This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why: Data Makes It Different. If you ask an engineer to show how they operate the application in production, they will likely show containers and operational dashboards—not unlike any other software service. However, the concept is quite abstract. Can’t we just fold it into existing DevOps best practices?
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. Applying AI to elevate ROI Pruitt and Databricks recently finished a pilot test with Microsoft called Smart Flow.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
This middleware consists of custom code that runs data flows to stitch datatransformations, search queries, and AI enrichments in varying combinations tailored to use cases, datasets, and requirements. Ingest flows are created to enrich data as its added to an index. Flows are a pipeline of processor resources.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and from third-party sources. You can now view your project’s subscribed data directly within Tableau and build dashboards.
Similarly, Workiva was driven to DataOps due to an increased need for analytics agility to meet a range of organizational needs, such as real-time dashboard updates or ML model training and monitoring. There are a limited number of folks on the data team that can manage all of these things. Others have difficulty collaborating.
What Is Data Quality Management (DQM)? Data quality management is a set of practices that aim at maintaining a high quality of information. It goes all the way from the acquisition of data and the implementation of advanced data processes, to an effective distribution of data.
Snowflake is a modern cloud data platform that boasts instant elasticity, secure data sharing and per-second pricing across multiple clouds. Its ability to natively load and use SQL to query semi-structured and structured data within a single system simplifies your data engineering. Have questions? Contact us.
Table of Contents 1) Benefits Of Big Data In Logistics 2) 10 Big Data In Logistics Use Cases Big data is revolutionizing many fields of business, and logistics analytics is no exception. The complex and ever-evolving nature of logistics makes it an essential use case for big data applications. Did you know?
This project represents a transformative initiative designed to address the evolving landscape of cyber threats,” says Kunal Krushev, head of cybersecurity automation and intelligence with the firm’s Corporate IT — Digital Infrastructure Services. “We The initiative brought multiple capabilities to the firm’s security operations.
Movement of data across data lakes, data warehouses, and purpose-built stores is achieved by extract, transform, and load (ETL) processes using data integration services such as AWS Glue. AWS Glue provides both visual and code-based interfaces to make data integration effortless.
Redshift Data API provides a secure HTTP endpoint and integration with AWS SDKs. With Data API session reuse, you can use a single long-lived session at the start of the ETL pipeline and use that persistent context across all ETL phases. In the next step, copy data from Amazon Simple Storage Service (Amazon S3) to the temporary table.
A common task for a data scientist is to build a predictive model. You know the drill: pull some data, carve it up into features, feed it into one of scikit-learn’s various algorithms. Collectively, your attempts teach you about your data and its relation to the problem you’re trying to solve.
The CLEA dashboards were built on the foundation of the Well-Architected Lab. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. Overview of the BMW Cloud Data Hub At the BMW Group, Cloud Data Hub (CDH) is the central platform for managing company-wide data and data solutions.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Amazon DataZone natively integrates with Amazon-specific options like Amazon Athena , Amazon Redshift , and Amazon SageMaker , allowing users to analyze their project governed data. Connect to Tableau Desktop Use the Athena JDBC driver to connect Tableau to Amazon DataZone and visualize your subscribed data.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
These issues dont just hinder next-gen analytics and AI; they erode trust, delay transformation and diminish business value. Data quality is no longer a back-office concern. In this article, I am drawing from firsthand experience working with CIOs, CDOs, CTOs and transformation leaders across industries.
The main driving factors include lower total cost of ownership, scalability, stability, improved ingestion connectors (such as Data Prepper , Fluent Bit, and OpenSearch Ingestion), elimination of external cluster managers like Zookeeper, enhanced reporting, and rich visualizations with OpenSearch Dashboards.
The data in Amazon Redshift is transactionally consistent and updates are automatically and continuously propagated. Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization.
In the realm of big data utilization , we often romanticize its profound impact, envisioning scenarios like precision-targeted advertising, streamlined social security management, and the intelligent evolution of the pharmaceutical sector. Why Big Data Analysis Report? Try FineReport Now 1. Try FineReport Now 1.1
What is data management? Data management can be defined in many ways. The techniques for managing organisational data in a standardised approach that minimises inefficiency. Extraction, Transform, Load (ETL). Datatransformation. Data analytics and visualisation. Data analytics and visualisation.
Data operations (or data production) is a series of pipeline procedures that take raw data, progress through a series of processing and transformation steps, and output finished products in the form of dashboards, predictions, data warehouses or whatever the business requires. Their product is the data.
The lift and shift migration approach is limited in its ability to transform businesses because it relies on outdated, legacy technologies and architectures that limit flexibility and slow down productivity. It shows a call center streaming data source that sends the latest call center feed in every 15 seconds.
HR&A has used Amazon Redshift Serverless and CARTO to process survey findings more efficiently and create custom interactive dashboards to facilitate understanding of the results. The first step in this process is mapping the digital divide.
Amazon QuickSight is a fully managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards and reports, and share these with tens of thousands of users, either within QuickSight or embedded in your application or website. SDK Feature overview The QuickSight SDK v2.0
What is the difference between business analytics and data analytics? Business analytics is a subset of data analytics. Data analytics is used across disciplines to find trends and solve problems using data mining , data cleansing, datatransformation, data modeling, and more.
What is data analytics? Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. What are the four types of data analytics? Data analytics tools.
At Tableau Conference 2024 in San Diego today, Tableau announced new AI features for Tableau Pulse and Einstein Copilot for Tableau, along with several platform improvements aimed at democratizing data insights. This is really empowering everyone to be a data expert,” Maxon said. “It Metrics Bootstrapping.
With CloudSearch, you can search large collections of data such as webpages, document files, forum posts, or product information. In addition, with OpenSearch Service, you get advanced security with fine-grained access control, the ability to store and analyze log data for observability and security, along with dashboarding and alerting.
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
In this session, we will start R right from the beginning, from installing R through to datatransformation and integration, through to visualizing data by using R in PowerBI. Then, we will move towards powerful but simple to use datatypes in R such as data frames. CuRious about R in Power BI? I hope it is useful.
Due to this low complexity, the solution uses AWS serverless services to ingest the data, transform it, and make it available for analytics. AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, ML, and application development.
QuickSight meets varying analytics needs with modern interactive dashboards, paginated reports, natural language queries, ML-insights, and embedded analytics, from one unified service. The AWS Glue Data Catalog contains the table definitions for the smart sensor data sources stored in the S3 buckets.
In this post, we show you how to use PCA’s data to build automated QuickSight dashboards for advanced analytics to assist in quality assurance (QA) and quality management (QM) processes. You can apply data, agent, call duration, and language filters for targeted search. Select -PCA-Dashboard and choose Share.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. Cleaning up dirty data. Step 4: Query.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Data is made queryable in real time.
These include data discovery, modern ETL, cleansing, transforming, and centralized cataloging. We used it for executing long-running scripts, such as for ingesting data from an external API. We used it to define flows that would periodically load data from selected operational systems into our data warehouse.
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately. Data journey observability is the first step in implementing DataOps.
Amazon QuickSight dashboards showcase the results from the analyzer. With QuickSight, you can visualize YARN log data and conduct analysis against the datasets generated by pre-built dashboard templates and a widget. This step creates datasets on QuickSight dashboards in your AWS target account.
Before we dive in, let’s define strands of AI, Machine Learning and Data Science: Business intelligence (BI) leverages software and services to transformdata into actionable insights that inform an organization’s strategic and tactical business decisions. What does this mean for the Microsoft Data Platform Professional?
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















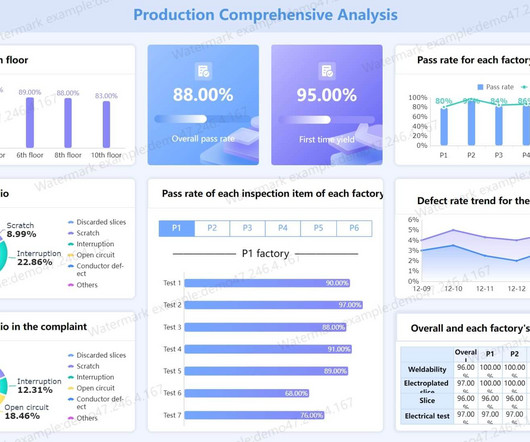































Let's personalize your content