This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools.
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalakeanalytics, machine learning (ML), and data monetization.
Traditionally, financial data analysis could require deep SQL expertise and database knowledge. Now with Amazon Bedrock Knowledge Bases integration with structureddata, you can use simple, natural language prompts to query complex financial datasets. It reads metadata from your structureddata store to generate SQL queries.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structureddata from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Option 3: Azure DataLakes. This leads us to Microsoft’s apparent long-term strategy for D365 F&SCM reporting: Azure DataLakes. Azure DataLakes are highly complex and designed with a different fundamental purpose in mind than financial and operational reporting. Datalakes are not a mature technology.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT dataanalytics.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
Applying artificial intelligence (AI) to dataanalytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big dataanalytics powered by AI.
Amazon Redshift integrates with AWS HealthLake and datalakes through Redshift Spectrum and Amazon S3 auto-copy features, enabling you to query data directly from files on Amazon S3. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structureddata from data warehouses. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
We have defined all layers and components of our design in line with the AWS Well-Architected Framework DataAnalytics Lens. Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Solution overview Amazon Redshift is an industry-leading cloud data warehouse.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
In the dataanalytics space, organizations often deal with many tables in different databases and file formats to hold data for different business functions. Apache Hudi supports ACID transactions and CRUD operations on a datalake. It uses the native support for Apache Hudi on AWS Glue for Apache Spark.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Run the following SQL to prepare a sample dataset in Amazon Redshift.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for datalake, data warehouse, and machine learning use cases. You can build projects and subscribe to both unstructured and structureddata assets within the Amazon DataZone portal.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structureddata.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These upstream data sources constitute the data producer components.
The details of each step are as follows: Populate the Amazon Redshift Serverless data warehouse with company stock information stored in Amazon Simple Storage Service (Amazon S3). Redshift Serverless is a fully functional data warehouse holding data tables maintained in real time.
Benefits of new data warehousing technology Everything is data, regardless of whether it’s structured, semi-structured, or unstructured. Most of the enterprise or legacy data warehousing will support only structureddata through relational database management system (RDBMS) databases.
Following its acquisition of Neustar, a Google Cloud Platform customer, TransUnion embraced a multicloud infrastructure that also supports GCP, but the crown jewel of its technology modernization is OneTru, and its 50 petabytes of data assets amassed over decades.
To understand the best ways to make API calls via Apache Flink, refer to Common streaming data enrichment patterns in Amazon Kinesis DataAnalytics for Apache Flink. With a file system sink connector, Apache Flink jobs can deliver data to Amazon S3 in open format (such as JSON, Avro, Parquet, and more) files as data objects.
Introducing DataLakes. Microsoft’s next option is called Azure DataLake Services (ADLS), and it seems to be the company’s favored long-term solution to its D365 F&SCM reporting challenge. Datalake” is a generic term that refers to a fairly new development in the world of big dataanalytics.
The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse. About the Authors Ismail Makhlouf is a Senior Specialist Solutions Architect for DataAnalytics at AWS.
You can’t talk about dataanalytics without talking about data modeling. These two functions are nearly inseparable as we move further into a world of analytics that blends sources of varying volume, variety, veracity, and velocity. Big dataanalytics case study: SkullCandy.
It allows users to write data transformation code, run it, and test the output, all within the framework it provides. Use case The Enterprise DataAnalytics group of a large jewelry retailer embarked on their cloud journey with AWS in 2021. AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 datalake.
Customers use Amazon Redshift to run their business-critical analytics on petabytes of structured and semi-structureddata. Apache Spark is a popular framework that you can use to build applications for use cases such as ETL (extract, transform, and load), interactive analytics, and machine learning (ML).
Structured vs unstructured data. Structureddata is far easier for programs to understand, while unstructured data poses a greater challenge. However, both types of data play an important role in data analysis. Structureddata. Structureddata is organized in tabular format (ie.
Unless, of course, the rest of their data also resides in the Google Cloud. In this post we showcase how we used AWS Glue to move siloed digital analyticsdata, with inconsistent arrival times, to AWS S3 (our DataLake) and our central data warehouse (DWH), Snowflake.
However, there is a fundamental challenge standing in the way of being successful: data. By breaking down data silos and integrating log data from multiple sources, Cloudera empowers defenders with the real-time analytics to respond to threats swiftly.
They classified the metrics and indicators in the following categories: Data usage – A clear understanding of who is consuming what data source, materialized with a mapping of consumers and producers. Srikant Das is an Acceleration Lab Solutions Architect at Amazon Web Services.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata.
Cloud-based data warehouses can also perform complex analytical queries much faster due to the use of massively parallel processing (MPP), which uses multiple processors—each with its own operating system and memory—to simultaneously perform a set of coordinated computations.
Similarly, the relational database has been the foundation for data warehousing for as long as data warehousing has been around. Relational databases were adapted to accommodate the demands of new workloads, such as the data engineering tasks associated with structured and semi-structureddata, and for building machine learning models.
As they attempt to put machine learning models into production, data science teams encounter many of the same hurdles that plagued dataanalytics teams in years past: Finding trusted, valuable data is time-consuming. Obstacles, such as user roles, permissions, and approval request prevent speedy data access.
Today’s data landscape is characterized by exponentially increasing volumes of data, comprising a variety of structured, unstructured, and semi-structureddata types originating from an expanding number of disparate data sources located on-premises, in the cloud, and at the edge.
Amazon Redshift helps you break down the data silos and allows you to run unified, self-service, real-time, and predictive analytics on all data across your operational databases, datalake, data warehouse, and third-party datasets with built-in governance.
Apache Iceberg is an open table format for very large analytic datasets. Iceberg manages large collections of files as tables, and it supports modern analyticaldatalake operations such as record-level insert, update, delete, and time travel queries. We use a sample JSON file as input to Amazon DynamoDB.
Ahead of the Chief DataAnalytics Officers & Influencers, Insurance event we caught up with Dominic Sartorio, Senior Vice President for Products & Development, Protegrity to discuss how the industry is evolving. In data-driven organizations, data is flowing. But I’ll give an example in favour of each.
A data pipeline is a series of processes that move raw data from one or more sources to one or more destinations, often transforming and processing the data along the way. Data pipelines support data science and business intelligence projects by providing data engineers with high-quality, consistent, and easily accessible data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































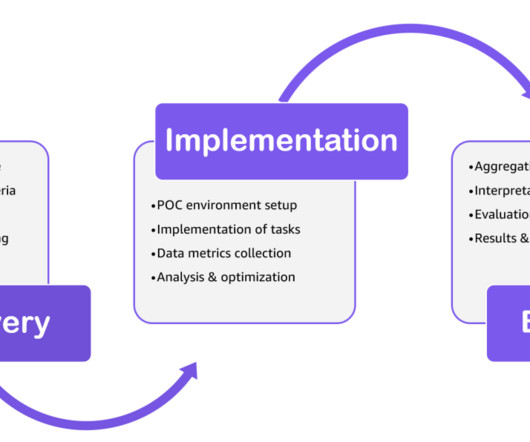




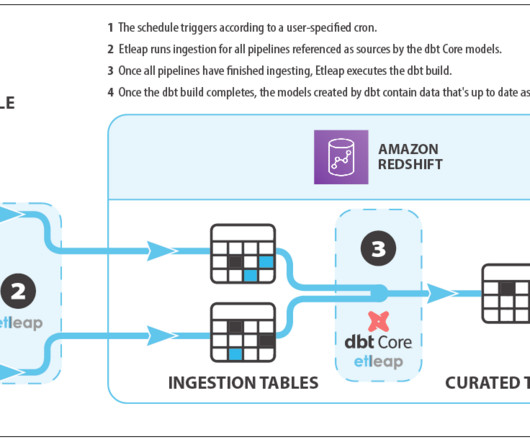











Let's personalize your content