This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Additionally, as I recently explained , the companys platform addresses a broad range of capabilities that includes data governance and security, data integration and application development, as well as the automation and incorporation of artificial intelligence (AI) and machine learning (ML) models into BI and analytics.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that you can use to analyze your data at scale. This enables you to integrate web-based applications to access data from Amazon Redshift using an API to run SQL statements. Building a serverless data processing workflow.
Whether the reporting is being done by an end user, a data science team, or an AI algorithm, the future of your business depends on your ability to use data to drive better quality for your customers at a lower cost. So, when it comes to collecting, storing, and analyzing data, what is the right choice for your enterprise?
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
In the following section, two use cases demonstrate how the data mesh is established with Amazon DataZone to better facilitate machine learning for an IoT-based digital twin and BI dashboards and reporting using Tableau. This is further integrated into Tableau dashboards. This led to a complex and slow computations.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
Amazon Redshift is the most widely used datawarehouse in the cloud, best suited for analyzing exabytes of data and running complex analytical queries. Amazon QuickSight is a fast business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from your data.
A DSS leverages a combination of raw data, documents, personal knowledge, and/or business models to help users make decisions. The data sources used by a DSS could include relational data sources, cubes, datawarehouses, electronic health records (EHRs), revenue projections, sales projections, and more.
About Redshift and some relevant features for the use case Amazon Redshift is a fully managed, petabyte-scale, massively parallel datawarehouse that offers simple operations and high performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
This stack creates the following resources and necessary permissions to integrate the services: Data stream – With Amazon Kinesis Data Streams , you can send data from your streaming source to a data stream to ingest the data into a Redshift datawarehouse. version cluster. version cluster.
As I explained in our recent Buyers Guide for Data Platforms , the popularization of generative artificial intelligence (GenAI) has had a significant impact on the requirements for data platforms in the last 18 months. Snowflake is not alone in adding support for AI workloads to its data platform.
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. Ingest 100s of TB of network eventdata per day .
I recently had the honor of delivering the keynote at the “The Journey to the Top” Event at SAP UK headquarters, and you can see my slides and a video in my previous post How Data is Powering The Future of Business: Trends and Opportunities. People, collaboration, and ease of use.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 4 shows this workflow.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. Data lakes are more focused around storing and maintaining all the data in an organization in one place.
In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices. The collected data is available in milliseconds to allow real-time analytics use cases, such as real-time dashboards, real-time anomaly detection, and dynamic pricing.
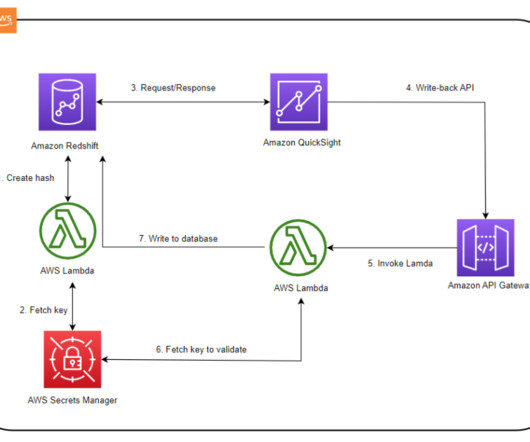
A write-back is the ability to update a data mart, datawarehouse, or any other database backend from within BI dashboards and analyze the updated data in near-real time within the dashboard itself. AnyCompany wants to build a new dashboard with quote history data for analysis and business insights.
Cloudera users can securely connect Rill to a source of event stream data, such as Cloudera DataFlow , model data into Rill’s cloud-based Druid service, and share live operational dashboards within minutes via Rill’s interactive metrics dashboard or any connected BI solution. Cloudera DataWarehouse).
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse. or higher version) database.
The application supports custom workflows to allow demand and supply planning teams to collaborate, plan, source, and fulfill customer orders, then track fulfillment metrics via persona-based operational and management reports and dashboards. To achieve this, Aruba used Amazon S3 Event Notifications.
Social BI indicates the process of gathering, analyzing, publishing, and sharing data, reports, and information. This is done using interactive Business Intelligence and Analytics dashboards along with intuitive tools to improve data clarity. Analytical tools are used to achieve user understanding and comfort. Summing Up.
Managing large-scale datawarehouse systems has been known to be very administrative, costly, and lead to analytic silos. The good news is that Snowflake, the cloud data platform, lowers costs and administrative overhead. When did you begin a technology partnership with Snowflake and why?
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
Welcome back to our exciting exploration of architectural patterns for real-time analytics with Amazon Kinesis Data Streams! Before we dive in, we recommend reviewing Architectural patterns for real-time analytics using Amazon Kinesis Data Streams, part 1 for the basic functionalities of Kinesis Data Streams.
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Additionally, you can choose the capacity, to limit the compute resources of the datawarehouse. For this post, set this to 8 RPUs.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Reference data management.
With Power BI, you can pull data from almost any data source and create dashboards that track the metrics you care about the most. You can drill into data, create a variety of visualizations, and (literally) ask questions about it using AI.
The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
Amazon Redshift is a fully managed cloud datawarehouse that’s used by tens of thousands of customers for price-performance, scale, and advanced data analytics. Getir’s data analytics environment encompasses hundreds of terabytes of data, thousands of tables, and billions upon billions of data rows.
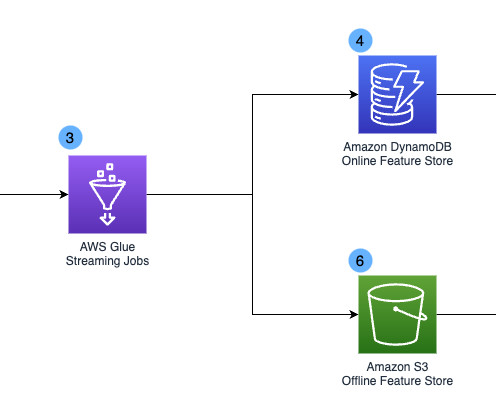
Real-time AI brings together streaming data and machine learning algorithms to make fast and automated decisions; examples include recommendations, fraud detection, security monitoring, and chatbots. The underpinning architecture needs to include event-streaming technology, high-performing databases, and machine learning feature stores.
It automatically provisions and intelligently scales datawarehouse compute capacity to deliver fast performance, and you pay only for what you use. Just load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool. Ashish Agrawal is a Sr.
During that same time, AWS has been focused on helping customers manage their ever-growing volumes of data with tools like Amazon Redshift , the first fully managed, petabyte-scale cloud datawarehouse. One group performed extract, transform, and load (ETL) operations to take raw data and make it available for analysis.
With quality data at their disposal, organizations can form datawarehouses for the purposes of examining trends and establishing future-facing strategies. Industry-wide, the positive ROI on quality data is well understood. Business/Data Analyst: The business analyst is all about the “meat and potatoes” of the business.
Imperva Cloud WAF protects hundreds of thousands of websites and blocks billions of security events every day. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region data lake. Imperva harnesses data to improve their business outcomes.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
Problem statement In order to keep up with the rapid movement of fraudsters, our decision platform must continuously monitor user events and respond in real-time. However, our legacy datawarehouse-based solution was not equipped for this challenge. Amazon DynamoDB is another data source for our Streaming 2.0
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. You don’t need to worry about workloads such as ETL (extract, transform, and load), dashboards, ad-hoc queries, and so on interfering with each other.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
Create a Customized Dashboard – Earn Love, Drive Change. #2. Leverage Custom Alerts – Let Data Kick Your Butt Into Action. #3. Create a Customized Dashboard – Earn Love, Drive Change! Who does not love dashboards? Then click on Dashboards, and what do you see? New Dashboard. Humans love them.
The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high data quality, all with low total cost of ownership (TCO) and no need for additional tools or licenses. These are specifically tailored to support BI reports and dashboards as per the business requirements.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content