This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
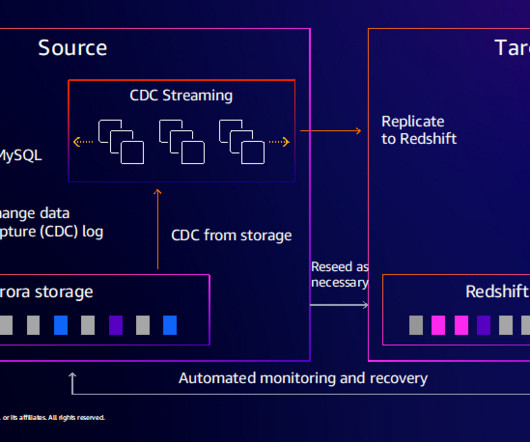
This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS. The following diagram illustrates the solution architecture.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. He has worked with building datawarehouses and big data solutions for over 13 years.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
This stack creates the following resources and necessary permissions to integrate the services: Data stream – With Amazon Kinesis Data Streams , you can send data from your streaming source to a data stream to ingest the data into a Redshift datawarehouse. version cluster. version cluster.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units. Business analysts sometimes perform data science, but usually, they integrate and visualize data and create reports and dashboards from data supplied by other groups.
This blog is intended to give an overview of the considerations you’ll want to make as you build your Redshift datawarehouse to ensure you are getting the optimal performance. dashboards), it can leave your consumers frustrated with their experience. Modeling Your Data for Performance. Dataarchitecture.
In this post, we look at three key challenges that customers face with growing data and how a modern datawarehouse and analytics system like Amazon Redshift can meet these challenges across industries and segments. Nasdaq’s massive data growth meant they needed to evolve their dataarchitecture to keep up.
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. AWS Glue 5.0 Finally, AWS Glue 5.0
To run analytics on their operational data, customers often build solutions that are a combination of a database, a datawarehouse, and an extract, transform, and load (ETL) pipeline. ETL is the process data engineers use to combine data from different sources.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
The CLEA dashboards were built on the foundation of the Well-Architected Lab. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. The difference lies in when and where data transformation takes place. In ETL, data is transformed before it’s loaded into the datawarehouse.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift , the first fully managed, petabyte-scale cloud datawarehouse. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. The decoupled compute and storage architecture of Amazon Redshift enables you to build highly scalable, resilient, and cost-effective workloads.
Organisations are looking at ways of simplifying data; for example, through simple rebranding efforts to disguise the complexity. However, SAP Datasphere goes much deeper deeper than a simple rebranding; it is the next generation of SAP DataWarehouse Cloud. They fail to get a grip on their data.
The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high data quality, all with low total cost of ownership (TCO) and no need for additional tools or licenses. It’s raw, unprocessed data straight from the source.
After walking his executive team through the data hops, flows, integrations, and processing across different ingestion software, databases, and analytical platforms, they were shocked by the complexity of their current dataarchitecture and technology stack. It isn’t easy.
Amazon Redshift is a popular cloud datawarehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
A sea of complexity For years, data ecosystems have gotten more complex due to discrete (and not necessarily strategic) data-platform decisions aimed at addressing new projects, use cases, or initiatives. Layering technology on the overall dataarchitecture introduces more complexity.
Like all of our customers, Cloudera depends on the Cloudera Data Platform (CDP) to manage our day-to-day analytics and operational insights. Many aspects of our business live within this modern dataarchitecture, providing all Clouderans the ability to ask, and answer, important questions for the business.
An integrated solution provides single sign-on access to data sources and datawarehouses.’. Your clients have access to embedded BI objects from within the application with scalable integration APIs and objects including dashboards, crosstab, tabular, KPIs, graphs, reports etc. Rapid Deployment.
Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the data lake, without vendor lock-in. Organizations want modern dataarchitectures that evolve at the speed of their business and we are happy to support them with the first open data lakehouse. .
They’re often responsible for building algorithms for accessing raw data, too, but to do this, they need to understand a company’s or client’s objectives, as aligning data strategies with business goals is important, especially when large and complex datasets and databases are involved.
There are also no-code data engineering and AI/ML platforms so regular business users, as well as data engineers, scientists and DevOps staff, can rapidly develop, deploy, and derive business value.
Data engineers are often responsible for building algorithms for accessing raw data, but to do this, they need to understand a company’s or client’s objectives, as aligning data strategies with business goals is important, especially when large and complex datasets and databases are involved. Data engineer job description.
In this post, we highlight the seamless integration of Amazon Athena and Amazon QuickSight , which enables the visualization of operational metrics for AWS Glue Data Quality rule evaluation in an efficient and effective manner. The following architecture diagram shows an overview of the complete pipeline. Choose Visualize.
The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your data lake and the datawarehouse. The following diagram shows a sample C360 dashboard built on Amazon QuickSight.
Federated queries allow querying data across Amazon RDS for MySQL and PostgreSQL data sources without the need for extract, transform, and load (ETL) pipelines. If storing operational data in a datawarehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported.
In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices. All these architecture patterns are integrated with Amazon Kinesis Data Streams. Refer to Amazon Kinesis Data Streams integrations for additional details.
From 2000 to 2015, I had some success [5] with designing and implementing DataWarehousearchitectures much like the following: As a lot of my work then was in Insurance or related fields, the Analytical Repositories tended to be Actuarial Databases and / or Exposure Management Databases, developed in collaboration with such teams.
eMAG , a Romania-based retailer seen as a pioneer in e-commerce, was struggling to manage the tremendously large amount of data coming in every second. The company needed a modern dataarchitecture to manage the growing traffic effectively. . Now the team’s data scientists can better analyze data with dashboard access.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. On the Amazon Redshift console, navigate to the Redshift Serverless dashboard. Choose Create workgroup.
You might be modernizing your dataarchitecture using Amazon Redshift to enable access to your data lake and data in your datawarehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. sales_datashare_schema"."sales_schema.store_sales";
In a modern dataarchitecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a datawarehouse. In this case, the ETL developer would choose TRUNCATE to ensure the data is fully refreshed but the table schema is guaranteed not to change.
How effectively and efficiently an organization can conduct data analytics is determined by its data strategy and dataarchitecture , which allows an organization, its users and its applications to access different types of data regardless of where that data resides.
The goal in addressing these pain points is to empower your stakeholders (both within Finance/FP&A and your business partners) to be able to deliver: Consistent reporting and dashboards. Typically, we take our multiple data sources and perform some level of ETL on the data. Self-service reporting. Drill-down capability.
Some espouse the opinion that the term is synonymous with Dashboards. Jane opened up her personal dashboard, which already showed the headline figures the CFO had been citing. Some charts or tables may be replicated across a number of dashboards, but others with be specific to a particular area of the business.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content