This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
As such, the data on labor, occupancy, and engagement is extremely meaningful. Here, CIO Patrick Piccininno provides a roadmap of his journey from data with no integration to meaningful dashboards, insights, and a data literate culture. You ’re building an enterprise data platform for the first time in Sevita’s history.
However, computerization in the digital age creates massive volumes of data, which has resulted in the formation of several industries, all of which rely on data and its ever-increasing relevance. Data analytics and visualization help with many such use cases. It is the time of big data. Understand Your Audience.
Datalakes are centralized repositories that can store all structured and unstructured data at any desired scale. The power of the datalake lies in the fact that it often is a cost-effective way to store data. The power of the datalake lies in the fact that it often is a cost-effective way to store data.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. This is further integrated into Tableau dashboards. datazone_env_twinsimsilverdata"."cycle_end";')
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalake analytics, machine learning (ML), and data monetization.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. When you’re connected, you can query, visualize, and share data—governed by Amazon DataZone—within Tableau.
Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards. The final model provides sales teams with the highest-value opportunities, which they can visualize in a business intelligence dashboard and take action on immediately.
In a world increasingly dominated by data, users of all kinds are gathering, managing, visualizing, and analyzing data in a wide variety of ways. One of the downsides of the role that data now plays in the modern business world is that users can be overloaded with jargon and tech-speak, which can be overwhelming.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
There’s no shortage of consultants who will promise to manage the end-to-end lifecycle of data from integration to transformation to visualization. . The challenge is that data engineering and analytics are incredibly complex. The data requirements of a thriving business are never complete.
Grafana provides powerful customizable dashboards to view pipeline health. QuickSight makes it straightforward for business users to visualizedata in interactive dashboards and reports. QuickSight makes it straightforward for business users to visualizedata in interactive dashboards and reports.
There is an established body of practice around creating, managing, and accessing OLAP data (known as “cubes”). DataLakes. There has been a lot of talk over the past year or two in the D365F&SCM world about “datalakes.” Traditional databases and data warehouses do not lend themselves to that task.
Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units. Business analysts sometimes perform data science, but usually, they integrate and visualizedata and create reports and dashboards from data supplied by other groups.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. He is a very visual person, so our proof of concept collects different data sets and ingests them into our Azure data house.
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region datalake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.
It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online datavisualization , dashboards, and new functionalities to adapt current processes and develop new ones. Discover the available data sources. Data changes. Identify defects and enhancements.
In the era of big data, datalakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructured data, offering a flexible and scalable environment for data ingestion from multiple sources.
The data can also help us enrich our commodity products. How are you populating your datalake? We’ve decided to take a practical approach, led by Kyle Benning, who runs our data function. Then our analytics team, an IT group, makes sure we build the datalake in the right sequence.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
In this post, we highlight the seamless integration of Amazon Athena and Amazon QuickSight , which enables the visualization of operational metrics for AWS Glue Data Quality rule evaluation in an efficient and effective manner. The crawler builds a Data Catalog, so the data can be queried using Athena.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level. Choose Create.
Most tools offer visual programming interfaces that enable users to drag and drop various icons optimized for data analysis. Visual IDE for data pipelines; RPA for rote tasks. The visual IDE offers more than 300 options that can be joined together to form a complex pipeline. Top predictive analytics tools compared.
The integration is new way for customers to query operational logs in Amazon S3 and Amazon S3-based datalakes without needing to switch between tools to analyze operational data. Amazon S3 is an object storage service offering industry-leading scalability, data availability, security, and performance.
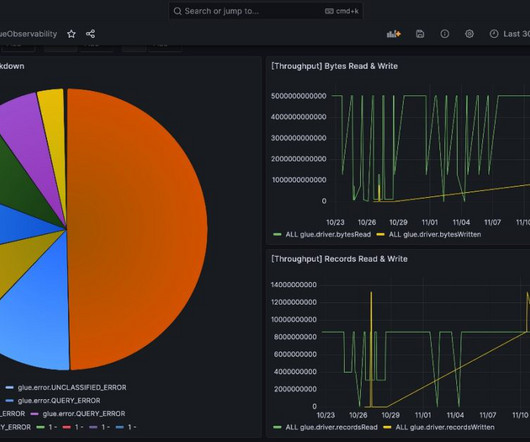
AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your data integration pipelines built on AWS Glue. With Grafana, you can create, explore, and share visually rich, data-driven dashboards. Lastly, configure the dashboard.
In this post, we demonstrate how Amazon Athena , Amazon QuickSight , and Confluent work together to enable visualization of data streams in near-real time. Datavisualization for Confluent data A frequent use case for enterprises is datavisualization. Choose Create data source.
The new metrics provide aggregate and fine-grained insights into the health and operations of your job runs and the data being processed. In addition to providing insightful dashboards, the metrics provide classification of errors, which helps with root cause analysis of performance bottlenecks and error diagnosis.
Company data exists in the datalake. Data Catalog profilers have been run on existing databases in the DataLake. A Cloudera Data Warehouse virtual warehouse with Cloudera Data Visualisation enabled exists. The Data Analyst. A Cloudera Machine Learning Workspace exists .
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make data integration effortless. Choose the link under OpenSearch Dashboards URL.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science.
The trend has been towards using cloud-based applications and tools for different functions, such as Salesforce for sales, Marketo for marketing automation, and large-scale data storage like AWS or datalakes such as Amazon S3 , Hadoop and Microsoft Azure. Building dashboards and widgets.
Many of the existing visual business intelligence and dashboard tools also use SQL as a standard language. Democratizing data refers to a mechanism that provides a self-serve paradigm and culture for an ever-growing internal audience to get the data they need to add value to the business.
We have evolved with our users, from early-on Hadoop hackers needing quick access to data in the DataLake, to a much more sophisticated SQL tool. HUE also comes with a simplistic form of pre-visualization of results and download result sets as csv files or pdfs, for local exploration or further insight sharing.
McDermott’s sustainability innovation would not have been possible without key advancements in the cloud, analytics, and, in particular, datalakes, Dave notes. But for Dave, the key ingredient for innovation at McDermott is data. Then maybe we can have a dashboard that looks at anomalies on spot-checking. Vagesh Dave.
BI software helps companies do just that by shepherding the right data into analytical reports and visualizations so that users can make informed decisions. To gain employee buy-in, Stout’s team builds BI dashboards to show them how they can easily connect to and interact with their data, as well as visualize it in a meaningful way.
HR&A has used Amazon Redshift Serverless and CARTO to process survey findings more efficiently and create custom interactive dashboards to facilitate understanding of the results. This frees up our local computer space, greatly automates the survey cleaning and analysis step, and allows our clients to easily access the data results.
To achieve data-driven management, we built OneData, a data utilization platform used in the four global AWS Regions, which started operation in April 2022. The platform consists of approximately 370 dashboards, 360 tables registered in the data catalog, and 40 linked systems. Promote and expand the use of databases.
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a datalake or a data warehouse. Today, we are pleased to announce a new and enhanced visual job authoring capabilities for Amazon Redshift ETL and ELT workflows on the AWS Glue Studio visual editor.
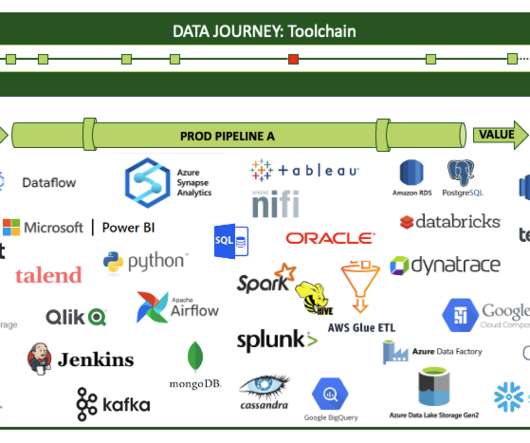
As he thinks through the various journeys that data take in his company, Jason sees that his dashboard idea would require extracting or testing for events along the way. So, the only way for a data journey to truly observe what’s happening is to get his tools and pipelines to auto-report events. Data and tool tests.
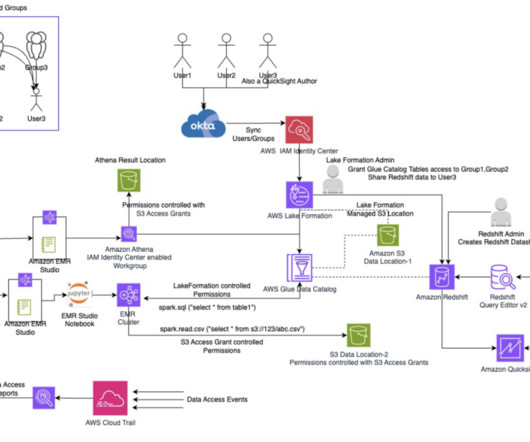
User3 is a Business Analyst who needs to query data stored in Amazon Redshift tables using the Amazon Redshift Query Editor v2. Additionally, this user builds Amazon QuickSight visualizations for the data in Redshift tables. On the Amazon Redshift Serverless dashboard console, navigate to the namespace you created.
With the advent of Business Intelligence Dashboard (BI Dashboard), access to information is no longer limited to IT departments. Every user can now create interactive reports and utilize datavisualization to disseminate knowledge to both internal and external stakeholders.
So we have a visualization layer where we teach different groups within our organization to learn. It’s evolved from over the past four years from having nothing and siloed data sets of spreadsheets and everyone doing their own thing, to being centralized based on KPIs and the trust in what they receive from the data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content