This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ZS is a management consulting and technology firm focused on transforming global healthcare. We developed and host several applications for our customers on Amazon Web Services (AWS). We developed and host several applications for our customers on Amazon Web Services (AWS). We’re using different models for different use cases.
Create an Amazon Route 53 public hosted zone such as mydomain.com to be used for routing internet traffic to your domain. For instructions, refer to Creating a public hosted zone. Request an AWS Certificate Manager (ACM) public certificate for the hosted zone. hosted_zone_id – The Route 53 public hosted zone ID.
Blutech Consulting was selected both by HBL and Cloudera as the implementation partner based on their in-depth technical expertise in the field of data. . Cloudera’s CDP is the only solution that can address the system, hosting, integration and security, enabling us to deploy quickly and easily with minimal impact to operations.”
The host is Tobias Macey, an engineer with many years of experience. The particular episode we recommend looks at how WeWork struggled with understanding their data lineage so they created a metadata repository to increase visibility. Currently, he is in charge of the Technical Operations team at MIT Open Learning. Agile Data.
This means the creation of reusable data services, machine-readable semantic metadata and APIs that ensure the integration and orchestration of data across the organization and with third-party external data. This means having the ability to define and relate all types of metadata. Clarify your business and expert requirements.
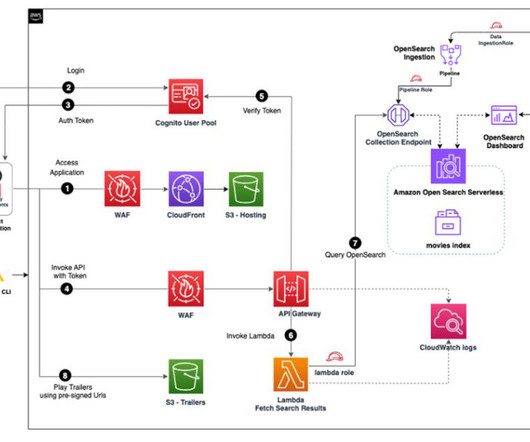
The workflow includes the following steps: The end-user accesses the CloudFront and Amazon S3 hosted movie search web application from their browser or mobile device. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
Priority 2 logs, such as operating system security logs, firewall, identity provider (IdP), email metadata, and AWS CloudTrail , are ingested into Amazon OpenSearch Service to enable the following capabilities. Previously, P2 logs were ingested into the SIEM. She loves traveling and visiting art galleries.
At a high level, the core of Langley’s architecture is based on a set of Amazon Simple Queue Service (Amazon SQS) queues and AWS Lambda functions, and a dedicated RDS database to store ETL job data and metadata. Web UI Amazon MWAA comes with a managed web server that hosts the Airflow UI.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
These include national strategies, agendas and plans; AI coordination or monitoring bodies; public consultations of stakeholders or experts; and initiatives for the use of AI in the public sector. Step 2: Have the government agency that is establishing the policy act as judge for the event.
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. Select hosts for Active and Passive KTS servers. Data in the file is encrypted with DEK.
erwin also provides data governance, metadata management and data lineage software called erwin Data Intelligence by Quest. It requires discipline, and information in the form of metadata about those being governed so that remedial action can be taken to hold people to account and ensure policies are being followed.
The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. With unified metadata, both data processing and data consuming applications can access the tables using the same metadata. For metadata read/write, Flink has the catalog interface.
In this episode of the AI to Impact Podcast, host Pavan Kumar speaks to Prinkan Pal about the evolution of data engineering and ML-operations from a closed team into a tech consulting unit. I’m your host – Pawan Kumar. We do both, you know, technology consulting and execution.
After the data lands in Amazon S3, smava uses the AWS Glue Data Catalog and crawlers to automatically catalog the available data, capture the metadata, and provide an interface that allows querying all data assets. Evolution of the data platform requirements smava started with a single Redshift cluster to host all three data stages.
To develop your disaster recovery plan, you should complete the following tasks: Define your recovery objectives for downtime and data loss (RTO and RPO) for data and metadata. Choose your hosted zone. On the Route 53 console, choose Hosted zones in the navigation pane. Choose your hosted zone. redshift.amazonaws.com.
By using infrastructure as code (IaC) tools, ODP enables self-service data access with unified data management, metadata management (data catalog), and standard interfaces for analytics tools with a high degree of automation by providing the infrastructure, integrations, and compliance measures out of the box.
The first type is metadata from images. The training of the image processing algorithms requires massive computing power, which will be provided by the exascale computer hosted on one of the most energy-efficient data centers – SurfSara, in Amsterdam. But your doctor will definitely have a richly interlinked archive to consult.
This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders. He’ll share how “metadata normalization” played a key role in the journey to automation, the steps required to automate data governance processes, and why a data catalog was critical to the project’s success.
Download the SAML metadata file. In the navigation pane under Clients , import the SAML metadata file. Insert your specific host domain name where the Keycloak application resides in the following URL: [link] /realms/aws-realm/protocol/saml/descriptor. Download the Keycloak IdP SAML metadata file from that URL location.
This multi-brand online retailer hosts thousands of products for sale on the internet and collects millions of bits and bytes of data across customer touchpoints each day. The customer and consultant partnerships we’ve made in the broader data-people community are also a big factor in our continued growth.
It also represents part of the current focus for Project Jupyter : adding support for collaboration, enhanced security, projects as top-level entities, data registry, metadata management, and telemetry about usage. Full disclosure: I’m part of that effort and consulting on behalf of NYU. See you at Rev 3 in 2020! Upcoming events.
And they rarely, if ever, host the most current data available. Sathish: Before Kloudio, I was doing data engineering and management consulting for big technology firms in the Bay Area. In the future, spreadsheet users will be able to curate and publish rich metadata about their spreadsheets back into the data catalog.
This multi-brand online retailer hosts thousands of products for sale on the internet and collects millions of bits and bytes of data across customer touchpoints each day. The customer and consultant partnerships we’ve made in the broader data-people community are also a big factor in our continued growth.
This past week, I had the pleasure of hosting Data Governance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , Data Governance lead at Alation. In my work as a governance consultant, we would tackle quality through the following process. Here’s an example.
When the IdP is created in the previous step, an event is added in an Amazon Simple Notification Service (Amazon SNS) topic with its details, such as name and SAML metadata. When this is not the case, the platform teams themselves need to develop custom functionality at the host level to ensure that role accesses are correctly controlled.
On January 4th I had the pleasure of hosting a webinar. As with any good consulting response, “it depends.” Do you recommend a consulting approach strategy rather than a CDO strategy? We cannot of course forget metadata management tools, of which there are many different. ex : we help you to improve your performances !
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. So, I hear you say, let’s share metadata and make the data self-describing. Here is the link to the replay, in case you are interested. In too many cases rubbish went in, and rubbish came out. Sure, that can help for sure.
Services Technical and consulting services are employed to make sure that implementation and maintenance go smoothly. These include how-to guides, best practices, and in-person consultations. Every time a hospital administrator wants to check inventory levels, they consult a dashboard. The days of Big BI are over. addresses).
Absence of data catalog and metadata management – Data didn’t have any metadata associated with it, and so use cases couldn’t consume the data without further explanation from the data source owners and specialists. In addition, they use generative AI capabilities to generate business metadata.
If the ban is enacted, cloud-based deployments on Azure, AWS, and Nvidia could be discontinued, potentially requiring urgent migration to alternative models, said Anil Clifford, founder of UK-based IT consulting firm Eden Consulting. If I was an enterprise CIO, I would not use the hosted version of DeepSeek, from DeepSeek via the API.
HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3) , and can host very large tables with billions of rows and millions of columns. hbase-site hbase.rs.prefetchblocksonopen TRUE Whether the server should asynchronously load all the blocks when a store file is opened (data, metadata, and index).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content