This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Initially, data warehouses were the go-to solution for structured data and analytical workloads but were limited by proprietary storage formats and their inability to handle unstructureddata. Moreover, they can be combined to benefit from individual strengths.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
They also face increasing regulatory pressure because of global data regulations , such as the European Union’s General Data Protection Regulation (GDPR) and the new California Consumer Privacy Act (CCPA), that went into effect last week on Jan. Today’s data modeling is not your father’s data modeling software.
The data catalog is a searchable asset that enables all data – including even formerly siloed tribal knowledge – to be cataloged and more quickly exposed to users for analysis. Three Types of Metadata in a Data Catalog. Technical Metadata. Operational Metadata. for analysis and integration purposes).
The extensive pre-trained knowledge of the LLMs enables them to effectively process and interpret even unstructureddata. This allows companies to benefit from powerful models without having to worry about the underlying infrastructure. An important aspect of this democratization is the availability of LLMs via easy-to-use APIs.
Companies and individuals with the computing power that data scientists might need are able to sell it in exchange for cryptocurrencies. There are a lot of powerful benefits of offering an incentive-based approach as hardware accelerators. A text analytics interface that helps derive actionable insights from unstructureddata sets.
There is no disputing the fact that the collection and analysis of massive amounts of unstructureddata has been a huge breakthrough. We would like to talk about data visualization and its role in the big data movement. Data virtualization is becoming more popular due to its huge benefits.
Recent research by Vanson Bourne for Iron Mountain found that 93% of organizations are already using genAI in some capacity, while Gartner research suggests that genAI early adopters are experiencing benefits including increases in revenue (15.8%), cost savings (15.2%) and productivity improvements (22.6%), on average.
Data lakes are centralized repositories that can store all structured and unstructureddata at any desired scale. The power of the data lake lies in the fact that it often is a cost-effective way to store data. Avoid the misperception of thinking of a data lake as just a way of doing a database more cheaply.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
Within the context of a data mesh architecture, I will present industry settings / use cases where the particular architecture is relevant and highlight the business value that it delivers against business and technology areas. Data and Metadata: Data inputs and data outputs produced based on the application logic.
In other words, using metadata about data science work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in data science work is concentrated. Less data gets decompressed, deserialized, loaded into memory, run through the processing, etc.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Organizations are collecting and storing vast amounts of structured and unstructureddata like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
This blog explores the challenges associated with doing such work manually, discusses the benefits of using Pandas Profiling software to automate and standardize the process, and touches on the limitations of such tools in their ability to completely subsume the core tasks required of data science professionals and statistical researchers.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructureddata at any scale and in various formats.
According to this article , it costs $54,500 for every kilogram you want into space. It has been suggested that their Falcon 9 rocket has lowered the cost per kilo to $2,720. That means removing errors, filling in missing information and harmonizing the various data sources so that there is consistency.
When you store and deliver data at Shutterstock’s scale, the flexibility and elasticity of the cloud is a huge win, freeing you from the burden of costly, high-maintenance data centers. For Shutterstock, the benefits of AI have been immediately apparent. If you’re not keeping up, you’re getting left behind.”
The ability to define the concepts and their relationships that are important to an organization in a way that is understandable to a computer has immense benefits. Data and content are organized in a way that facilitates discoverability, insights and decision making rather than be bound by limitations of data formats and legacy systems.
This is the case with the so-called intelligent data processing (IDP), which uses a previous generation of machine learning. LLMs do most of this better and with lower cost of customization. Atanas Kiryakov : A CMS typically contains modest metadata , describing the content: date, author, few keywords and one category from a taxonomy.
The High-Performance Tagging PowerPack bundle The High-Performance Tagging PowerPack is designed to satisfy taxonomy and metadata management needs by allowing enterprise tagging at a scale. It comes with significant cost advantages and includes software installation, support, and maintenance from one convenient source for the full bundle.
The Corner Office is pressing their direct reports across the company to “Move To The Cloud” to increase agility and reduce costs. Perhaps one of the most significant contributions in data technology advancement has been the advent of “Big Data” platforms. But then the costs start running out of control.
Atanas Kiryakov presenting at KGF 2023 about Where Shall and Enterprise Start their Knowledge Graph Journey Only data integration through semantic metadata can drive business efficiency as “it’s the glue that turns knowledge graphs into hubs of metadata and content”.
According to an article in Harvard Business Review , cross-industry studies show that, on average, big enterprises actively use less than half of their structured data and sometimes about 1% of their unstructureddata.
Administrators can customize Amazon DataZone to use existing AWS resources, enabling Amazon DataZone portal users to have federated access to those AWS services to catalog, share, and subscribe to data, thereby establishing data governance across the platform.
Other forms of governance address specific sets or domains of data including information governance (for unstructureddata), metadata governance (for data documentation), and domain-specific data (master, customer, product, etc.). Data catalogs and spreadsheets are related in many ways.
This is why public agencies are increasingly turning to an active governance model, which promotes data visibility alongside in-workflow guidance to ensure secure, compliant usage. An active data governance framework includes: Assigning data stewards. Standardizing data formats. Quantifying effectiveness with metrics.
Regardless of the division or use case it is related to, dimensional data models can be used to store data obtained from tracking various processes like patient encounters, provider practice metrics, aftercare surveys, and more. They often negate many benefits of data vaults, and require more business logic, which can be avoided.
Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from data quality issues. Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few.
Streaming jobs constantly ingest new data to synchronize across systems and can perform enrichment, transformations, joins, and aggregations across windows of time more efficiently. For building such a data store, an unstructureddata store would be best.
Turns out, exercise equipment doesn’t provide many benefits when it goes unused. The same principle applies to getting value from data. Organizations may acquire a lot of data, but they aren’t getting much value from it. This type of data waste results in missing out on the second project advantage.
Organizations with several coupled upstream and downstream systems can significantly benefit from dbt Cores robust dependency management via its Directed Acyclic Graph (DAG) structure. Data freshness propagation: No automatic tracking of data propagation delays across multiplemodels.
In this post, we show how Ruparupa implemented an incrementally updated data lake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. We also discuss the benefits Ruparupa gained after the implementation. Let’s look at each main component in more detail.
When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?” ” through a truly data literate organization. What is data democratization?
In the era of data, organizations are increasingly using data lakes to store and analyze vast amounts of structured and unstructureddata. Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making.
It supports a variety of storage engines that can handle raw files, structured data (tables), and unstructureddata. It also supports a number of frameworks that can process data in parallel, in batch or in streams, in a variety of languages. The foundation of this end-to-end AML solution is Cloudera Enterprise.
They define DSPM technologies this way: “DSPM technologies can discover unknown data and categorize structured and unstructureddata across cloud service platforms. A cloud data breach of your most sensitive data would be a costly blow, both in terms of monetary losses and damage to your brand.
The IBM team is even using generative AI to create synthetic data to build more robust and trustworthy AI models and to stand in for real-world data protected by privacy and copyright laws. These systems can evaluate vast amounts of data to uncover trends and patterns, and to make decisions.
Enterprises that had invested time, effort, and money into configuring the models might have to spend more time switching to alternative models requiring significant time and reconfiguration costs, Clifford further explained. per one million output tokens for its R1 reasoning model. Other experts, such as agentic AI-providing Doozer.AI
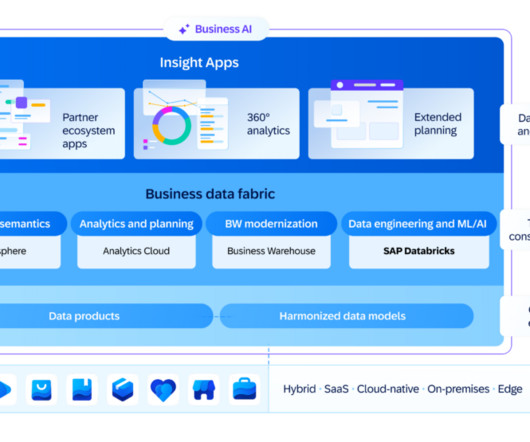
They can move their BW system (unless they used too much ABAP) into BDC (and therefore cloud) and benefit from extended maintenance till 2030. The predefined content (data products) is expected by many SAP customers to help them build a data foundation for different analytical use cases more quickly. on-premises data sources).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content