation-managed Redshift shares for more details on the implementation.
Streaming jobs constantly ingest new data to synchronize across systems and can perform enrichment, transformations, joins, and aggregations across windows of time more efficiently. With a file system sink connector, Apache Flink jobs can deliver data to Amazon S3 in open format (such as JSON, Avro, Parquet, and more) files as data objects.
Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. We chatted about industry trends, why decentralization has become a hot topic in the data world, and how metadata drives many data-centric use cases.
In this episode of the AI to Impact Podcast, host Pavan Kumar speaks to Prinkan Pal about the evolution of data engineering and ML-operations from a closed team into a tech consulting unit. My team primarily comprises data engineers, ML-engineers, full-stack developers and solution architects primarily focusing towards cloud.
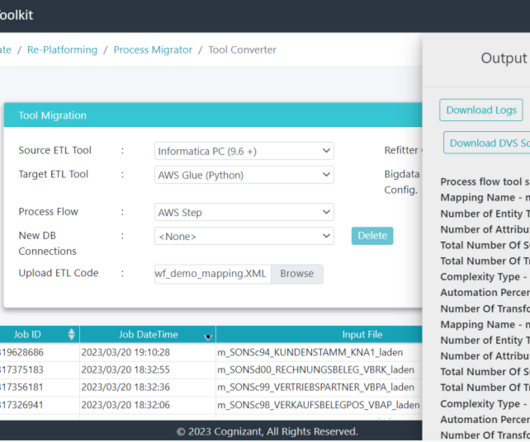
Cognizant Data & Intelligence Toolkit (CDIT) – ETL Conversion Tool automates this process, bringing in more predictability and accuracy, eliminating the risk associated with manual conversion, and providing faster time to market for customers. Cognizant is an AWS Premier Tier Services Partner with several AWS Competencies.
Download the SAML metadata file. In the navigation pane under Clients , import the SAML metadata file. Download the Keycloak IdP SAML metadata file from that URL location. For Metadata document , upload the Keycloak IdP SAML metadata XML file you downloaded and saved to your local machine earlier. Choose Browse.
This involves unifying and sharing a single copy of data and metadata across IBM® watsonx.data ™, IBM® Db2 ®, IBM® Db2® Warehouse and IBM® Netezza ®, using native integrations and supporting open formats, all without the need for migration or recataloging.
Gartner defines data profiling as: A technology for discovering and investigating data quality issues, such as duplication, lack of consistency, and lack of accuracy and completeness. The tools provide data statistics, such as degree of duplication and ratios of attribute values, both in tabular and graphical formats.
In the era of data, organizations are increasingly using datalakes to store and analyze vast amounts of structured and unstructured data. Datalakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making.
But refreshing this analysis with the latest data was impossible… unless you were proficient in SQL or Python. We wanted to make it easy for anyone to pull data and self service without the technical know-how of the underlying database or datalake. Sathish and I met in 2004 when we were working for Oracle.
To develop your disaster recovery plan, you should complete the following tasks: Define your recovery objectives for downtime and data loss (RTO and RPO) for data and metadata. For additional information on how to configure data sharing, refer to Sharing datashares.
Rich metadata and semantic modeling continue to drive the matching of 50K training materials to specific curricula, leading new, data-driven, audience-based marketing efforts that demonstrate how the recommender service is achieving increased engagement and performance from over 2.3 million users.
I have since run and driven transformation in Reference Data, Master Data , KYC [3] , Customer Data, Data Warehousing and more recently DataLakes and Analytics , constantly building experience and capability in the Data Governance , Quality and data services domains, both inside banks, as a consultant and as a vendor.
This is because you will know what data you can trust, and you will have processes to create and upkeep data, as well as curated metadata to exploit data’s full capabilities. Can you differentiate between governance of raw data and enhanced data (information)? Where do you govern? Here’s an example.
I mention this here because there was a lot of overlap between current industry data governance needs and what the scientific community is working toward for scholarly infrastructure. The gist is, leveraging metadata about research datasets, projects, publications, etc., Nothing Spreads Like Fear”.
In this example, the analytics tool accesses the datalake on Amazon Simple Storage Service (Amazon S3) through Athena queries. As the data mesh pattern expands across domains covering more downstream services, we need a mechanism to keep IdPs and IAM role trusts continuously updated.
As with any good consulting response, “it depends.” Do you recommend a consulting approach strategy rather than a CDO strategy? Does Data warehouse as a software tool will play role in future of Data & Analytics strategy? Datalakes don’t offer this nor should they. It really does.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Data governance involves establishing clear ownership and accountability for data, including defining roles, responsibilities, and decision-making authority related to data management. A mechanism to handle the custom authorization flow when a consumer triggers the subscription grant to an environment.
However, a closer look reveals that these systems are far more than simple repositories: Data catalogs are at the forefront of bringing AI into your business for at least two reasons. However, lineage information and comprehensive metadata are also crucial to document and assess AI models holistically in the domain of AI governance.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content