This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Source – pexels.com Are you struggling to manage and analyze large amounts of data? Are you looking for a cost-effective and scalable solution for your datawarehouse needs? AWS Redshift is a fully managed, petabyte-scale datawarehouse […]. Look no further than AWS Redshift.
Along the way, it adopted Snowflake’s AI Data Cloud and became an investor in the company in 2017. The origins of Capital One Slingshot began with the need to develop internal tooling to ensure that the company realized potential business value improvements by managing costs and automating governance processes.
With the dbt adapter for Athena adapter now supported in dbt Cloud, you can seamlessly integrate your AWS data architecture with dbt Cloud, taking advantage of the scalability and performance of Athena to simplify and scale your data workflows efficiently.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. With pay-as-you-go pricing, platforms that deliver high-performance benefit users not only through faster results but also through direct cost savings.
Now with Amazon Bedrock Knowledge Bases integration with structured data, you can use simple, natural language prompts to query complex financial datasets. From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization.
Migrating a data fulfillment center (i.e. warehouse). Your datawarehouse is not too different from an Amazon fulfillment center. Your old datawarehouse has become deprecated. Or you predict significant cost and efficiency benefits from transferring to a different data warehousing platform.
At the core of the next generation of Amazon SageMaker is Amazon SageMaker Unified Studio , a single data and AI development environment where you can find and access your organizations data and act on it using the best tool for the job across virtually any use case.
This puts tremendous stress on the teams managing datawarehouses, and they struggle to keep up with the demand for increasingly advanced analytic requests. To gather and clean data from all internal systems and gain the business insights needed to make smarter decisions, businesses need to invest in datawarehouse automation.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud datawarehouse.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. This persistent session model provides the following key benefits: The ability to create temporary tables that can be referenced across the entire session lifespan.
In traditional databases, we would model such applications using a normalized data model (entity-relation diagram). A key pillar of AWS’s modern data strategy is the use of purpose-built data stores for specific use cases to achieve performance, cost, and scale. These types of queries are suited for a datawarehouse.
DataOps helps the data mesh deliver greater business agility by enabling decentralized domains to work in concert. . This post (1 of 5) is the beginning of a series that explores the benefits and challenges of implementing a data mesh and reviews lessons learned from a pharmaceutical industry data mesh example.
Interestingly, you can address many of them very effectively with a datawarehouse. First of all, many companies have accumulated quite a lot of historical data. The process of exporting the data, filtering them, cleansing them, and reformatting them for the new system is time-consuming and costly. Probably not.
It’s costly and time-consuming to manage on-premises datawarehouses — and modern cloud data architectures can deliver business agility and innovation. However, CIOs declare that agility, innovation, security, adopting new capabilities, and time to value — never cost — are the top drivers for cloud data warehousing.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Moreover, they can be combined to benefit from individual strengths.
Large user communities of analysts and developers benefit from Impala’s fast query execution, helping them get their work done more effectively. Now that more and more data warehousing is done in the cloud, much of that in the Cloudera DataWarehousedata service, performance improvement directly equates to cost savings.
We will explain the ad hoc reporting meaning, benefits, uses in the real world, but first, let’s start with the ad hoc reporting definition. Your Chance: Want to benefit from modern ad hoc reporting? Without big data, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore. What Is Ad Hoc Reporting?
Satori enables both just-in-time and self-service access to data. Solution overview Satori creates a transparent layer providing visibility and control capabilities that is deployed in front of your existing Redshift datawarehouse. This increases the time-to-value of data and drives innovative decision-making.
By centralizing container and logistics application data through Amazon Redshift and establishing a governance framework with Amazon DataZone, EUROGATE achieved both performance optimization and cost efficiency. AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. It allows us to independently upgrade the Virtual Warehouses and Database Catalogs.
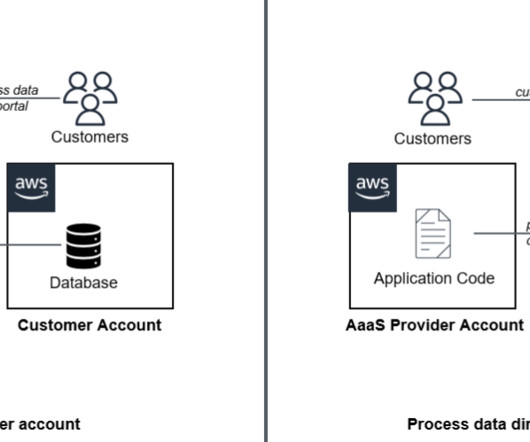
This model provides organizations with a cost-effective, scalable, and flexible solution for building analytics. The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times lower cost per user and up to 7.9
Data practitioners need to upgrade to the latest Spark releases to benefit from performance improvements, new features, bug fixes, and security enhancements. This process often turns into year-long projects that cost millions of dollars and consume tens of thousands of engineering hours. job to AWS Glue 4.0.
2) BI Strategy Benefits. Over the past 5 years, big data and BI became more than just data science buzzwords. In response to this increasing need for data analytics, business intelligence software has flooded the market. The costs of not implementing it are more damaging, especially in the long term.
One of the most effective ways to improve performance and minimize cost in database systems today is by avoiding unnecessary work, such as data reads from the storage layer (e.g., disks, remote storage), transfers over the network, or even data materialization during query execution. Introduction. Performance.
ActionIQ taps directly into a brand’s datawarehouse to build smart audiences, resolve customer identities, and design personalized interactions to unlock revenue across the customer lifecycle. Organizations are demanding secure, cost efficient, and time efficient solutions to power their marketing outcomes.
Certain big data systems can be used to automatically bring this information together (such as through the use of BigQuery integration ). Customer experience is another key area that can benefit from big data analytics. The operational side of your business could benefit greatly as well. Big data analytics advantages.
Drilling down into the ‘where’ and ‘why’ of SQL, Excel, and data mining, this book is informational and easy to follow, making it a winning addition to our list of the best SQL books. The all-encompassing nature of this book makes it a must for a data bookshelf. Best Advanced SQL Books. Viescas, Douglas J.
The benefits of Data Vault automation from the more abstract – like improving data integrity – to the tangible – such as clearly identifiable savings in cost and time. So Seriously … You Should Automate Your Data Vault. By Danny Sandwell.
By asking the right questions, utilizing sales analytics software that will enable you to mine, manipulate and manage voluminous sets of data, generating insights will become much easier. Before starting any business venture, you need to make the most crucial step: prepare your data for any type of serious analysis.
times lower cost per user and up to 7.9 times better price-performance than other cloud datawarehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements.
Armed with BI-based prowess, these organizations are a testament to the benefits of using online data analysis to enhance your organization’s processes and strategies. Many are also overwhelmed by where to start, worried about cost and effort, and discouraged by stories of BI failures. “Up
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, datawarehouses and data lakes fail when applied at the scale and speed of today’s organizations.
Open, secure platform for anyone to: Access data and analytics. Change the processes used to create data and analytics. Figure 2: Employing a DataOps Platform as a process hub minimizes the cost for new analytics. The DataKitchen Platform is based on a “process first” principle that minimizes the “ cost per question.”
Credit: Phil Goldstein Jerry Wang, Peloton’s Director of Data Engineering (left), and Evy Kho, Peloton’s Manager of Subscription Analytics, discuss how the company has benefited from using Amazon Redshift. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis.
It implemented hundreds of schema and data set changes per week without introducing errors. Arguably the most agile and effective data analytics capability in the pharmaceutical industry was accomplished cost-effectively, with a data engineering team of seven and another 10-12 data analysts.
Paired to this, it can also: Improved decision-making process: From customer relationship management, to supply chain management , to enterprise resource planning, the benefits of effective DQM can have a ripple impact on an organization’s performance. Industry-wide, the positive ROI on quality data is well understood. 1 – The people.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Patterns, trends and correlations that may go unnoticed in text-based data can be more easily exposed and recognized with data visualization software. Data virtualization is becoming more popular due to its huge benefits. billion on data virtualization services by 2026. What benefits does it bring to businesses?
AWS customers and data engineers use the Apache Iceberg table format for its many benefits, as well as for its high performance and reliability at scale to build transactional data lakes and write-optimized solutions with Amazon EMR, AWS Glue, Athena, and Amazon Redshift on Amazon Simple Storage Service (Amazon S3).
Choice Hotels International’s early and big bet on the cloud has allowed it to glean the many benefits of its digital transformation and devote more energies to a key corporate value — sustainability, its CIO maintains. It also helped reduce energy consumption and costs. All the logic is still in Java hosted on Amazon’s infrastructure.”
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the datawarehouse. This post also includes example SQLs, which you can run on your own Redshift Serverless datawarehouse to experience the benefits of this feature.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content