This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
As such, the data on labor, occupancy, and engagement is extremely meaningful. Here, CIO Patrick Piccininno provides a roadmap of his journey from data with no integration to meaningful dashboards, insights, and a data literate culture. You ’re building an enterprise data platform for the first time in Sevita’s history.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. and later supports the Apache Iceberg framework for datalakes. AWS Glue 3.0 The following diagram illustrates the solution architecture.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a business intelligence dashboard and take action on immediately.
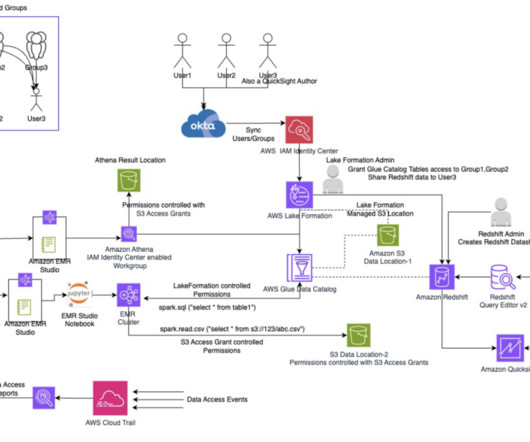
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
The rise of distributed data architectures like Data Mesh will combine with DataOps automation to give rise to Hub-Spoke architectures that deftly blend the benefits of centralization and decentralization. For example, a Hub-Spoke architecture could integrate data from a multitude of sources into a datalake.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. This is further integrated into Tableau dashboards. datazone_env_twinsimsilverdata"."cycle_end";')
There is an established body of practice around creating, managing, and accessing OLAP data (known as “cubes”). DataLakes. There has been a lot of talk over the past year or two in the D365F&SCM world about “datalakes.” Traditional databases and data warehouses do not lend themselves to that task.
To address the flood of data and the needs of enterprise businesses to store, sort, and analyze that data, a new storage solution has evolved: the datalake. What’s in a DataLake? Data warehouses do a great job of standardizing data from disparate sources for analysis. Taking a Dip.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. Then our analytics team, an IT group, makes sure we build the datalake in the right sequence.
On OpenSearch Dashboards, navigate to the main menu and choose Security. Using a PUT request in OpenSearch Dashboards for repository registration is not supported. For more details, see Using OpenSearch Dashboards with Amazon OpenSearch Service. Add the Amazon Resource Name (ARN) of TheSnapshotRole to the backend roles.
Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units. Business analysts sometimes perform data science, but usually, they integrate and visualize data and create reports and dashboards from data supplied by other groups.
The data requirements of a thriving business are never complete. There is an endless stream of new data sources to integrate, exceptions to manage and requests for new charts, graphs and dashboards. To cope with all of the complexity, the company had to hire more and more consultants each year to engineer and analyze the data.
One of the most important innovations in data management is open table formats, specifically Apache Iceberg , which fundamentally transforms the way data teams manage operational metadata in the datalake.
With this integration, you can now seamlessly query your governed datalake assets in Amazon DataZone using popular business intelligence (BI) and analytics tools, including partner solutions like Tableau. You can now view your project’s subscribed data directly within Tableau and build dashboards.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online data visualization , dashboards, and new functionalities to adapt current processes and develop new ones. Discover the available data sources. Data changes. Identify defects and enhancements.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Imagine a data team of one or two dozen data professionals serving the analytics needs of hundreds of sales and marketing team members. They submit an endless list of requests for new data sets, dashboards, segmentations, cached data sets and nearly anything else they think will help them meet business goals.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. Data integrity presented a major challenge for the team, as there were many instances of duplicate data.
The data mesh is focused on building trust in data and promoting the use of data by business users who can benefit from it. In essence, a domain is an integrated data set and a set of views, reports, dashboards, and artifacts created from the data.
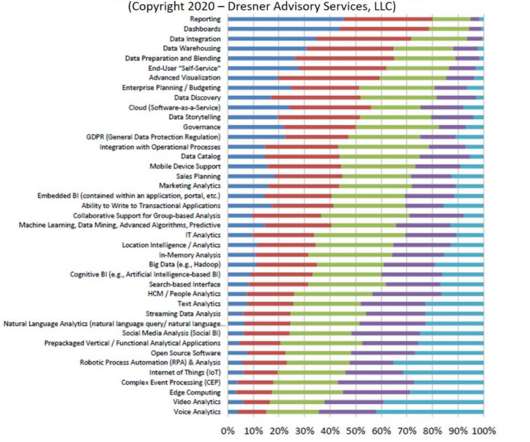
Among all the hot analytics initiatives to choose from (big data, IoT, NLP, data storytelling, cognitive BI, GDPR), plain old reporting is what is considered the most important strategic initiative. But seriously, reporting? That has to be the most boring term in all of analytics. How can you not think of "TPS Reports"?
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
There are several choices to consider, each with its own set of advantages and disadvantages: Data warehouses are used to store data that has been processed for a specific function from one or more sources. Datalakes hold raw data that has not yet been altered to meet a specific purpose.
If you ask an engineer to show how they operate the application in production, they will likely show containers and operational dashboards—not unlike any other software service. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. Compute.
The integration is new way for customers to query operational logs in Amazon S3 and Amazon S3-based datalakes without needing to switch between tools to analyze operational data. Amazon S3 is an object storage service offering industry-leading scalability, data availability, security, and performance.
Many of the existing visual business intelligence and dashboard tools also use SQL as a standard language. Democratizing data refers to a mechanism that provides a self-serve paradigm and culture for an ever-growing internal audience to get the data they need to add value to the business. What do you mean by democratizing?
She applies some calculations and forwards the file to a data engineer who loads the data into a database and runs a Talend job that performs ETL to dimensionalize the data and produce a Data Mart. The data engineer then emails the BI Team, who refreshes a Tableau dashboard.
McDermott’s sustainability innovation would not have been possible without key advancements in the cloud, analytics, and, in particular, datalakes, Dave notes. But for Dave, the key ingredient for innovation at McDermott is data. Then maybe we can have a dashboard that looks at anomalies on spot-checking. Vagesh Dave.
Grant access to User1 in Lake Formation Sign in to the Lake Formation console, choose Datalake permissions in the navigation pane, and grant access to the user group on the database oktank_tipblog_temp and table customer. On the Amazon Redshift Serverless dashboard console, navigate to the namespace you created.
Grafana provides powerful customizable dashboards to view pipeline health. QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. Sample AWS CDK template This post provides a sample AWS CDK template for a dashboard using AWS Glue observability metrics.
The new metrics provide aggregate and fine-grained insights into the health and operations of your job runs and the data being processed. In addition to providing insightful dashboards, the metrics provide classification of errors, which helps with root cause analysis of performance bottlenecks and error diagnosis.
2:30 PM – 3:30 PM (PDT) Mandalay Bay ANT335 | Get the most out of your data warehousing workloads. 5:30 PM – 6:30 PM (PDT) Ceasars Forum ANT349-R | Advanced real-time analytics and ML in your data warehouse [REPEAT]. 2:30 PM – 3:30 PM (PDT) Mandalay Bay ANT335 | Get the most out of your data warehousing workloads.
Backcountry also lacked many core services critical for an online retailer — no CMS, no analytics, no data platform, and no datalake. In recent years, e-commerce platforms have evolved into a combination of cloud, analytics, CX UIs, and datalakes dubbed customer data platforms (CDPs).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content