This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalakeanalytics, machine learning (ML), and data monetization.
We often see requests from customers who have started their data journey by building datalakes on Microsoft Azure, to extend access to the data to AWS services. In such scenarios, data engineers face challenges in connecting and extracting data from storage containers on Microsoft Azure.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. 5 seconds $0.08 8 seconds $0.07 8 seconds $0.02 107 seconds $0.25
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards.
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. Introducing the Salesforce connector for AWS Glue To meet the demands of diverse dataintegration use cases, AWS Glue now supports SaaS connectivity for Salesforce.
DataOps improves the robustness, transparency and efficiency of data workflows through automation. For example, DataOps can be used to automate dataintegration. Previously, the consulting team had been using a patchwork of ETL to consolidate data from disparate sources into a datalake.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT dataanalytics.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. She is passionate about helping customers build datalakes using ETL workloads.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Dataanalytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
About the Authors Samir Patel is a Senior Data Architect at Amazon Web Services, where he specializes in OpenSearch, dataanalytics, and cutting-edge generative AI technologies. Samir works directly with enterprise customers to design and build customized solutions catered to their dataanalytics and cybersecurity needs.
AWS has invested in a zero-ETL (extract, transform, and load) future so that builders can focus more on creating value from data, instead of having to spend time preparing data for analysis. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
Kaplan data engineers empower dataanalytics using Amazon Redshift and Tableau. The infrastructure provides an analytics experience to hundreds of in-house analysts, data scientists, and student-facing frontend specialists. He works with Data Engineers at Kaplan for building datalakes using AWS Services.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. options(**additional_options).mode("append").save(s3_output_folder)
Reading Time: 2 minutes Today, many businesses are modernizing their on-premises data warehouses or cloud-based datalakes using Microsoft Azure Synapse Analytics. Unfortunately, with data spread.
We have defined all layers and components of our design in line with the AWS Well-Architected Framework DataAnalytics Lens. Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These upstream data sources constitute the data producer components.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
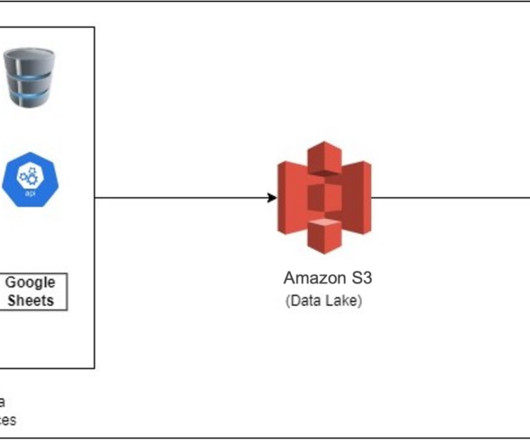
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Conclusion In this post, we walked you through the process of using Amazon AppFlow to integratedata from Google Ads and Google Sheets.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless.
Which type(s) of storage consolidation you use depends on the data you generate and collect. . One option is a datalake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Set up unified data governance rules and processes.
In the dataanalytics space, organizations often deal with many tables in different databases and file formats to hold data for different business functions. Apache Hudi supports ACID transactions and CRUD operations on a datalake. You don’t alter queries separately in the datalake. and save it.
But when it comes to getting the most value out of hybrid cloud, one of the most crucial capabilities required is data replication and synchronization—what enables businesses to efficiently capture data changes and unify various data stores while ensuring low latency, high availability, and dataintegrity.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their dataanalytics processes. Overall, DataOps is an essential component of modern data-driven organizations. Query> DataOps. Query> Write an essay on DataOps.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Kamen Sharlandjiev is a Sr.
Sessions ANT203 | What’s new in Amazon Redshift Watch this session to learn about the newest innovations within Amazon Redshift—the petabyte-scale AWS Cloud data warehousing solution. Easily build and train machine learning models using SQL within Amazon Redshift to generate predictive analytics and propel data-driven decision-making.
Dataintegration is the foundation of robust dataanalytics. It encompasses the discovery, preparation, and composition of data from diverse sources. In the modern data landscape, accessing, integrating, and transforming data from diverse sources is a vital process for data-driven decision-making.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based dataintegration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for big dataanalytics and machine learning workloads.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
Many customers need an ACID transaction (atomic, consistent, isolated, durable) datalake that can log change data capture (CDC) from operational data sources. There is also demand for merging real-time data into batch data. Delta Lake framework provides these two capabilities. option("header",True).schema(schema).load("s3://"+
The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. Read: The first capability of a data fabric is a semantic knowledge data catalog, but what are the other 5 core capabilities of a data fabric? 11 May 2021. .
In this post, we explore how to use the AWS Glue native connector for Teradata Vantage to streamline dataintegrations and unlock the full potential of your data. Businesses often rely on Amazon Simple Storage Service (Amazon S3) for storing large amounts of data from various data sources in a cost-effective and secure manner.
Third, AWS continues adding support for more data sources including connections to software as a service (SaaS) applications, on-premises applications, and other clouds so organizations can act on their data. Visit Dataintegration with AWS to learn more.
The application gets prompt templates from an S3 datalake and creates the engineered prompt. The user interaction is stored in a datalake for downstream usage and BI analysis. EMEA Data & AI PSA, based in Madrid. In his current role, Angel helps partners develop businesses centered on Data and AI.
It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless dataintegration is a key requirement in a modern data architecture to break down data silos. He is passionate about distributed computing and everything and anything about the data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content