This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, dashboarding applications are a very common use case in Redshift customer environments where there is high concurrency and queries require quick, low-latency responses. First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead.
Metadata is at the heart of every report, dashboard, data warehouse, visualization, and anything else the BI team produces. Without an understanding of the organization’s metadata, the BI team can’t match the data from multiple sources to produce a single view of the business. Money Loser #1: Manual Data Discovery.
Some companies are beginning to build their own solutions, and several will be presenting them at Strata Data in NYC this coming Fall—e.g., Metadata and artifacts needed for audits. A dashboard that provides custom views for all principals (operations, ML engineers, data scientists, business owners).
OpenSearch Service stores different types of stored objects, such as dashboards, visualizations, alerts, security roles, index templates, and more, within the domain. In this post, we present a solution to deploy stored objects using GitHub and Jenkins while preventing users making direct changes into OpenSearch Service domain.
As quality issues are often highlighted with the use of dashboard software , the change manager plays an important role in the visualization of data quality. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. 2 – Data profiling.
Business intelligence is simply a tool, computer software, and practice used to collect, integrate, analyze, and present raw business data that can be used to create actionable and informative business data. Business intelligence tools can include data warehousing, data visualizations, dashboards, and reporting.
In the best case scenario, the trained neural network accurately represents the underlying phenomenon of interest and produces the correct output even when presented with new input data the model didn’t see during training. You might have millions of short videos , with user ratings and limited metadata about the creators or content.
Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata. In-depth analysis: LLMs can go beyond simple data presentation to identify and explain complex patterns in the data.
First, the machine learning community has conducted groundbreaking research in many areas of interest to companies, and much of this research has been conducted out in the open via preprints and conference presentations. Metadata and artifacts needed for a full audit trail.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. connection testing, metadata retrieval, and data preview.
Note that, even though this post focuses on Okta, the presented pattern relies on the SAML 2.0 Prerequisites To build the solution presented in this post, you must have: A developer or licensed Okta account along with administrative access to manage users and permissions. standard and so can be replicated with other identity providers.
This blog post presents an architecture solution that allows customers to extract key insights from Amazon S3 access logs at scale. We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless data integration service, to generate a catalog for access logs and create dashboards for insights.
The CLEA dashboards were built on the foundation of the Well-Architected Lab. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. These ingested datasets are used as a source in CLEA dashboards. Data providers and consumers are the two fundamental users of a CDH dataset.
BI users analyze and present data in the form of dashboards and various types of reports to visualize complex information in an easier, more approachable way. Team members at Lieferando said that “our new real-time dashboards allow us to monitor all major business operations through customized Key Performance Indicators.
Amazon S3 allows you to access diverse data sets, build business intelligence dashboards, and accelerate the consumption of data by adopting a modern data architecture or data mesh pattern on Amazon Web Services (AWS). In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.
The direct query connection relies on the metadata in Glue Data Catalog tables to query data stored in Amazon S3. Below are a few examples of how you can accelerate your data: Skipping indexes – You ingest and index only the metadata of the data stored in Amazon S3. OpenSearch Service creates a new index from the covering index data.
Amazon QuickSight Enterprise edition can integrate with your existing Microsoft Active Directory (AD), providing federated access using Security Assertion Markup Language (SAML) to dashboards. Although, you can connect AD to QuickSight using AWS Directory Service, this blog focuses on federated logon to QuickSight Dashboards.
Today, AI presents an enormous opportunity to turn data into insights and actions, to amplify human capabilities, decrease risk and increase ROI by achieving break through innovations. This includes capturing of the metadata, tracking provenance and documenting the model lifecycle. Where do you go from here?
Solution overview We present an architecture pattern with the following key components: Application logs are streamed into to the data lake, which helps feed hot data into OpenSearch Service in near-real time using OpenSearch Ingestion S3-SQS processing. For a comprehensive overview of OpenSearch Ingestion, see Amazon OpenSearch Ingestion.
The new SAP Datasphere catalog provides data lineage, metadata information, and quick searching capabilities across your SAP landscape. It simplifies complex data structures and relationships, presenting them in a more intuitive and easy-to-understand format for end-users.
They also want to perform the data processing and transformation work in their own account (Account B) to compartmentalize duties and prevent any unintended changes to the source raw data present in the central account (Account A). For more information, see Monitoring dashboards and alarms on Amazon MWAA. secretsmanager ).
Cloudera Enterprise also ships with SDX , a unified metadata layer that provides a data catalog, security policies, access logs, and data lineage. The riskCanvas application suite presents an alternative to in-house developed big data AML solutions. riskCanvas. riskCanvas modules consist of the following: riskCanvas Analytics Suite.
First, the car sales data will be tied into the customer who purchased the car in order to get the customer metadata, such as contact information, age, salary, etc. STEP 4: Generate data visualization dashboards and reports. In order to combine all the data, CDE will correlate common links together. Stay tuned for the next one!
Each record in a hub table is married with metadata that identifies the record’s creation time, originating source system, and unique business key. The presentation marts, also known as the data mart layer, further reorganizes the data for optimized consumption by downstream clients such as business dashboards. Data Vault 2.0
Today, AI presents an enormous opportunity to turn data into insights and actions, to help amplify human capabilities, decrease risk and increase ROI by achieving break through innovations. Users can manage models through dynamic dashboards that track compliance status across defined policies and regulations. Ready to explore more?
Trend 2: Decline of the dashboard. My take: At Amazon, everyone in a meeting sits down at the beginning and reads a full write-up, and then the discussion begins, rather than sitting through an endless PowerPoint presentation during the whole meeting. They focus on real storytelling rather than bullet points.
Clearly, hybrid data presents a massive opportunity and a tough challenge. Common security, governance, metadata, replication, and automation enable CDP to operate as an integrated system. Integration, metadata and governance capabilities glue the individual components together.” .
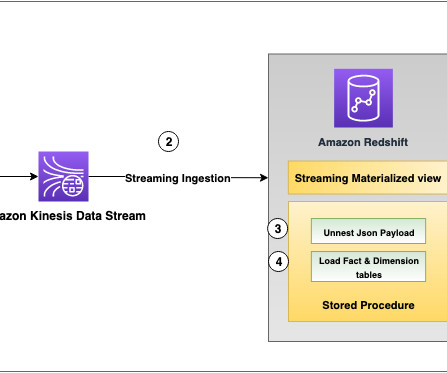
As shown in the following reference architecture, DynamoDB table data changes are streamed into Amazon Redshift through Kinesis Data Streams and Amazon Redshift streaming ingestion for near-real-time analytics dashboard visualization using Amazon QuickSight. Prerequisites You must have the following: An AWS account.
System administrators have access to the built-in Dask dashboard exposed via an Elastic Load Balancer. The OpenSearch Service domain stores metadata on the datasets connected at the Regions. A key feature of Lustre is that only the file system’s metadata is synced. Next, a prompt for further data specifications appears.
This means the creation of reusable data services, machine-readable semantic metadata and APIs that ensure the integration and orchestration of data across the organization and with third-party external data. This means having the ability to define and relate all types of metadata.
BI software offers enterprise businesses the opportunity to connect disparate data sources into one unified source, collate and structure the data, and offer an interface for end-users to extract reports and dashboards that can drive more informed business decisions.
In OpenSearch Dashboards, choose Security in the navigation pane. Navigate to Dev Tools in OpenSearch Dashboards and run the following command: GET _cat/templates This confirms that the scripts were successful. In OpenSearch Dashboards, navigate to the Dashboards page. Choose Import.
Recommendations are reported to Prometheus if you have that setup on your cluster and you can monitor the recommendations through Grafana dashboards and use that to debug and make manual changes to the resource assignments. Results are presented categorized by your Kubernetes namespace and job signature.
Our cutting-edge Shared data experience (SDX) service provides a unified control plane for common security, governance and metadata management on all structured and unstructured data. LLMs in our data visualization tool allow business users to talk to their data using a chatbot and share dashboards and reports with ease.
P.s. If you missed Rev this year, session presentations and recordings can be found here. . A new addition to the Control Center, Projects Portfolio Dashboard, allows data science leaders to easily track and manage projects with a holistic understanding of the latest developments. Project Portfolio Dashboard. In Domino 3.5,
In fact, for most organizations, the collection of dashboards, reports, and analysis tools feels like a chaotic mess. In our role as dashboard and analytical application designers, this is an area that is close to home. Juicebox delivers beautiful data presentations with good design decisions built-in. Easier said than done.
Just managing data without effective governance won’t cut it; analyzing data and presenting a dashboard without trust in the data won’t cut it. Metadata Management Tools (split between some IT-centric and some business-centric solutions). The moving parts include but are not limited to: Master Data Management.
To recap: Here are the top 3 challenges presented by a growing data landscape (or the 3 abilities that are toughest to scale): Ability to find and trust data. Analysts spend countless hours searching for trustworthy data to create dashboards and perform analysis. Yet today, business users confront a high volume of dashboards.
This categorization of data into facts and dimensions, as well as the entity-relationship framework of the dimensional model, presents complex business processes in a way that is easy for analysts to understand. This is the presentation layer and is designed to be requirements-driven and scope-specific subsets of the warehouse data.
Clearly, hybrid data presents a massive opportunity and a tough challenge. Common security, governance, metadata, replication, and automation enable CDP to operate as an integrated system. Integration, metadata and governance capabilities glue the individual components together.” .
Automated data discovery is the key to BI metadata management. It gathers, characterizes, and catalogs the metadata it finds, allowing for faster and more accurate analysis and error reporting. Together, these metadata management tools make quick work of root cause analysis.
Note that there’s not enough room in an article to cover these presentations adequately so I’ll highlight the keynotes plus a few of my favorites. One of my favorite presentations—and the one I kept hearing quoted by attendees —was the day 1 keynote “ Data Science at Netflix: Principles for Speed & Scale” by Michelle Ufford.
Dependence on PBX files impacts connector performance and presents security vulnerabilities, so when we developed the new connector we removed that dependency and used a completely API-based implementation. Support for Power BI on Azure and catalogs: workflow, apps, reports, dashboards, tiles, datasets, dataset fields.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































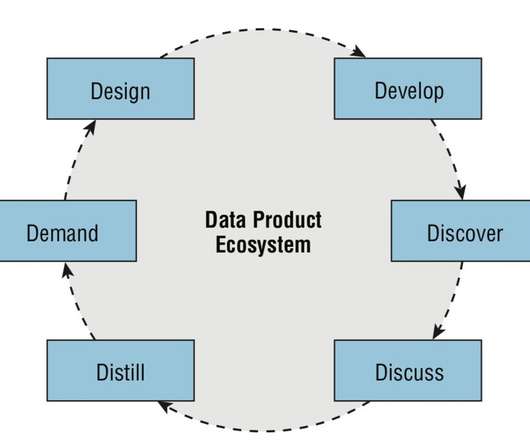















Let's personalize your content