This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data migration must be performed separately using methods such as S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication. This utility has two modes for replicating Lake Formation and Data Catalog metadata: on-demand and real-time. He is a Bigdata enthusiast and holds 13 AWS Certifications.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
Al needs machine learning (ML), ML needs data science. Data science needs analytics. And they all need lots of data. The takeaway – businesses need control over all their data in order to achieve AI at scale and digital business transformation. Doing data at scale requires a data platform. .
This year, we’re excited to share that Cloudera’s Open Data Lakehouse 7.1.9 release was named a finalist under the category of Business Intelligence and DataAnalytics. Additionally, this release of Open Data Lakehouse includes a mix of Apache Ozone capabilities, like quotas, snapshots, and disaster recovery enhancements.
This is the first post to a blog series that offers common architectural patterns in building real-time data streaming infrastructures using Kinesis Data Streams for a wide range of use cases. Refer to Amazon Kinesis Data Streams integrations for additional details.
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. Expiring old snapshots – This operation provides a way to remove outdated snapshots and their associated data files, enabling Orca to maintain low storage costs.
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Clustering data for better data colocation using z-ordering.
Using existing analytics tools such as Amazon Athena and Amazon QuickSight an organization can gain insight into its estimated carbon footprint. The dataarchitecture diagram below shows an example of how you could use AWS services to calculate and visualize an organization’s estimated carbon footprint.
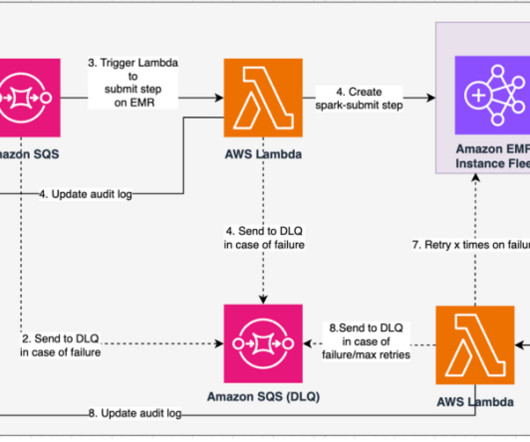
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow. The following figure shows a daily usage KPI.
Furthermore, data events are filtered, enriched, and transformed to a consumable format using a stream processor. The result is made available to the application by querying the latest snapshot. Data streaming enables you to ingest data from a variety of databases across various systems.
By analyzing the historical report snapshot, you can identify areas for improvement, implement changes, and measure the effectiveness of those changes. He focuses on modern dataarchitectures and helping customers accelerate their cloud journey with serverless technologies.
This post is designed to be implemented for a real customer use case, where you get full snapshotdata on a daily basis. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, DataAnalytics, and Data Science.
With scheduled flows, you can choose either full or incremental data transfer: With full transfer, Amazon AppFlow transfers a snapshot of all records at the time of the flow run from the source to the destination. Amit Shah is a cloud based modern dataarchitecture expert and currently leading AWS DataAnalytics practice in Atos.
Many customers migrate their data warehousing workloads to Amazon Redshift and benefit from the rich capabilities it offers, such as the following: Amazon Redshift seamlessly integrates with broader data, analytics, and AI or machine learning (ML) services on AWS , enabling you to choose the right tool for the right job.
You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes. Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run open-source big dataanalytics frameworks without configuring, managing, and scaling clusters or servers.
Amazon EMR stands as a dynamic force in the cloud, delivering unmatched capabilities for organizations seeking robust big data solutions. Its seamless integration, powerful features, and adaptability make it an indispensable tool for navigating the complexities of dataanalytics and ML on AWS.
Apache Iceberg, together with the REST Catalog, dramatically simplifies the enterprise dataarchitecture, reducing the Time to Value, Time to Market, and overall TCO, and driving greater ROI. It provides real time metadata access by directly integrating with the Iceberg-compatible metastore.
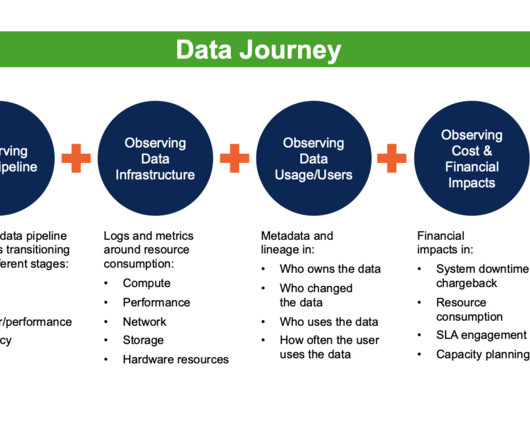
Like an apartment blueprint, Data lineage provides a written document that is only marginally useful during a crisis. This is especially true regarding our one-to-many, producer-to-consumer relationships on our dataarchitecture. Are problems with data tests? Which report tab is wrong? When did it last run? Did it fail?
To capture a more complete picture of the data’s journey, it is important to have a DataOps Observability system in place. Data lineage is static and often lags by weeks or months. Data lineage is often considered static because it is typically based on snapshots of data and metadata taken at a specific time.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content