This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball. DataOps just got more intelligent.
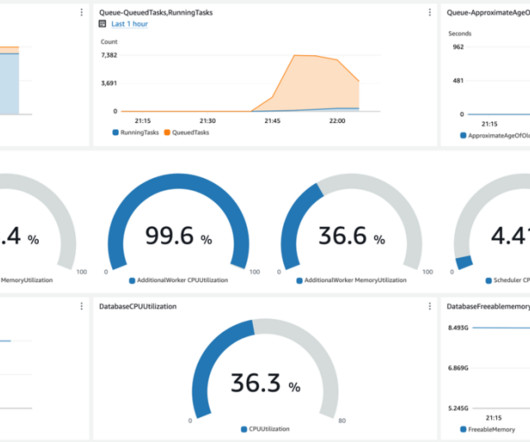
However, it wouldn’t be wise to display an excessive number of metrics on our monitoring dashboards because that could lead to less clarity and slower insights on the cluster. To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits.
Customers can also implement their own custom dashboards in QuickSight. The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights. Choose Query data.
OpenSearch Service stores different types of stored objects, such as dashboards, visualizations, alerts, security roles, index templates, and more, within the domain. Open the Amazon OpenSearch Service dashboard using the OpenSearch Dashboards URL. Jenkins retrieves JSON files from the GitHub repository and performs validation.
In essence, a domain is an integrated data set and a set of views, reports, dashboards, and artifacts created from the data. The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., ….
A catalog or a database that lists models, including when they were tested, trained, and deployed. Metadata and artifacts needed for a full audit trail. A dashboard that provides custom views for all principals (operations, ML engineers, data scientists, business owners). Model operations, testing, and monitoring.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
You can find the visual designer within OpenSearch Dashboards under AI Search Flows , and get started quickly by launching preconfigured flow templates for popular use cases like semantic, multimodal or hybrid search, and retrieval augmented generation (RAG). Lets test our multimodal RAG flow by searching for sunset colored dresses.
Instead, they rely on up-to-date dashboards that help them visualize data insights to make informed decisions quickly. Manually handling repetitive daily tasks at scale poses risks like delayed insights, miscataloged outputs, or broken dashboards. At a large volume, it would require around-the-clock staffing, straining budgets.
The data engineer then emails the BI Team, who refreshes a Tableau dashboard. There are no automated tests , so errors frequently pass through the pipeline. The delays impact delivery of the reports to senior management, who are responsible for making business decisions based on the dashboard. Adding Tests to Reduce Stress.
From customer portals to internal dashboards and mobile apps, this API-driven approach makes enterprise-grade data analysis accessible to everyone in your organization. It reads metadata from your structured data store to generate SQL queries. Choose Test. Choose your Redshift workgroup. Use the IAM role created earlier.
Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. In the Single sign-on section , under SAML Certificates , choose Download for Federation Metadata XML. Test the SSO setup You can now test the SSO setup. Choose Test this application.
For example, dashboarding applications are a very common use case in Redshift customer environments where there is high concurrency and queries require quick, low-latency responses. First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead.
A catalog or a database that lists models, including when they were tested, trained, and deployed. Metadata and artifacts needed for audits: as an example, the output from the components of MLflow will be very pertinent for audits. Traditional software developers have long had tools for managing their projects.
Collaborating closely with our partners, we have tested and validated Amazon DataZone authentication via the Athena JDBC connection, providing an intuitive and secure connection experience for users. Choose Test connection. Choose Test Connection. OutputLocation : Amazon S3 path for storing query results.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
In the context of Data in Place, validating data quality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets. Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors.
As quality issues are often highlighted with the use of dashboard software , the change manager plays an important role in the visualization of data quality. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. 2 – Data profiling.
Data Governance/Catalog (Metadata management) Workflow – Alation, Collibra, Wikis. Observability – Testing inputs, outputs, and business logic at each stage of the data analytics pipeline. Tests catch potential errors and warnings before they are released, so the quality remains high.
Key performance indicators (KPIs) of interest for a call center from a near-real-time platform could be calls waiting in the queue, highlighted in a performance dashboard within a few seconds of data ingestion from call center streams. The near-real-time insights can then be visualized as a performance dashboard using OpenSearch Dashboards.
To build a strong least-privilege security posture, customers also wanted fine-grained access control to manage dashboard permission by user role. If you have integrated IAM Identity Center with your Identity Provider (IdP), you can use existing users and groups mapped to your IdP for this test. Let’s get started!
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
A catalog or a database that lists models, including when they were tested, trained, and deployed. Metadata and artifacts needed for audits. A dashboard that provides custom views for all principals (operations, ML engineers, data scientists, business owners). There are real, not just theoretical, risks and considerations.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. connection testing, metadata retrieval, and data preview.
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated. BI users analyze and present data in the form of dashboards and various types of reports to visualize complex information in an easier, more approachable way.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless data integration service, to generate a catalog for access logs and create dashboards for insights. Using Amazon Athena and Amazon QuickSight, we query and create dashboards for insights.
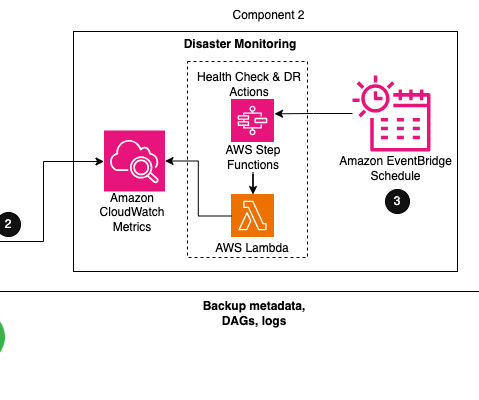
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. AWS publishes our most up-to-the-minute information on service availability on the Service Health Dashboard.
The CLEA dashboards were built on the foundation of the Well-Architected Lab. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. It is possible to define stages (DEV, INT, PROD) in each layer to allow structured release and test without affecting PROD.
First, you’ll create an application in Okta to establish the connection: Sign in to the Okta admin dashboard, expand Applications , then select Applications. Under SAML Signing Certificates , select Actions , and then select View IdP Metadata. Leave the Okta admin dashboard open, you will continue using it in the later steps.
With OpenSearch Serverless, you can configure SAML to enable users to access data through OpenSearch Dashboards using an external SAML identity provider (IdP). In this post, we show you how to configure SAML authentication for OpenSearch Dashboards using IAM Identity Center as its IdP. application. Choose Next.
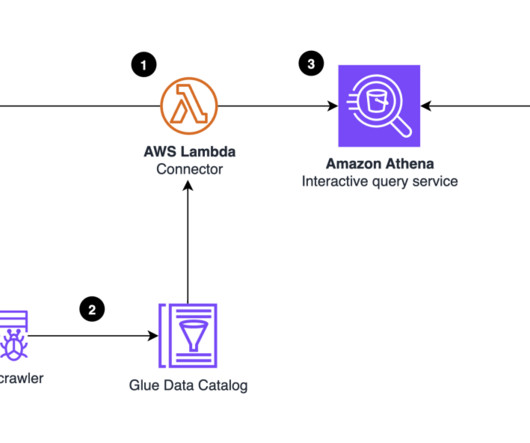
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Table metadata, such as column names and data types, is stored using the AWS Glue Data Catalog. You don’t need to write any code. Choose Next.
Amazon S3 allows you to access diverse data sets, build business intelligence dashboards, and accelerate the consumption of data by adopting a modern data architecture or data mesh pattern on Amazon Web Services (AWS). In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.
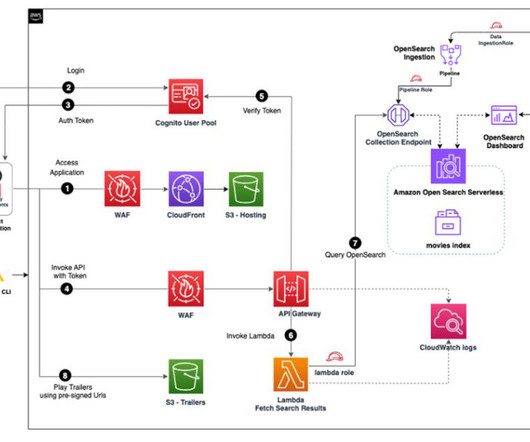
Refer to How can I access OpenSearch Dashboards from outside of a VPC using Amazon Cognito authentication for a detailed evaluation of the available options and the corresponding pros and cons. The workflow consists of the following steps: The user navigates to the OpenSearch Dashboards URL in their browser.
This has serious implications for software testing, versioning, deployment, and other core development processes. You might have millions of short videos , with user ratings and limited metadata about the creators or content. Features like geography and job seniority are critical to getting a good match.
The application supports custom workflows to allow demand and supply planning teams to collaborate, plan, source, and fulfill customer orders, then track fulfillment metrics via persona-based operational and management reports and dashboards. This metadata file is later used to read source file names during processing into the staging layer.
The direct query connection relies on the metadata in Glue Data Catalog tables to query data stored in Amazon S3. Below are a few examples of how you can accelerate your data: Skipping indexes – You ingest and index only the metadata of the data stored in Amazon S3. OpenSearch Service creates a new index from the covering index data.
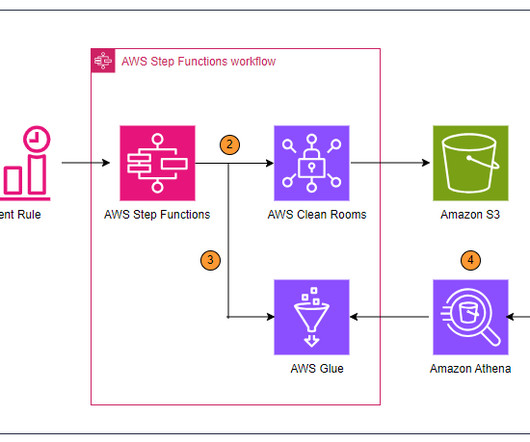
Figure 1: Flow of actions for self-service analytics around data assets stored in relational databases First, the data producer needs to capture and catalog the technical metadata of the data asset. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
It includes intelligence about data, or metadata. The earliest DI use cases leveraged metadata — EG, popularity rankings reflecting the most used data — to surface assets most useful to others. Again, metadata is key. A stewardship dashboard, to track assets most ripe for curation and curation progress.
For more information, see Monitoring dashboards and alarms on Amazon MWAA. The policies attached to the Amazon MWAA role have full access and must only be used for testing purposes in a secure test environment. Otherwise, it will check the metadata database for the value and return that instead. secretsmanager ).
It includes bots for performing network element testing and reduces the need for physical trips to customers sites. Network Alpha Factory also provides data intelligence and the ability to decommission legacy devices.
To ensure the stability of the US financial system, the implementation of advanced liquidity risk models and stress testing using (MI/AI) could potentially serve as a protective measure. Transform stress testing The recent regional bank collapses also highlighted the crucial role stress-testing plays in modeling economic conditions.
OpenSearch Serverless also supports OpenSearch Dashboards, which provides an intuitive interface for analyzing data. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user. mp4, tt0800369.mp4, mp4, and tt0172495.mp4).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content