This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post focuses on introducing an active-passive approach using a snapshot and restore strategy. Snapshot and restore in OpenSearch Service The snapshot and restore strategy in OpenSearch Service involves creating point-in-time backups, known as snapshots , of your OpenSearch domain.
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
That’s a fair point, and it places emphasis on what is most important – what best practices should data teams employ to apply observability to dataanalytics. We see data observability as a component of DataOps. In our definition of data observability, we put the focus on the important goal of eliminating data errors.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue.
Use the reindex API operation The _reindex operation snapshots the index at the beginning of its run and performs processing on a snapshot to minimize impact on the source index. The source index can still be used for querying and processing the data. Mikhail specializes in dataanalytics services.
Using Apache Iceberg’s compaction results in significant performance improvements, especially for large tables, making a noticeable difference in query performance between compacted and uncompacted data. These files are then reconciled with the remaining data during read time.
Using Amazon MSK, we securely stream data with a fully managed, highly available Apache Kafka service. Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, dataintegrity is of paramount importance.
With scheduled flows, you can choose either full or incremental data transfer: With full transfer, Amazon AppFlow transfers a snapshot of all records at the time of the flow run from the source to the destination. He’s on a mission to make life easier for customers who are facing complex dataintegration challenges.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time dataanalytics, considering the growing velocity and volume of data being collected. Step 6} $ REGISTRY_NAME={VAL_OF_GlueSchemaRegistryName - Ref. Step 6} $ SCHEMA_NAME={VAL_OF_SchemaName– Ref.
Select Augmented Analytics with Anomaly Monitoring and Alerts! Anomaly detection in dataanalytics is defined as the identification of rare items, events or observations which deviate significantly from the majority of the data and do not conform to a well-defined notion of normal behavior.
But what is the state of AI and Big Data, right now? In this article, we take a snapshot look at the world of information processing as it stands in the present. Big data and AI have what is referred to as a synergistic relationship. Data Democratization. Data is no longer solely the asset of very large businesses.
Running HBase on Amazon S3 has several added benefits, including lower costs, data durability, and easier scalability. And during HBase migration, you can export the snapshot files to S3 and use them for recovery. HBase provided by other cloud platforms doesn’t support snapshots.
Because core data has resided in LeeSar’s legacy system for more than a decade, “a fair amount of effort was required to ensure we were bringing clean data into the Oracle platform, so it has required an IT and functional team partnership to ensure the data is accurate as it is migrated.”
To capture a more complete picture of the data’s journey, it is important to have a DataOps Observability system in place. Data lineage is static and often lags by weeks or months. Data lineage is often considered static because it is typically based on snapshots of data and metadata taken at a specific time.
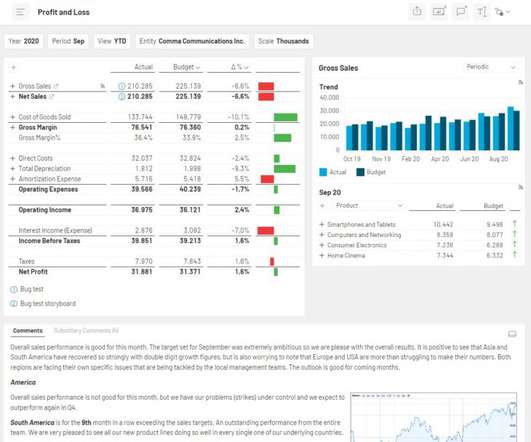
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. Step 6: Drill Into the Data. Moreover, they’re constantly updated as new information becomes available.
Microsoft Excel offers flexibility, but it’s missing so many of the elements required to assemble data quickly and easily for powerful (and accurate) financial narratives. The reports created within static spreadsheets are based on a snapshot of reality, taken the moment the data was exported from ERP.
And that is only a snapshot of the benefits your finance users will enjoy with Angles for Deltek. Angles has been effective to providing us real-time financial and operational data that otherwise we would have to manually parse together. Tools to configure custom views for the remaining 20% of your team’s operational reporting needs.
Every time you do an export from your ERP system, you’re taking a snapshot of the data that only reflects a single moment in time. A static (therefore outdated) view of the business : Another major problem with manual processes is that they don’t reflect what’s happening in the business in real time.
All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. Perhaps just as importantly, they lead to a time delay between the moment something happens in the business and the time it shows up on a report.
There is yet another problem with manual processes: the resulting reports only reflect a snapshot in time. As soon as you export data from your ERP software or other business systems, it’s obsolete.
The source data in this scenario represents a snapshot of the information in your ERP system. Researching that question requires substantial additional effort if your organization uses manual planning and budgeting processes. It’s not updated when someone records new transactions, and you can’t drill down to the details.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content