This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. Delete the bucket.
At AWS, we are committed to empowering organizations with tools that streamline dataanalytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
Perhaps one of the biggest perks is scalability, which simply means that with good datalake ingestion a small business can begin to handle bigger data numbers. The reality is businesses that are collecting data will likely be doing so on several levels. DataAnalytics Simplified. Proper Scalability.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalakeanalytics, machine learning (ML), and data monetization.
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced dataanalytics capabilities. This allows you to maintain a comprehensive view of your data while optimizing for cost-efficiency.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. The Lambda function sends the content to Amazon Bedrock with directions to summarize it.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. Governance features including fine-grained access control are built into SageMaker Unified Studio using Amazon SageMaker Catalog to help you meet enterprise security requirements across your entire data estate.
That stands for “bring your own database,” and it refers to a model in which core ERP data are replicated to a separate standalone database used exclusively for reporting. OLAP reporting based on a data warehouse model is a well-proven solution for companies with robust reporting requirements. Option 3: Azure DataLakes.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT dataanalytics.
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Model developers will test for AI bias as part of their pre-deployment testing. Continuous testing, monitoring and observability will prevent biased models from deploying or continuing to operate.
Amazon SageMaker Unified Studio (preview) provides a unified experience for using data, analytics, and AI capabilities. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment. To use Amazon Bedrock FMs, grant access to base models.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. See the pattern?
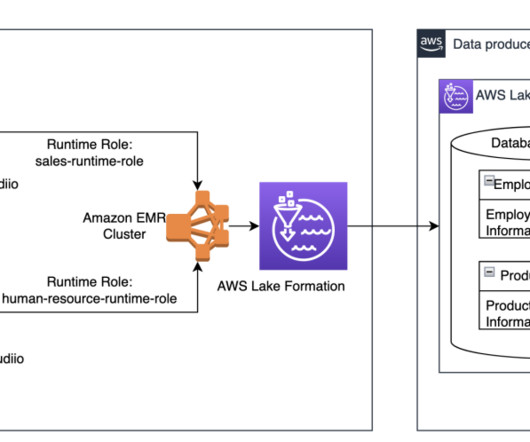
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Once completed within two years, the platform, OneTru, will give TransUnion and its customers access to TransUnion’s behemoth trove of consumer data to fuel next-generation analytical services, machine learning models and generative AI applications, says Achanta, who is driving the effort, and held similar posts at Neustar and Walmart.
Although Jira Cloud provides reporting capability, loading this data into a datalake will facilitate enrichment with other business data, as well as support the use of business intelligence (BI) tools and artificial intelligence (AI) and machine learning (ML) applications. Search for the Jira Cloud connector.
2019 can best be described as an era of modern cloud dataanalytics. Convergence in an industry like dataanalytics can take many forms. We have seen industry rollups in which firms create a collection of analytical tools under one brand. Realizing a Flexible, Multi-Cloud, Open-Platform, Data Hub-Driven Future.
A DataOps process hub offers a way for business analytics teams to cope with fast-paced requirements without expanding staff or sacrificing quality. Analytics Hub and Spoke. The dataanalytics function in large enterprises is generally distributed across departments and roles. Business Analytic Challenges.
In the book, author Zhamak Dehghani reveals that, despite the time, money, and effort poured into them, data warehouses and datalakes fail when applied at the scale and speed of today’s organizations. A distributed data mesh is a better choice. the data scientist, the engineer, and the operations engineer).
Carhartt’s signature workwear is near ubiquitous, and its continuing presence on factory floors and at skate parks alike is fueled in part thanks to an ongoing digital transformation that is advancing the 133-year-old Midwest company’s operations to make the most of advanced digital technologies, including the cloud, dataanalytics, and AI.
Applying artificial intelligence (AI) to dataanalytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big dataanalytics powered by AI.
One-time and complex queries are two common scenarios in enterprise dataanalytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. Here, datamodeling uses dbt on Amazon Redshift.
Building a datalake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based datalake, require handling data at a record level.
Apache Iceberg is an open table format for very large analytic datasets. It manages large collections of files as tables, and it supports modern analyticaldatalake operations such as record-level insert, update, delete, and time travel queries. Mikhail specializes in dataanalytics services.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
For instance, for a variety of reasons, in the short term, CDAOS are challenged with quantifying the benefits of analytics’ investments. Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service.
Taking the broadest possible interpretation of dataanalytics , Azure offers more than a dozen services — and that’s before you include Power BI, with its AI-powered analysis and new datamart option , or governance-oriented approaches such as Microsoft Purview. Azure Data Factory. Azure Data Explorer.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
To look into these processes in more detail, we will now explain the agile BI methodology as well as for analytics and provide steps for agile BI development. Agile Business Intelligence & Analytics Methodology. In the traditional model communication between developers and business users is not a priority.
Custom context enhances the AI model’s understanding of your specific datamodel, business logic, and query patterns, allowing it to generate more relevant and accurate SQL recommendations. Within this feature, user data is secure and private. Your data is not shared across accounts.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
You can’t talk about dataanalytics without talking about datamodeling. These two functions are nearly inseparable as we move further into a world of analytics that blends sources of varying volume, variety, veracity, and velocity. Building the right datamodel is an important part of your data strategy.
We’ll work with those scientists and actually build the computer models and go run it, and it can be anything from sub-physical particle imaging to protein folding,” he says. “In In other cases, it’s more of a standard computational requirement and we help them provide the data in the right formats.
Amazon Redshift integrates with AWS HealthLake and datalakes through Redshift Spectrum and Amazon S3 auto-copy features, enabling you to query data directly from files on Amazon S3. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
7 Best Platforms to Practice SQL • Explainable AI: 10 Python Libraries for Demystifying Your Model's Decisions • ChatGPT: Everything You Need to Know • DataLakes and SQL: A Match Made in Data Heaven • Google DataAnalytics Certification Review for 2023
Finding similar columns in a datalake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The workflow begins with an AWS Glue job that converts the CSV files into Apache Parquet data format.
One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform. Sirius has created a lightweight development tool to rapidly build and deploy best-practice datamodels. Security DataLake. Learn more about our Security DataLake Solution.
In this regard, the enterprise data product catalog acts as a federated portal, facilitating cross-domain access and interoperability while maintaining alignment with governance principles. This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ.
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
Tapped to guide the company’s digital journey, as she had for firms such as P&G and Adidas, Kanioura has roughly 1,000 data engineers, software engineers, and data scientists working on a “human-centered model” to transform PepsiCo into a next-generation company.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content