This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
To handle such scenarios you need a transalytical graph database – a database engine that can deal with both frequent updates (OLTP workload) as well as with graph analytics (OLAP). Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. Metadata about Relationships Come in Handy. Schemas are powerful.
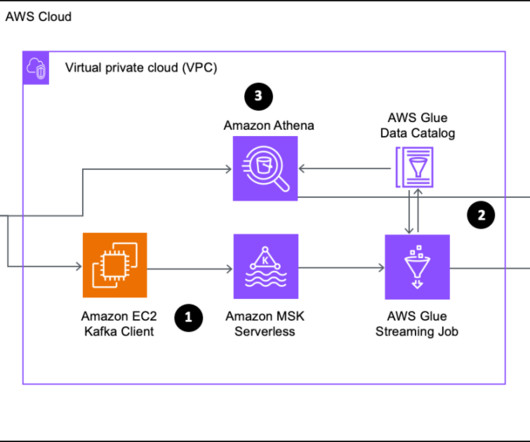
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
The results of our new research show that organizations are still trying to master data governance, including adjusting their strategies to address changing priorities and overcoming challenges related to data discovery, preparation, quality and traceability. And close to 50 percent have deployed data catalogs and business glossaries.
In this post, we walk you through the top analytics announcements from re:Invent 2024 and explore how these innovations can help you unlock the full potential of your data. S3 Metadata is designed to automatically capture metadata from objects as they are uploaded into a bucket, and to make that metadata queryable in a read-only table.
The program must introduce and support standardization of enterprise data. Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred dataintegration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
For sectors such as industrial manufacturing and energy distribution, metering, and storage, embracing artificial intelligence (AI) and generative AI (GenAI) along with real-time dataanalytics, instrumentation, automation, and other advanced technologies is the key to meeting the demands of an evolving marketplace, but it’s not without risks.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights. Both the user data and logs buckets must be in the same AWS Region and owned by the same account.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. This concept makes Iceberg extremely versatile. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
If we talk about Big Data, data visualization is crucial to more successfully drive high-level decision making. Big Dataanalytics has immense potential to help companies in decision making and position the company for a realistic future. There is little use for dataanalytics without the right visualization tool.
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. 2 GB into the landing zone daily.
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. 11 May 2021. . 3 March 2022.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structured data, which is managed in well-defined rows and columns, unstructured data is stored as objects.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. An entity can act both as a producer of data assets and as a consumer of data assets.
Automate code generation : Alleviate the need for developers to hand code connections from data sources to target schema. It also makes it easier for business analysts, data architects, ETL developers, testers and project managers to collaborate for faster decision-making.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Then, you transform this data into a concise format.
The age of Big Data inevitably brought computationally intensive problems to the enterprise. Central to today’s efficient business operations are the activities of data capturing and storage, search, sharing, and dataanalytics. With semantic metadata, enterprise data gets linked to one another and to external sources.
Business intelligence (BI) analysts transform data into insights that drive business value. If you score a 70% or higher on all three exams, you’ll be certified at the Mastery level, which demonstrates your ability to lead a team and mentor others, according to TDWI.
Loading complex multi-point datasets into a dimensional model, identifying issues, and validating dataintegrity of the aggregated and merged data points are the biggest challenges that clinical quality management systems face. It is a data modeling methodology designed for large-scale data warehouse platforms.
Octopai’s real-time capabilities provide a transparent, up-to-the-moment view of dataintegrations across platforms like Airflow, Azure Data Factory, Snowflake, Redshift, and Azure Synapse. Instead, it’s an intuitive journey where every step of data is transparent and trustworthy.
The data in the machine-readable files can provide valuable insights to understand the true cost of healthcare services and compare prices and quality across hospitals. The availability of machine-readable files opens up new possibilities for dataanalytics, allowing organizations to analyze large amounts of pricing data.
Amazon Redshift has been constantly innovating over the last decade to give you a modern, massively parallel processing cloud data warehouse that delivers the best price-performance, ease of use, scalability, and reliability. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
As customers accelerate their migrations to the cloud and transform their businesses, some find themselves in situations where they have to manage dataanalytics in a multi-cloud environment, such as acquiring a company that runs on a different cloud provider. For instructions, refer to Setting up databases and tables in AWS Glue.
AWS Glue, with its ability to process data using Apache Spark and connect to various data sources, is a suitable solution for addressing the challenges of accessing data across multiple cloud environments. Athena can then use this metadata to query and analyze the Delta table seamlessly.
The catalog stores the asset’s metadata in RDF. This allows keeping a well-defined representation of the metadata of each asset and enables using a SPARQL endpoint to query it. Towards that end authors introduce a system for integrity checks for building automation applications and using more reliable data for dataanalytics processes.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.)
Cloudera provides a unified platform with multiple data apps and tools, big data management, hybrid cloud deployment flexibility, admin tools for platform provisioning and control, and a shared data experience for centralized security, governance, and metadata management.
Due to the convergence of events in the dataanalytics and AI landscape, many organizations are at an inflection point. IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. Dataintegration. Start a trial.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Analyzing XML files can help organizations gain insights into their data, allowing them to make better decisions and improve their operations. Analyzing XML files can also help in dataintegration, because many applications and systems use XML as a standard data format. This approach optimizes the use of your XML files.
The engines must facilitate the advanced dataintegration and metadatadata management scenarios where an EKG is used for data fabrics or otherwise serves as a data hub between diverse data and content management systems.
In addition, using Apache Iceberg’s metadata tables proved to be very helpful in identifying issues related to the physical layout of Iceberg’s tables, which can directly impact query performance. These robust capabilities ensure that data within the data lake remains accurate, consistent, and reliable.
Streaming data has become an indispensable resource for organizations worldwide because it offers real-time insights that are crucial for dataanalytics. The escalating velocity and magnitude of collected data has created a demand for real-time analytics. This table acts as a metadata layer for the data.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time dataanalytics, considering the growing velocity and volume of data being collected. For more information about checkpointing, see the appendix at the end of this post.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of data ingestion, processing, cleansing, aggregation, and serving. Monitor and identify data quality issues closer to the source to mitigate the potential impact on downstream processes or workloads.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, data lakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
With the new REST API, you can now invoke DAG runs, manage datasets, or get the status of Airflow’s metadata database, trigger, and scheduler—all without relying on the Airflow web UI or CLI. She is passionate about dataanalytics and networking. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert.
An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 data lake hourly with incremental data. The AWS Glue job can transform the raw data in Amazon S3 to Parquet format, which is optimized for analytic queries. All the metadata of the tables is stored in the AWS Glue Data Catalog, including the Hudi tables.
Data Literacy, training, coordination, collaboration 8. Data Management Infrastructure/Data Fabric 5. DataIntegration tactics 4. Metadata Strategy 3. CDO (data officer) 2. Figure 3: The Data and Analytics (infrastructure) Continuum. Business Innovation with D&A 6.
Reading Time: 3 minutes Today, the most innovative and successful organizations leverage data to increase revenue, minimize expenses, and deliver products and services that meet the needs of their customers. To be truly “data-driven,” an organization must view data as more than a byproduct. The post How to Shop for Data?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content