This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Source – pexels.com Are you struggling to manage and analyze large amounts of data? Are you looking for a cost-effective and scalable solution for your datawarehouse needs? Look no further than AWS Redshift.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Data ingestion – Pentaho was used to ingest data sourced from multiple datapublishers into the data store.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. With pay-as-you-go pricing, platforms that deliver high-performance benefit users not only through faster results but also through direct cost savings.
Plug-and-play integration : A seamless, plug-and-play integration between data producers and consumers should facilitate rapid use of new data sets and enable quick proof of concepts, such as in the data science teams. As part of the required data, CHE data is shared using Amazon DataZone.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, datawarehouses and data lakes fail when applied at the scale and speed of today’s organizations.
Our next book is dedicated to anyone who wants to start a career as a data scientist and is looking to get all the knowledge and skills in a way that is accessible and well-structured. Originally published in 2018, the book has a second edition that was released in January of 2022. 4) “SQL Performance Explained” by Markus Winand.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
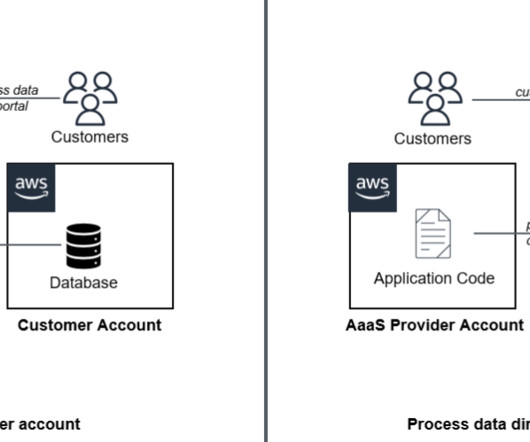
This model provides organizations with a cost-effective, scalable, and flexible solution for building analytics. The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times lower cost per user and up to 7.9
Enterprise datawarehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern datawarehouse can address them. ETL jobs and staging of data often often require large amounts of resources.
times lower cost per user and up to 7.9 times better price-performance than other cloud datawarehouses on real-world workloads using advanced techniques like concurrency scaling to support hundreds of concurrent users, enhanced string encoding for faster query performance, and Amazon Redshift Serverless performance enhancements.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. It allows us to independently upgrade the Virtual Warehouses and Database Catalogs.
Patterns, trends and correlations that may go unnoticed in text-based data can be more easily exposed and recognized with data visualization software. Data virtualization is becoming more popular due to its huge benefits. billion on data virtualization services by 2026. What benefits does it bring to businesses?
Inspired by these global trends and driven by its own unique challenges, ANZ’s Institutional Division decided to pivot from viewing data as a byproduct of projects to treating it as a valuable product in its own right. Consumer feedback and demand drives creation and maintenance of the data product.
Paired to this, it can also: Improved decision-making process: From customer relationship management, to supply chain management , to enterprise resource planning, the benefits of effective DQM can have a ripple impact on an organization’s performance. Industry-wide, the positive ROI on quality data is well understood. 1 – The people.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
In healthcare, missing treatment data or inconsistent coding undermines clinical AI models and affects patient safety. In retail, poor product master data skews demand forecasts and disrupts fulfillment. In the public sector, fragmented citizen data impairs service delivery, delays benefits and leads to audit failures.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Designing databases for datawarehouses or data marts is intrinsically much different than designing for traditional OLTP systems. Accordingly, data modelers must embrace some new tricks when designing datawarehouses and data marts. Figure 1: Pricing for a 4 TB datawarehouse in AWS.
Given the value this sort of data-driven insight can provide, the reason organizations need a data catalog should become clearer. It’s no surprise that most organizations’ data is often fragmented and siloed across numerous sources (e.g., Why You Need a Data Catalog – Three Business Benefits of Data Catalogs.
For AI to be truly transformative, as many people as possible should have access to its benefits. is not just for data scientists and developers — business users can also access it via an easy-to-use interface that responds to natural language prompts for different tasks. Trust is one part of the equation. The second is access.
These transactional data lakes combine features from both the data lake and the datawarehouse. You can simplify your data strategy by running multiple workloads and applications on the same data in the same location. The Iceberg table is synced with the AWS Glue Data Catalog.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for data lake, datawarehouse, and machine learning use cases. You can build projects and subscribe to both unstructured and structured data assets within the Amazon DataZone portal.
Then we explain the benefits of Amazon DataZone and walk you through key features. Data governance – Constructs to govern data are hidden within individual tools and managed differently by different teams, preventing organizations from having traceability on who’s accessing what and why.
Benefits of enterprise architecture There are several benefits to enterprise architecture , including resiliency and adaptability, managing supply chain disruptions, staff recruitment and retention, improved product and service delivery, and tracking data and APIs. Datawarehouse. Data modeling.
After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. I spent eight years in the real-world performance group where I specialized in high visibility and high impact data warehousing competes and benchmarks. you name it.
Instead, the publicly held operator of Cathay Pacific Airlines and HK Express is shifting from migration to optimization mode in an effort to wrest additional benefits from its all-in cloud transformation. Even as its cloud journey reaches cruising altitude, Cathay Pacific Group IT is not slowing down.
Rokita believes the key to making that transition is to stop thinking of data warehousing and AI/ML as separate departments with their own distinct systems. The datawarehouse is about past data, and models are about future data. Often, we want to share data between each other,” he says.
The adoption of cloud computing is increasingly becoming mainstream, with all the big tech giants starting to standardise services and drive down costs. This phase includes the migration of our datawarehouse and business intelligence capabilities, using Synapse and PowerBI respectively. CIO Africa: What was the process like?
Redshift Serverless is a serverless option of Amazon Redshift that allows you to run and scale analytics without having to provision and manage datawarehouse clusters. Redshift Serverless automatically provisions and intelligently scales datawarehouse capacity to deliver high performance for all your analytics.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehousecosts by up to 50 percent by augmenting with this solution. [1]
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. The producer also needs to manage and publish the data asset so it’s discoverable throughout the organization.
Then you could weigh that against the benefits and drawbacks (e.g., Getting started with Spark In perusing much of the freely available published material on getting started with Spark, many recommend getting started with a local installation (on one machine) and then moving to having it installed on a cluster of machines.
The term “data management platform” can be confusing because, while it sounds like a generalized product that works with all forms of data as part of generalized data management strategies, the term has been more narrowly defined of late as one targeted to marketing departments’ needs. Of course, marketing also works.
These reporting tools have many advantages: low cost, meeting basic reporting needs, having a dedicated discussion board to solve user problems… 1.FineReport. Jaspersoft ETL – an open-source ETL system that is easy to deploy and execute, creating a comprehensive datawarehouse and data set. FineReport.
Then the reporting engine publishes these reports to the reporting portal to allow non-technical end-users access. In this way, users can gain insights from the data and make data-driven decisions. . The underlying data is responsible for data management, including data collection, ETL, building a datawarehouse, etc.
Using predictive analytics, organizations can plan for forthcoming scenarios, anticipate new trends, and prepare for them most efficiently and cost-effectively. Predicting forthcoming trends sets the stage for optimizing the benefits your organization takes from them. Her debut novel, The Book of Jeremiah , was published in 2019.
On June 7, 1983, a product was born that would revolutionize how organizations would store, manage, process , and query their data: IBM Db2. Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” In 1969, retired IBM Fellow Edgar F. Chamberlin and Raymond F.
After a job ends, WM gets information about job execution from the Telemetry Publisher, a role in the Cloudera Manager Management Service. Suggesting workloads that should move to public cloud and understanding the public cloud costs. Data Engineering jobs only. CDP Data Engineering (Public Cloud & Private Cloud).
The above chart compares monthly searches for Business Process Reengineering (including its arguable rebranding as Business Transformation ) and monthly searches for Data Science between 2004 and 2019. And reduced costs aren’t guaranteed […]. What was not generally accounted for were the associated intangible costs.
Data architects and data modelers who specialize in areas such as schema design, identifying query access patterns and building and maintaining datawarehouses. Infrastructure engineers who are tasked with making sure the backend systems are up and running, including creating and maintaining APIs and micro-services.
There are many benefits to Embedded BI approach including: World-Class Data Architecture provides access to a wealth of data sources and datawarehouses, and accommodates business application architecture with single-tenant mode or multi-tenant modes.
In other words, software publishers have sought to minimize the level of disruption for existing ERP customers while modernizing business applications, increasing integration, and adding important new functionality. Sometimes those costs hide in payroll and benefits, as staff spends significant time adjusting to those changes.
Data cleansing is the process of identifying and correcting errors, inconsistencies, and inaccuracies in a dataset to ensure its quality, accuracy, and reliability. This process is crucial for businesses that rely on data-driven decision-making, as poor data quality can lead to costly mistakes and inefficiencies.
In this session: IBM and AWS discussed the benefits and features of this new fully managed offering spanning availability, security, backups, migration and more. Can Amazon RDS for Db2 be used for running data warehousing workloads? AWS ran a live demo to show how to get started in just a few clicks.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content