This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Data architecture has evolved significantly to handle growing data volumes and diverse workloads. Moreover, they can be combined to benefit from individual strengths.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
In traditional databases, we would model such applications using a normalized data model (entity-relation diagram). A key pillar of AWS’s modern data strategy is the use of purpose-built data stores for specific use cases to achieve performance, cost, and scale. These types of queries are suited for a datawarehouse.
It’s costly and time-consuming to manage on-premises datawarehouses — and modern cloud data architectures can deliver business agility and innovation. However, CIOs declare that agility, innovation, security, adopting new capabilities, and time to value — never cost — are the top drivers for cloud data warehousing.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. withRegion("us-east-1").build() withQueueUrl(queueUrl).withMaxNumberOfMessages(10)).getMessages.asScala
In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. This mechanism allows developers to focus on preparing the SQL files per the business logic, and the rest is taken care of by dbt.
The term business intelligence often also refers to a range of tools that provide quick, easy-to-digest access to insights about an organization’s current state, based on available data. Benefits of BI BI helps business decision-makers get the information they need to make informed decisions.
Snowflake integrates with AWS Glue Data Catalog to access the Iceberg table catalog and the files on Amazon S3 for analytical queries. This greatly improves performance and compute cost in comparison to external tables on Snowflake , because the additional metadata improves pruning in query plans.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera DataWarehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ). Cloudera Data Engineering (Spark 3) with Airflow enabled. Loading data into Iceberg tables with CDE.
Cloudera DataWarehouse (CDW) running Hive has previously supported creating materialized views against Hive ACID source tables. release and the matching CDW Private Cloud Data Services release, Hive also supports creating, using, and rebuilding materialized views for Iceberg table format.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
These transactional data lakes combine features from both the data lake and the datawarehouse. You can simplify your data strategy by running multiple workloads and applications on the same data in the same location. The Iceberg table is synced with the AWS Glue Data Catalog.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
There is an increased need for data lakes to support database like features such as ACID transactions, record-level updates and deletes, time travel, and rollback. Apache Iceberg is designed to support these features on cost-effective petabyte-scale data lakes on Amazon S3. The snapshot points to the manifest list.
From the factory floor to online commerce sites and containers shuttling goods across the global supply chain, the proliferation of data collected at the edge is creating opportunities for real-time insights that elevate decision-making. The concept of the edge is not new, but its role in driving data-first business is just now emerging.
In this session: IBM and AWS discussed the benefits and features of this new fully managed offering spanning availability, security, backups, migration and more. Can Amazon RDS for Db2 be used for running data warehousing workloads? At what level are snapshot-based backups taken? 13.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. The decoupled compute and storage architecture of Amazon Redshift enables you to build highly scalable, resilient, and cost-effective workloads.
Most enterprises in the 21st century regard data as an incredibly valuable asset – Insurance is no exception - to know your customers better, know your market better, operate more efficiently and other business benefits. It definitely depends on the type of data, no one method is always better than the other. That’s the reward.
In addition, this data lives in so many places that it can be hard to derive meaningful insights from it all. This is where analytics and data platforms come in: these systems, especially cloud-native Sisense, pull in data from wherever it’s stored ( Google BigQuery datawarehouse , Snowflake , Redshift , etc.).
However, as there are already 25 million terabytes of data stored in the Hive table format, migrating existing tables in the Hive table format into the Iceberg table format is necessary for performance and cost. They also provide a “ snapshot” procedure that creates an Iceberg table with a different name with the same underlying data.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud, providing up to five times better price-performance than any other cloud datawarehouse, with performance innovation out of the box at no additional cost to you. It also logs details about the rolled back or undo transactions.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Introduction Apache Iceberg has recently grown in popularity because it adds datawarehouse-like capabilities to your data lake making it easier to analyze all your data — structured and unstructured. Problem with too many snapshots Everytime a write operation occurs on an Iceberg table, a new snapshot is created.
Furthermore, data events are filtered, enriched, and transformed to a consumable format using a stream processor. The result is made available to the application by querying the latest snapshot. He works backward from customer’s use cases and designs data solutions to solve their business problems.
Suggesting workloads that should move to public cloud and understanding the public cloud costs. In this blog, we walk through the Impala workloads analysis in iEDH, Cloudera’s own Enterprise DataWarehouse (EDW) implementation on CDH clusters. After moving to CDP, take a snapshot to use as a CDP baseline. Maintain SLA.
Transaction data lake use case Amazon EMR customers often use Open Table Formats to support their ACID transaction and time travel needs in a data lake. Another popular transaction data lake use case is incremental query. The following are some highlighted steps: Run a snapshot query. %%sql
Snapshot testing augments debugging capabilities by recording past table states, facilitating the identification of unforeseen spikes, declines, or abnormalities before their effect on production systems. Workaround: Use Git branches, tagging, and commit messages to trackchanges.
Any time new test cases or test results are created or modified, events trigger such that processing is immediate and new snapshot files are available via an API or data is pulled at the refresh frequency of the reporting or business intelligence (BI) tool. Fixed-size data files avoid further latency due to unbound file sizes.
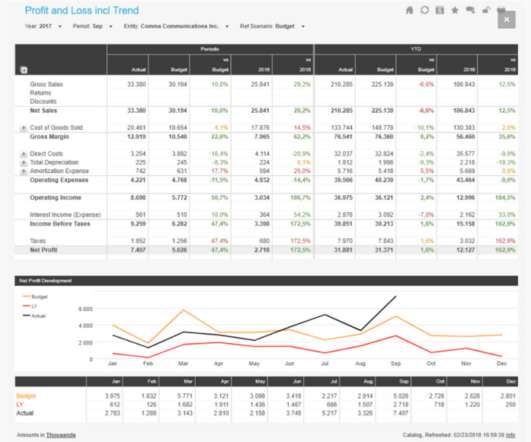
Whether it is a sales performance dashboard, a snapshot of A/R collections, a trends analysis dashboard, a marketing performance app, or a variance-to-Year 12-month view report, EPM reporting can be a powerful tool in helping your organization meet its objectives. Step 6: Drill into the Data. Profit and Loss with Trend Analysis.
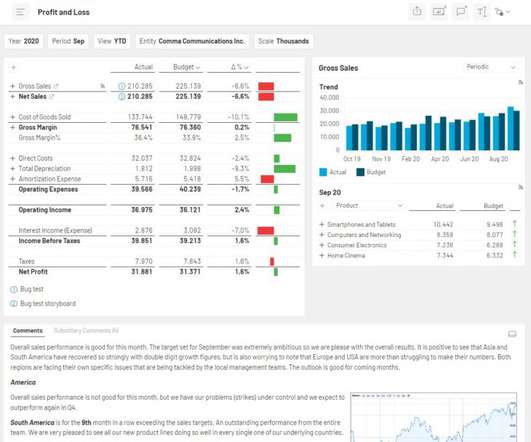
In today’s dynamic business environment, gaining comprehensive visibility into financial data is crucial for making informed decisions. In this article, we will explore the concept of a financial dashboard, highlight its numerous benefits, and provide various kinds of financial dashboard examples for you to employ and explore.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, data lakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
Amazon Redshift is a petabyte-scale, enterprise-grade cloud datawarehouse service delivering the best price-performance. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift to cost-effectively and quickly analyze their data using standard SQL and existing business intelligence (BI) tools.
Presto is an open source distributed SQL query engine for data analytics and the data lakehouse, designed for running interactive analytic queries against datasets of all sizes, from gigabytes to petabytes. Because of its distributed nature, Presto scales for petabytes and exabytes of data. It lands as raw data in HDFS.
The open data lakehouse is quickly becoming the standard architecture for unified multifunction analytics on large volumes of data. It combines the flexibility and scalability of data lake storage with the data analytics, data governance, and data management functionality of the datawarehouse.
The company wanted to leverage all the benefits the cloud could bring, get out of the business of managing hardware and software, and not have to deal with all the complexities around security, he says. She realized HGA needed a data strategy, a datawarehouse, and a data analytics leader.
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. Oracle Hyperion and Oracle PBCS are valued for their robust capabilities, for example, but those typically come at a high cost.
While they typically emphasize the benefits of the cloud for their clients, they understand the advantages for themselves as well. Most companies say that the added costs of the cloud are offset by other savings, such as eliminating hardware and data center expenses. Still, the disparity in price remains a hurdle for customers.
Costing, procurement, subcontractor management, and labor combine to create a level of intricacy that businesses in other sectors don’t have to contend with. Spreadsheets become cumbersome for intricate projects, leading to error-prone data consolidation and version control nightmares.
That brings tremendous benefits for small and midsize businesses, but it also leads to increased challenges arising from the inherent complexity of the underlying data. There is yet another problem with manual processes: the resulting reports only reflect a snapshot in time.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content