This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. But first, let’s define what data quality actually is. What is the definition of data quality? Why Do You Need Data Quality Management?
You can now use your tool of choice, including Tableau, to quickly derive business insights from your data while using standardized definitions and decentralized ownership. Refer to the detailed blog post on how you can use this to connect through various other tools.
You can create temporary tables once and reference them throughout, without having to constantly refresh database connections and restart from scratch. This enables you to integrate web-based applications to access data from Amazon Redshift using an API to run SQL statements. Building a serverless data processing workflow.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
The CLEA dashboards were built on the foundation of the Well-Architected Lab. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. Data providers and consumers are the two fundamental users of a CDH dataset.
Key performance indicators (KPIs) of interest for a call center from a near-real-time platform could be calls waiting in the queue, highlighted in a performance dashboard within a few seconds of data ingestion from call center streams. Visualize KPIs of call center performance in near-real time through OpenSearch Dashboards.
If you ask an engineer to show how they operate the application in production, they will likely show containers and operational dashboards—not unlike any other software service. but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. Foundational Infrastructure Layers.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of data integrity, and the optimization of pipelines for improved efficiency.
What is data management? Data management can be defined in many ways. Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Extraction, Transform, Load (ETL). Datatransformation. SharePoint.
This feature enables users to save calculations from a Tableau dashboard directly to Tableau’s metrics layer so they can monitor and track the information over time. Einstein Copilot for Tableau remains in beta, but Tableau announced two new features for the AI assistant as well: AI-assisted datatransformation.
As we explore examples of data analysis reports and interactive report data analysis dashboards, we embark on a journey to unravel the nuanced art of transforming raw data into meaningful narratives that empower decision-makers. Try FineReport Now 1. Try FineReport Now 1.1 Try FineReport Now 1.1
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. That takes us to a conspicuous omission from that list of roles: the data scientists who focused on building basic models. Companies will still need advanced ML modeling and data viz, sure.
In addition, with OpenSearch Service, you get advanced security with fine-grained access control, the ability to store and analyze log data for observability and security, along with dashboarding and alerting. You’ll have all of CloudSearch’s capabilities and more.
Kinesis Data Firehose is a fully managed service for delivering near-real-time streaming data to various destinations for storage and performing near-real-time analytics. You can perform analytics on VPC flow logs delivered from your VPC using the Kinesis Data Firehose integration with Datadog as a destination.
Under the Transparency in Coverage (TCR) rule , hospitals and payors to publish their pricing data in a machine-readable format. For more information, refer to Delivering Consumer-friendly Healthcare Transparency in Coverage On AWS. The Data Catalog now contains references to the machine-readable data.
Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization. dbt Cloud is a hosted service that helps data teams productionize dbt deployments.
Amazon QuickSight dashboards showcase the results from the analyzer. For more details on how to configure and schedule the log collector, refer to the yarn-log-collector GitHub repo. For more information on how to use the YARN log organizer, refer to the yarn-log-organizer GitHub repo.
For setup instructions, refer to Getting started with Amazon OpenSearch Service. Choose the link under OpenSearch Dashboards URL. After the job runs successfully, navigate to OpenSearch Dashboards, and log in to the dashboard. Choose Dashboards Management on the navigation menu.
We set up our AWS CDK to refer to the contents of a specific directory and define a resource (for example, an AWS Step Functions state machine or an AWS Glue job) for each file it found in that directory. We also used it as a repository for storing code that could be retrieved and used by other services.
Data ingestion – Steps 1 and 2 use AWS DMS, which connects to the source database and moves full and incremental data (CDC) to Amazon S3 in Parquet format. Let’s refer to this S3 bucket as the raw layer. Datatransformation – Steps 3 and 4 represent an EMR Serverless Spark application (Amazon EMR 6.9
If storing operational data in a data warehouse is a requirement, synchronization of tables between operational data stores and Amazon Redshift tables is supported. In scenarios where datatransformation is required, you can use Redshift stored procedures to modify data in Redshift tables.
In this post, we show you how to use PCA’s data to build automated QuickSight dashboards for advanced analytics to assist in quality assurance (QA) and quality management (QM) processes. You can apply data, agent, call duration, and language filters for targeted search. Select -PCA-Dashboard and choose Share.
Consequently, there was a fivefold rise in data integrations and a fivefold increase in ad hoc queries submitted to the Redshift cluster. Also, over time the number of BI dashboards (both scheduled and live) increased, which contributed to more queries being submitted to the Redshift cluster.
This report is essential for understanding revenue streams, identifying opportunities for optimization, and making data-driven decisions regarding pricing and promotions. Refer to Enabling AWS PrivateLink in the Snowflake documentation to verify the steps, required access level, and service level to set the configurations. Choose Next.
Components of the consumer application The consumer application comprises three main parts that work together to consume, transform, and load messages from Amazon MSK into a target database. The following diagram shows an example of datatransformations in the handler component.
However, you might face significant challenges when planning for a large-scale data warehouse migration. The data warehouse is highly business critical with minimal allowable downtime. For an example, refer to How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform.
Data Vault 2.0 allows for the following: Agile data warehouse development Parallel data ingestion A scalable approach to handle multiple data sources even on the same entity A high level of automation Historization Full lineage support However, Data Vault 2.0 JOB_NAME All The process name from the ETL framework.
To populate the database, the Infomedia team developed a data pipeline using Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue for datatransformations, and Apache Hudi for CDC and record-level updates.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Enable responsible, transparent and explainable data and AI workflows with watsonx.governance.
In summary, embedded analytics refers to actionable intelligence seamlessly integrated into customer-facing products, applications, or services. Lengthy Turnaround Time In the competitive landscape of analytics, swift delivery of insights is paramount to proving the value of data and analytics teams.
Kinesis Data Analytics for Apache Flink In our example, we perform the following actions on the streaming data: Connect to an Amazon Kinesis Data Streams data stream. View the stream data. Transform and enrich the data. Manipulate the data with Python. Open the file to inspect the new data.
Datatransformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset.
A data warehouse is typically used by companies with a high level of data diversity or analytical requirements. When you want to get answers from your data, your request goes directly to the appropriate cube. When organizations start to collect data in multiple databases, the size of the data sets grow exponentially.
A source of unpredictable workloads is dbt Cloud , which SafetyCulture uses to manage datatransformations in the form of models. Refer to Managing Amazon Redshift Serverless using the console for setup steps. We create a datashare called prod_datashare to allow the serverless instance access to data in the provisioned cluster.
The results of the log analyzer reveal Hadoop workload insights with various views and metrics of the Hadoop applications shown in Amazon QuickSight dashboards, which leads to the design of a future EMR cluster. The QuickSight timeline dashboard shows the peak time job runs because of the daily batch job.
Plan In the planning phase, developers collect requirements from stakeholders such as end-users to define a data requirement. You can use your preferred IDE to implement AWS resource definition using the AWS Cloud Development Kit (AWS CDK) or AWS CloudFormation , and also the business logic of AWS Glue job scripts for data integration.
A modern data stack relies on cloud computing, whereas a legacy data stack stores data on servers instead of in the cloud. Modern data stacks provide access for more data professionals than a legacy data stack. Examples of datatransformation tools include dbt and dataform.
Data teams dealing with larger, faster-moving cloud datasets needed more robust tools to perform deeper analyses and set the stage for next-level applications like machine learning and natural language processing. One solution with immense potential is ”edge computing.”
Protect data at the source. Put data into action to optimize the patient experience and adapt to changing business models. What is Data Governance in Healthcare? Data governance in healthcare refers to how data is collected and used by hospitals, pharmaceutical companies, and other healthcare organizations and service providers.
Additionally, you can configure OpenSearch Ingestion to apply datatransformations before delivery. The content includes a reference architecture, a step-by-step guide on infrastructure setup, sample code for implementing the solution within a use case, and an AWS Cloud Development Kit (AWS CDK) application for deployment.
that gathers data from many sources. Their dashboards were visually stunning. In turn, end users were thrilled with the bells and whistles of charts, graphs, and dashboards. Yes—but basic dashboards won’t be enough. These users interact with dashboards and reports as well as personalized views of the information.
Data Extraction : The process of gathering data from disparate sources, each of which may have its own schema defining the structure and format of the data and making it available for processing. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
This field guide to data mapping will explore how data mapping connects volumes of data for enhanced decision-making. Why Data Mapping is Important Data mapping is a critical element of any data management initiative, such as data integration, data migration, datatransformation, data warehousing, or automation.
Gather/Insert data on market trends, customer behavior, inventory levels, or operational efficiency. IoT, Web Scraping, API, IDP, RPA Data Processing Data Pipelines and Analysis Layer Employ data pipelines with algorithms to filter, sort, and interpret data, transforming raw information into actionable insights.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











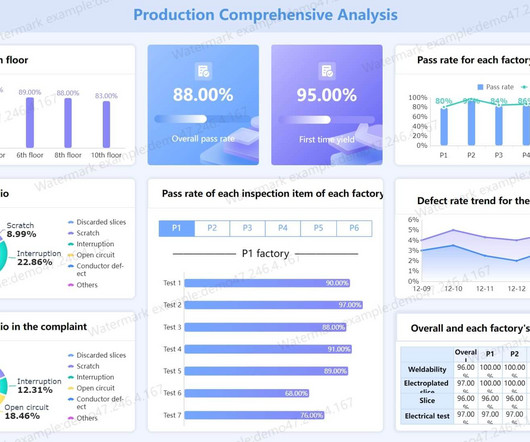
































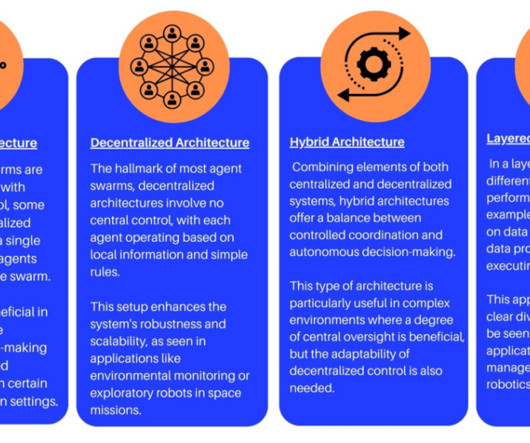








Let's personalize your content