This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue.
At AWS, we are committed to empowering organizations with tools that streamline dataanalytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a DataLake implemented with cloud storage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced dataanalytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
With this new functionality, customers can create up-to-date replicas of their data from applications such as Salesforce, ServiceNow, and Zendesk in an Amazon SageMaker Lakehouse and Amazon Redshift. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Amazon S3 emits an object created event and matches an EventBridge rule.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. The TICKIT dataset records sales activities on the fictional TICKIT website, where users can purchase and sell tickets online for different types of events such as sports games, shows, and concerts.
OpenSearch Service seamlessly integrates with other AWS offerings, providing a robust solution for building scalable and resilient search and analytics applications in the cloud. In the event of data loss or system failure, these snapshots will be used to restore the domain to a specific point in time.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
Many security operations centers (SOCs) are finding themselves overwhelmed by telemetry data to correlate, a proliferation of tools, expanding attack surfaces that are challenging to monitor and secure, and data silos across security and IT products, security information and event management (SIEM) systems, enterprise data, and threat intelligence.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT dataanalytics.
Organizations have chosen to build datalakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A datalake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
One-time and complex queries are two common scenarios in enterprise dataanalytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. has('lineage_node', 'node_name', '{node}').fold().coalesce(unfold(),
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Dataanalytics on operational data at near-real time is becoming a common need. Then we can query the data with Amazon Athena visualize it in Amazon QuickSight.
The Salesforce Trust Intelligence Platform (TIP) log platform team is responsible for data pipeline and datalake infrastructure, providing log ingestion, normalization, persistence, search, and detection capability to ensure Salesforce is safe from threat actors. Headquartered in San Francisco, Salesforce, Inc.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
TIBCO is a large, independent cloud-computing and dataanalytics software company that offers integration, analytics, business intelligence and events processing software. It enables organizations to analyze streaming data in real time and provides the capability to automate analytics processes.
Amazon Kinesis DataAnalytics makes it easy to transform and analyze streaming data in real time. In this post, we discuss why AWS recommends moving from Kinesis DataAnalytics for SQL Applications to Amazon Kinesis DataAnalytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
And as businesses contend with increasingly large amounts of data, the cloud is fast becoming the logical place where analytics work gets done. For many enterprises, Microsoft Azure has become a central hub for analytics. Azure Data Explorer. Azure DataLakeAnalytics.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. options(**additional_options).mode("append").save(s3_output_folder)
One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform. These Snowflake accelerators reduce the time to analytics for your users at all levels so you can make data-driven decisions faster. Security DataLake. Snowflake Health Check.
We have defined all layers and components of our design in line with the AWS Well-Architected Framework DataAnalytics Lens. Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
For example, in a chatbot, dataevents could pertain to an inventory of flights and hotels or price changes that are constantly ingested to a streaming storage engine. Furthermore, dataevents are filtered, enriched, and transformed to a consumable format using a stream processor.
Even Forbes Tech Council has written about the benefits of datalakes in Fortnite. The game’s parent company, Epic Games, processes millions of events each minute, and its mountain of data grows steadily. Processing and analyzing this data — petabytes worth — must happen somewhere.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science.
It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Introducing the SFTP connector for AWS Glue The SFTP connector for AWS Glue simplifies the process of connecting AWS Glue jobs to extract data from SFTP storage and to load data into SFTP storage.
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built dataanalytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
In the dataanalytics space, organizations often deal with many tables in different databases and file formats to hold data for different business functions. Apache Hudi supports ACID transactions and CRUD operations on a datalake. It uses the native support for Apache Hudi on AWS Glue for Apache Spark.
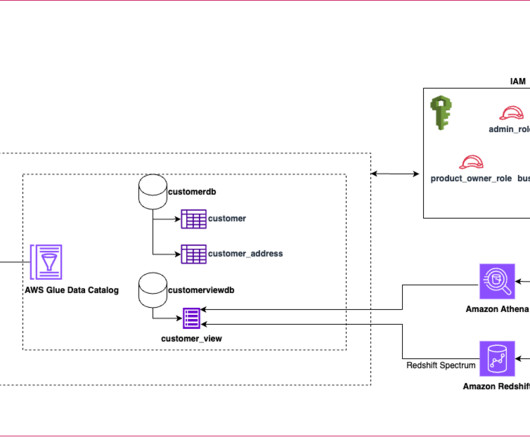
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption.
We are delighted to announce the release of the DataAnalytics Lens. Using the Lens in the Tool’s Lens Catalog, you can directly assess your Analytics workload in the console, and produce a set of actionable results for customized improvement plans recommended by the Tool. What’s new in the DataAnalytics Lens?
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
The company is also refining its dataanalytics operations, and it is deploying advanced manufacturing using IoT devices, as well as AI-enhanced robotics. One HR employee took some courses in dataanalytics and found a new job within the company helping to advance digital transformation. “I
With data growing at a staggering rate, managing and structuring it is vital to your survival. In our Event Spotlight series, we cover the biggest industry events helping builders learn about the latest tech, trends, and people innovating in the space. In this piece, we detail the Israeli debut of Periscope Data.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These upstream data sources constitute the data producer components.
With automated alerting with a third-party service like PagerDuty , an incident management platform, combined with the robust and powerful alerting plugin provided by OpenSearch Service, businesses can proactively manage and respond to critical events. Vivek Shrivastava is a Principal Data Architect, DataLake in AWS Professional Services.
Putting your data to work with generative AI – Innovation Talk Thursday, November 30 | 12:30 – 1:30 PM PST | The Venetian Join Mai-Lan Tomsen Bukovec, Vice President, Technology at AWS to learn how you can turn your datalake into a business advantage with generative AI. Reserve your seat now! Reserve your seat now!
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content