This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. Using Athena and the dbt adapter, you can transform raw data in Amazon S3 into well-structured tables suitable for analytics.
Over the years, this customer-centric approach has led to the introduction of groundbreaking features such as zero-ETL , data sharing , streaming ingestion , datalake integration , Amazon Redshift ML , Amazon Q generative SQL , and transactional datalake capabilities.
Data landscape in EUROGATE and current challenges faced in datagovernance The EUROGATE Group is a conglomerate of container terminals and service providers, providing container handling, intermodal transports, maintenance and repair, and seaworthy packaging services. Eliminate centralized bottlenecks and complex data pipelines.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
How can companies protect their enterprise data assets, while also ensuring their availability to stewards and consumers while minimizing costs and meeting data privacy requirements? Data Security Starts with DataGovernance. Do You Know Where Your Sensitive Data Is?
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations.
Preparing for an artificial intelligence (AI)-fueled future, one where we can enjoy the clear benefits the technology brings while also the mitigating risks, requires more than one article. This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Addressing the Challenge.
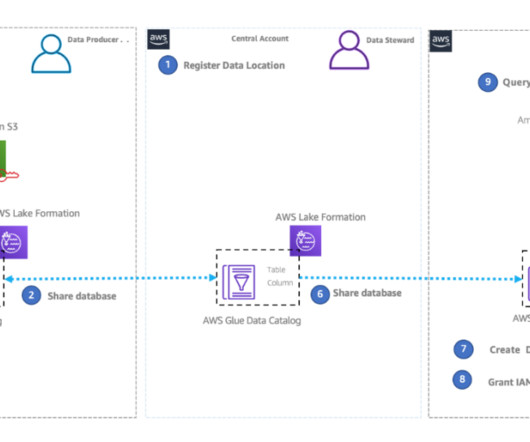
In this blog post, there are three personas: DataLake Administrator (with admin level access) User Silver from the Data Engineering group User Lead Auditor from the Auditor group. You will see how different personas in an organization can access the data without the need to modify their existing enterprise entitlements.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
Inspired by these global trends and driven by its own unique challenges, ANZ’s Institutional Division decided to pivot from viewing data as a byproduct of projects to treating it as a valuable product in its own right. Consumer feedback and demand drives creation and maintenance of the data product.
Data management, when done poorly, results in both diminished returns and extra costs. Hallucinations, for example, which are caused by bad data, take a lot of extra time and money to fix — and they turn users off from the tools. Having automated and scalable data checks is key.”
The ability to facilitate and automate access to data provides the following benefits: Satori improves the user experience by providing quick access to data. This increases the time-to-value of data and drives innovative decision-making. Adam has been in and around the data space throughout his 20+ year career.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
This post is co-authored by Vijay Gopalakrishnan, Director of Product, Salesforce Data Cloud. In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central data warehouse or a datalake to deliver business insights.
The original proof of concept was to have one data repository ingesting data from 11 sources, including flat files and data stored via APIs on premises and in the cloud, Pruitt says. There are a lot of variables that determine what should go into the datalake and what will probably stay on premise,” Pruitt says.
Exercising tactful platform selection In many cases, only IT has access to data and data intelligence tools in organizations that don’t practice data democratization. So in order to make data accessible to all, new tools and technologies are required. Most organizations don’t end up with datalakes, says Orlandini.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. With a cloud deployment, enterprises can leverage a “pay as you go” model; reducing the burden of incurring capital costs. With an on-premise deployment, enterprises have full control over data security, data access, and datagovernance.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, data warehouse, and machine learning use cases. You can build projects and subscribe to both unstructured and structured data assets within the Amazon DataZone portal.
People might not understand the data, the data they chose might not be ideal for their application, or there might be better, more current, or more accurate data available. An effective datagovernance program ensures data consistency and trustworthiness. It can also help prevent data misuse.
Without meeting GxP compliance, the Merck KGaA team could not run the enterprise datalake needed to store, curate, or process the data required to inform business decisions. Underpinning everything with security and governance. It established a datagovernance framework within its enterprise datalake.
Still, to truly create lasting value with data, organizations must develop data management mastery. This means excelling in the under-the-radar disciplines of data architecture and datagovernance. The knock-on impact of this lack of analyst coverage is a paucity of data about monies being spent on data management.
Data architecture is what defines the structures and systems within an organization responsible for collecting, storing, and accessing data, along with the policies and processes that dictate how data is governed. When we talk about modern data architecture, there are several unique benefits to this kind of approach.
The data volume is in double-digit TBs with steady growth as business and data sources evolve. smava’s Data Platform team faced the challenge to deliver data to stakeholders with different SLAs, while maintaining the flexibility to scale up and down while staying cost-efficient.
It gives them the ability to identify what challenges and opportunities exist, and provides a low-cost, low-risk environment to model new options and collaborate with key stakeholders to figure out what needs to change, what shouldn’t change, and what’s the most important changes are. With automation, data quality is systemically assured.
This past week, I had the pleasure of hosting DataGovernance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , DataGovernance lead at Alation. Can you have proper data management without establishing a formal datagovernance program?
Amazon Redshift enables data warehousing by seamlessly integrating with other data stores and services in the modern data organization through features such as Zero-ETL , data sharing , streaming ingestion , datalake integration , and Redshift ML. Who is Getir?
And most importantly, it democratizes access to end-users, such as Data Engineering teams, Data Science teams, and even citizen data scientists, across the organization while ensuring compliance with datagovernance policies are met. Customers using Modak Nabu with CDP today have deployed DataLakes and.
Datagovernance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or datalakes cataloged with the AWS Glue data catalog.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
Low user adoption rates Diana Stout, senior business analyst, Schellman Schellman It’s critical for organizations wanting to realize the benefits of BI tools to get buy-in from all stakeholders straight away as any initial reluctance can result in low adoption rates. What Gartner is writing about is the concept of a data fabric.”
The cost of OpenAI is the same whether you buy it directly or through Azure. New models roll out at the same time, and buying from Microsoft offers safety and governance advantages like every other Azure service, with access to Azure OpenAI services segmented by subscription and tenant, and each enterprise getting its own instance.
Then we explain the benefits of Amazon DataZone and walk you through key features. Collaboration – Analysts, data scientists, and data engineers often own different steps within the end-to-end analytics journey but do not have an simple way to collaborate on the same governeddata, using the tools of their choice.
The first post of this series describes the overall architecture and how Novo Nordisk built a decentralized data mesh architecture, including Amazon Athena as the data query engine. The third post will show how end-users can consume data from their tool of choice, without compromising datagovernance.
Datagovernance is traditionally applied to structured data assets that are most often found in databases and information systems. There are millions of advanced spreadsheet users, and they spend more than a quarter of their time repeating the same or similar steps every time a spreadsheet or data source is updated or refreshed.
Today, tens of thousands of customers run business-critical workloads on Amazon Redshift to cost-effectively and quickly analyze their data using standard SQL and existing business intelligence (BI) tools. Amazon Redshift now makes it easier for you to run queries in AWS datalakes by automatically mounting the AWS Glue Data Catalog.
Previously, there were three types of data structures in telco: . Entity data sets — i.e. marketing datalakes . There are a few catalysts: The journey to the cloud: Telco companies are reassessing their IT infrastructure and seeking more cost-efficient operations by maximizing public cloud deployments.
A new research report by Ventana Research, Embracing Modern DataGovernance , shows that modern datagovernance programs can drive a significantly higher ROI in a much shorter time span. Historically, datagovernance has been a manual and restrictive process, making it almost impossible for these programs to succeed.
In addition, the foundation role monitors the state of the metadata, data quality indicators, data permissions, information classification labels, and so on. It is crucial in datagovernance and data management. We use AWS Glue to preprocess, cleanse, and enrich data.
The tasks behind efficient, responsible AI lifecycle management The continuous application of AI and the ability to benefit from its ongoing use require the persistent management of a dynamic and intricate AI lifecycle—and doing so efficiently and responsibly. But the implementation of AI is only one piece of the puzzle.
Within the context of a data mesh architecture, I will present industry settings / use cases where the particular architecture is relevant and highlight the business value that it delivers against business and technology areas. A Client Example.
The solution uses AWS services such as AWS HealthLake , Amazon Redshift , Amazon Kinesis Data Streams , and AWS Lake Formation to build a 360 view of patients. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
In this post, we discuss how you can use purpose-built AWS services to create an end-to-end data strategy for C360 to unify and govern customer data that address these challenges. The following diagram illustrates the different pipelines to ingest data from various source systems using AWS services.
We also use Amazon S3 to store AWS Glue scripts, logs, and temporary data generated during the ETL process. This approach offers the following benefits: Enhanced security – By using PrivateLink and VPC endpoints, data transfer between Snowflake and Amazon S3 is secured within the AWS network, reducing exposure to potential security threats.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content