This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data warehousing, business intelligence, dataanalytics, and AI services are all coming together under one roof at Amazon Web Services. It combines SQL analytics, data processing, AI development, data streaming, business intelligence, and search analytics.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. 5 seconds $0.08 8 seconds $0.07 8 seconds $0.02 107 seconds $0.25
Though you may encounter the terms “datascience” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
Apache Iceberg is an open table format for very large analytic datasets. It manages large collections of files as tables, and it supports modern analyticaldatalake operations such as record-level insert, update, delete, and time travel queries. Mikhail specializes in dataanalytics services.
This book is not available until January 2022, but considering all the hype around the data mesh, we expect it to be a best seller. In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Recently, I gave a Make Your Data Work Monday webinar on the complexities of the data sources for datascience in Azure, and I thought it important enough to turn into an actual post. How can you differentiate the different opportunities to store your data in Azure?
Applying artificial intelligence (AI) to dataanalytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big dataanalytics powered by AI.
Instead of having a giant, unwieldy datalake , the data mesh breaks up the data and workflow assets into controllable and composable domains with inherent interdependencies. Domains are built from raw data and/or the output of other domains.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Dataanalytics on operational data at near-real time is becoming a common need. Then we can query the data with Amazon Athena visualize it in Amazon QuickSight.
A DataOps process hub offers a way for business analytics teams to cope with fast-paced requirements without expanding staff or sacrificing quality. Analytics Hub and Spoke. The dataanalytics function in large enterprises is generally distributed across departments and roles. DataOps Process Hub.
Carhartt’s signature workwear is near ubiquitous, and its continuing presence on factory floors and at skate parks alike is fueled in part thanks to an ongoing digital transformation that is advancing the 133-year-old Midwest company’s operations to make the most of advanced digital technologies, including the cloud, dataanalytics, and AI.
Reading Time: 2 minutes The data lakehouse has emerged as a powerful and popular data architecture, combining the scale of datalakes with the management features of data warehouses. It promises a unified platform for storing and analyzing structured and unstructured data, particularly for.
This post explores how you can use BladeBridge , a leading data environment modernization solution, to simplify and accelerate the migration of SQL code from BigQuery to Amazon Redshift. Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights.
And as businesses contend with increasingly large amounts of data, the cloud is fast becoming the logical place where analytics work gets done. For many enterprises, Microsoft Azure has become a central hub for analytics. Azure Data Explorer. Azure DataLakeAnalytics.
In today’s data-driven world , organizations are constantly seeking efficient ways to process and analyze vast amounts of information across datalakes and warehouses. This post will showcase how this data can also be queried by other data teams using Amazon Athena. Verify that you have Python version 3.7
The Salesforce Trust Intelligence Platform (TIP) log platform team is responsible for data pipeline and datalake infrastructure, providing log ingestion, normalization, persistence, search, and detection capability to ensure Salesforce is safe from threat actors. This is the bronze layer of the TIP datalake.
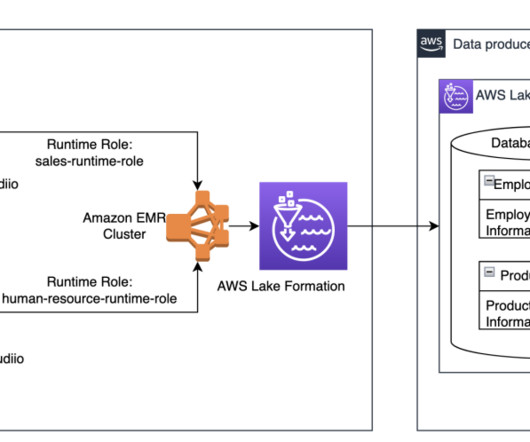
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These upstream data sources constitute the data producer components.
One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform. These Snowflake accelerators reduce the time to analytics for your users at all levels so you can make data-driven decisions faster. Security DataLake. Snowflake Health Check.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or DataScience.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale dataanalytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and datascience applications written in R, Python, Scala, and PySpark. This helps you reduce operational overhead.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale dataanalytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
This post was co-written with Rajiv Arora, Director of DataScience Platform at Gilead Life Sciences. Gilead Sciences, Inc. Create a datalake external schema and table in Redshift Serverless. You can query datalake tables directly from Amazon Redshift Query Editor v2 or your favorite SQL editors.
Reading Time: 2 minutes Today, many businesses are modernizing their on-premises data warehouses or cloud-based datalakes using Microsoft Azure Synapse Analytics. Unfortunately, with data spread.
He announced his departure on LinkedIn and reflected on some of the achievements during the five years with the department which included building an advanced dataanalytics platforms utilising data warehouse, a datalake, datascience containers and supporting visualisation tools. IT Leadership
It hosts over 150 big dataanalytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery. With this functionality, business units can now leverage big dataanalytics to develop better and faster insights to help achieve better revenues, higher productivity, and decrease risk. .
When global technology company Lenovo started utilizing dataanalytics, they helped identify a new market niche for its gaming laptops, and powered remote diagnostics so their customers got the most from their servers and other devices. Without those templates, it’s hard to add such information after the fact.”
Most organizations struggle to unlock datascience in the enterprise. To that end, Cloudera offers the DataScience Workbench, a collaborative, scalable, and highly extensible platform for data exploration, analysis, modeling, and visualization. That friction is what defines the new datascience iron triangle.
With a solution based on Cloudera DataScience Workbench (CDSW), the bank implemented a more streamlined loan approval process that reduced processing time from a week to just hours. As a result of this innovative data solution, the company helped customers while keeping its default rate low. .
Presto was able to achieve this level of scalability by completely separating analytical compute from data storage. Presto is an open source distributed SQL query engine for dataanalytics and the data lakehouse, designed for running interactive analytic queries against datasets of all sizes, from gigabytes to petabytes.
Another IDC study showed that while 2/3 of respondents reported using AI-driven dataanalytics, most reported that less than half of the data under management is available for this type of analytics. from 2022 to 2026.
Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. Solution overview Data and metadata discovery is one of the primary requirements in dataanalytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis.
The secure connectivity pattern prevents data transfers over the public internet, enhancing data privacy and security. Combining AWS data integration services like AWS Glue with data platforms like Snowflake allows you to build scalable, secure datalakes and pipelines to power analytics, BI, datascience, and ML use cases.
The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse. About the Authors Ismail Makhlouf is a Senior Specialist Solutions Architect for DataAnalytics at AWS.
CSP was recently recognized as a leader in the 2022 GigaOm Radar for Streaming Data Platforms report. Building real-time dataanalytics pipelines is a complex problem, and we saw customers struggle using processing frameworks such as Apache Storm, Spark Streaming, and Kafka Streams. . Without context, streaming data is useless.”
In essence, it’s the foundation for user-centric data analysis in modern apps, because it’s the layer that translates technical assets into business-friendly terms that enable users to extract actionable insights from data. The scope of dataanalytics has grown, and more user personas are now seeking to extract insights themselves.
A data lakehouse is an emerging data management architecture that improves efficiency and converges data warehouse and datalake capabilities driven by a need to improve efficiency and obtain critical insights faster. Let’s start with why data lakehouses are becoming increasingly important.
Scope could be: Data (i.e. Information (processed data). Analytic (the analytics itself). Records (files, or what you might all unstructured data). Analytical stewardship is a missing link in analytics, BI and datascience. Images (i.e. Events or transactions.
Many CIOs argue the rise of big data pushed people to use data more proactively for business decision-making. Big data got“ more leaders and people in the organization to use data, analytics, and machine learning in their decision making,” says former CIO Isaac Sacolick. Big data can grow too big fast.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content