This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
From the Unified Studio, you can collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics. You can use a simple visual interface to compose flows that move and transform data and run them on serverless compute. For Key , choose venuestate.
We have discussed the compelling role that dataanalytics plays in various industries. In December, we shared five key ways that dataanalytics can help businesses grow. The gaming industry is among those most affected by breakthroughs in dataanalytics. Dataintegrity control.
OpenSearch Service seamlessly integrates with other AWS offerings, providing a robust solution for building scalable and resilient search and analytics applications in the cloud. In the event of data loss or system failure, these snapshots will be used to restore the domain to a specific point in time.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT dataanalytics.
This is part of Ontotext’s AI-in-Action initiative aimed at enabling data scientists and engineers to benefit from the AI capabilities of our products. Ontotext’s Relation and Event Detector (RED) is designed to assess and analyze the impact of market-moving events. Why do risk and opportunity events matter?
The development of business intelligence to analyze and extract value from the countless sources of data that we gather at a high scale, brought alongside a bunch of errors and low-quality reports: the disparity of data sources and data types added some more complexity to the dataintegration process.
In this post, we explore how to use the AWS Glue native connector for Teradata Vantage to streamline dataintegrations and unlock the full potential of your data. Businesses often rely on Amazon Simple Storage Service (Amazon S3) for storing large amounts of data from various data sources in a cost-effective and secure manner.
The important thing to realize is that these problems are not the fault of the people working in the data organization. The dataanalytics lifecycle is a factory, and like other factories, it can be optimized with techniques borrowed from methods like lean manufacturing. Don’t be a hero; make heroism a rare event.
If we talk about Big Data, data visualization is crucial to more successfully drive high-level decision making. Big Dataanalytics has immense potential to help companies in decision making and position the company for a realistic future. There is little use for dataanalytics without the right visualization tool.
But I think it has another implication – the word unprecedented kind of admonishes any people or organizations that are either too comfortable with, you know, our ignorant of history or too intellectually lazy to comprehend how even one event can deterministically lead to another. But it’s not a real easy process. Aruna: Got it.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. You will load the eventdata from the SFTP site, join it to the venue data stored on Amazon S3, apply transformations, and store the data in Amazon S3.
It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain dataintegrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their dataanalytics processes. Overall, DataOps is an essential component of modern data-driven organizations. Query> DataOps. Query> Write an essay on DataOps.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights. These logs can track activity, such as data access patterns, lifecycle and management activity, and security events.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
With the right Big Data Tools and techniques, organizations can leverage Big Data to gain valuable insights that can inform business decisions and drive growth. What is Big Data? What is Big Data? It is an ever-expanding collection of diverse and complex data that is growing exponentially.
The upstream data pipeline is a robust system that integrates various data sources, including Amazon Kinesis and Amazon Managed Streaming for Apache Kafka (Amazon MSK) for handling clickstream events, Amazon Relational Database Service (Amazon RDS) for delta transactions, and Amazon DynamoDB for delta game-related information.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications. You can see how CDC performs create event by looking at this example here.
You will also want to apply incremental updates with change data capture (CDC) from the source system to the destination. To make data-driven decisions in a timely manner, you need to account for missed records and backpressure, and maintain event ordering and integrity, especially if the reference data also changes rapidly.
Srinivasan will share Petco’s ongoing data journey at CIO’s Future of Data Summit , taking place virtually May 10-11. Focusing on creating the intelligent organization, the event will gather technology executives to discuss both strategy and concrete implementation tactics. The event is free to attend for qualified attendees.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. IBM Data Governance IBM Data Governance leverages machine learning to collect and curate data assets.
By consolidating and enriching data assets from disparate sources across the enterprise, these next-gen warehouses allow businesses to deploy advanced analytics – the autonomous (or semi-autonomous) examination of data using cutting-edge techniques such as machine learning and complex event processing.
Below, we have laid down 5 different ways that software development can leverage Big Data. With the dataanalytics software, development teams are able to organize, harness and use data to streamline their entire development process and even discover new opportunities. DataIntegration. Improving Efficiency.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
The data in the machine-readable files can provide valuable insights to understand the true cost of healthcare services and compare prices and quality across hospitals. The availability of machine-readable files opens up new possibilities for dataanalytics, allowing organizations to analyze large amounts of pricing data.
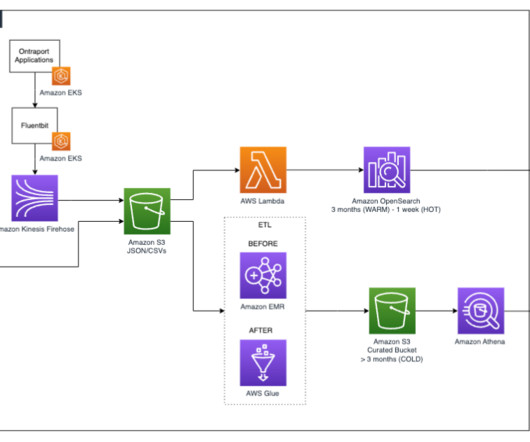
Serverless services like AWS Glue minimize the need to think about servers and focus on offering additional productivity and DataOps tooling for accelerating data pipeline development. For example, email logs alone record 3–4 events for every one of the 15–20 million messages Ontraport sends on behalf of their clients each day.
Working towards delivering a strong customer experience and shortening time to market, the organization sought to create a centralized repository of high-quality data which could also allow them to stream and conduct real-time dataanalytics to rapidly derive actionable insights. .
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. To achieve this, Aruba used Amazon S3 Event Notifications. Regional distribution On average, Aruba transfers approximately 100 files, with total size ranging from 1.5–2
In the dataanalytics space, organizations often deal with many tables in different databases and file formats to hold data for different business functions. We trigger a Lambda function with the source table name as an event so that the corresponding parameters of the source table are read from DynamoDB. and save it.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data.
AWS Glue is a fully managed, serverless dataintegration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell , Spark , or Ray ). To use it you need to enable Spark UI event logs for your job runs. Angel Conde Manjon is a Sr.
IBM, a pioneer in dataanalytics and AI, offers watsonx.data, among other technologies, that makes possible to seamlessly access and ingest massive sets of structured and unstructured data. AWS’s secure and scalable environment ensures dataintegrity while providing the computational power needed for advanced analytics.
As customers accelerate their migrations to the cloud and transform their businesses, some find themselves in situations where they have to manage dataanalytics in a multi-cloud environment, such as acquiring a company that runs on a different cloud provider. We use Athena to run queries on data stored on Google Cloud Storage.
This post proposes an automated solution by using AWS Glue for automating the PostgreSQL data archiving and restoration process, thereby streamlining the entire procedure. Additionally, you can set up this AWS Glue workflow to be triggered on a schedule, on demand, or with an Amazon EventBridge event.
Data monetization strategy: Managing data as a product Every organization has the potential to monetize their data; for many organizations, it is an untapped resource for new capabilities. But few organizations have made the strategic shift to managing “data as a product.”
The party has just begun A recent research paper identified big dataanalytics as a core driver of operational resilience for SMBs. With better dataintegration and analysis, SMBs can enable organizational knowledge-sharing, stay competitive, and spur innovation.
A Data Journey supplies real-time statuses and alerts on start times, processing durations, test results, and infrastructure events, among other metrics. With this information, data teams can know if everything ran on time and without errors and immediately identify the parts that didn’t.
Due to the convergence of events in the dataanalytics and AI landscape, many organizations are at an inflection point. This capability will provide data users with visibility into origin, transformations, and destination of data as it is used to build products. Dataintegration. Start a trial.
” “How does this region/event compare to other regions/events?” ” To do so, KWG draws from over 30 fully integrated and semantically homogenized data layers. As a result of these data quality issues, the need for integrity checks arises. ” “What happened here before?”
Another example is building monitoring dashboards that aggregate the status of your DAGs across multiple Amazon MWAA environments, or invoke workflows in response to events from external systems, such as completed database jobs or new user signups. The following screenshots show an example of the auto scaling event. His secret weapon?
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, dataintegrity is of paramount importance.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Data processing Raw data is often cluttered with duplicates and irregular formats.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content