This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big dataanalytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Determine your preparedness.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Clean up To avoid incurring future charges, delete the resources you created.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
A domain has an important job and a dedicated team – five to nine members – who develop an intimate knowledge of data sources, data consumers and functional nuances. For example, managing ordered data dependencies, inter-domain communication, shared infrastructure, and incoherent workflows. Rise of the DataOps Engineer.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Next, the merged data is filtered to include only a specific geographic region. Then the transformed output data is saved to Amazon S3 for further processing in future.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau. datazone_env_twinsimsilverdata"."cycle_end";')
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. Samir works directly with enterprise customers to design and build customized solutions catered to their dataanalytics and cybersecurity needs.
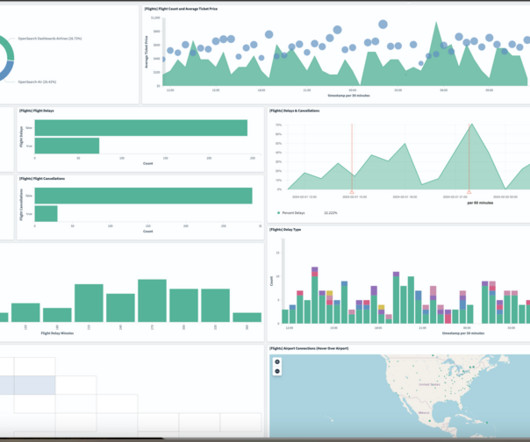
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Dataanalytics on operational data at near-real time is becoming a common need. Then we can query the data with Amazon Athena visualize it in Amazon QuickSight.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. options(**additional_options).mode("append").save(s3_output_folder)
You need to determine if you are going with an on-premise or cloud-hosted strategy. These basic steps will enable you to deliver agile dataanalytics and BI methodology into practice, no matter the size of your company. Top 10 Tips For Agile BI & Analytics Development. Construction Iterations.
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. Here, Dickson sees data generated from its industrial machines being very productive.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Well, let’s find out. Artificial intelligence (AI). Easy to use.
It hosts over 150 big dataanalytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery. With this functionality, business units can now leverage big dataanalytics to develop better and faster insights to help achieve better revenues, higher productivity, and decrease risk. .
It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Introducing the SFTP connector for AWS Glue The SFTP connector for AWS Glue simplifies the process of connecting AWS Glue jobs to extract data from SFTP storage and to load data into SFTP storage.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). About the authors Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
They recently needed to do a monthly load of 140 TB of uncompressed healthcare claims data in under 24 hours after receiving it to provide analysts and data scientists with up-to-date information on a patient’s healthcare journey. This data volume is expected to increase monthly and is fully refreshed each month.
This involves creating VPC endpoints in both the AWS and Snowflake VPCs, making sure data transfer remains within the AWS network. Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC. He has helped technology companies design and implement dataanalytics solutions and products.
For Host , enter events.PagerDuty.com. At AWS, he is focused on DataLake implementations, and Search, Analytical workloads using Amazon OpenSearch Service. Vivek Shrivastava is a Principal Data Architect, DataLake in AWS Professional Services. For Channel type , choose Custom webhook.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
Next up: AI and datalake decisions. To that end, UAB’s next step is to tackle big decisions around expanding its AI and dataanalytics platforms, says Carver, who is not handling the long-term planning alone. UAB is a big Microsoft customer but also has master service agreements with Amazon and Google, Carver says.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises.
The challenges include not only the technical intricacies of data management but also concerns related to data security, privacy, and compliance with evolving regulations. sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint hosts: [ "[link]. > region: " >" # Provide a Role ARN with access to the bucket.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) datalakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machine learning (ML) from your datalake to generate insights on your data.
This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. An exciting slate of presentations took them on a journey from why to how they should use dataanalytics to optimize their operations successfully and maximize their business opportunities.
Furthermore, TDC Digital had not used any cloud storage solution and experienced latency and downtime while hosting the application in its data center. TDC Digital is excited about its plans to host its IT infrastructure in IBM data centers, offering better scalability, performance and security.
Building datalakes from continuously changing transactional data of databases and keeping datalakes up to date is a complex task and can be an operational challenge. You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. This solution uses Amazon Aurora MySQL hosting the example database salesdb. Vishal Khatri is a Sr.
Set up EMR Studio In this step, we demonstrate the actions needed from the datalake administrator to set up EMR Studio enabled for trusted identity propagation and with IAM Identity Center integration. On the Lake Formation console, choose Datalake permissions under Permissions in the navigation pane.
About the Authors Raj Patel is AWS Lead Consultant for DataAnalytics solutions based out of India. He specializes in building and modernising analytical solutions. His background is in data warehouse/datalake – architecture, development and administration.
The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse. About the Authors Ismail Makhlouf is a Senior Specialist Solutions Architect for DataAnalytics at AWS.
In this post, we share how Poshmark improved CX and accelerated revenue growth by using a real-time analytics solution. High-level challenge: The need for real-time analytics Previous efforts at Poshmark for improving CX through analytics were based on batch processing of analyticsdata and using it on a daily basis to improve CX.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. We saw a record number of entries and incredible examples of how customers were using Cloudera’s platform and services to unlock the power of data.
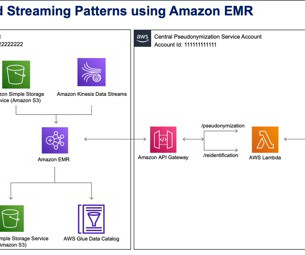
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. For an overview of how to build an ACID compliant datalake using Iceberg, refer to Build a high-performance, ACID compliant, evolving datalake using Apache Iceberg on Amazon EMR.
We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources. Vijay Bagur is a Sr.
Verify the job by running the following command: kubectl get pods -n data-team-a Enable access to the Spark UI The Spark UI is an important tool for data engineers because it allows you to track the progress of tasks, view detailed job and stage information, and analyze resource utilization to identify bottlenecks and optimize your code.
Users can also raise requests to producers to improve the way the data is presented or to enrich the data with new data points for generating a higher business value. At the same time, each team can also map other catalogs to their own account and use their own data, which they produce along with the data from other accounts.
There are now tens of thousands of instances of these Big Data platforms running in production around the world today, and the number is increasing every year. Many of them are increasingly deployed outside of traditional data centers in hosted, “cloud” environments. Streaming dataanalytics. .
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a datalake, transformed, and made available for analytics, machine learning (ML), and visualization. The job runs in the target account.
2007: Amazon launches SimpleDB, a non-relational (NoSQL) database that allows businesses to cheaply process vast amounts of data with minimal effort. The platform is built on S3 and EC2 using a hosted Hadoop framework. An efficient big data management and storage solution that AWS quickly took advantage of. To be continued.
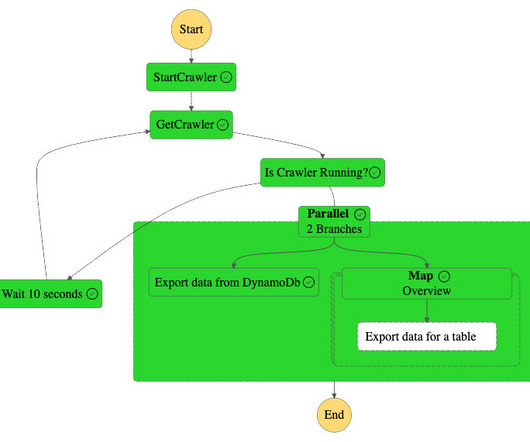
Solution overview One of the common functionalities involved in data pipelines is extracting data from multiple data sources and exporting it to a datalake or synchronizing the data to another database. There are multiple tables related to customers and order data in the RDS database.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content