This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools. The sample files are ‘|’ delimited text files.
At AWS, we are committed to empowering organizations with tools that streamline dataanalytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
data engineers delivered over 100 lines of code and 1.5 data quality tests every day to support a cast of analysts and customers. They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. It is necessary to have more than a datalake and a database.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, datalakeanalytics, machine learning (ML), and data monetization.
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Model developers will test for AI bias as part of their pre-deployment testing. Quality test suites will enforce “equity,” like any other performance metric.
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big dataanalytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Then, move your data.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. Apache Iceberg integration is supported by AWS analytics services including Amazon EMR , Amazon Athena , and AWS Glue. AWS Glue 3.0
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. We recommend testing your use case and data with different models.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Datalakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, datalake administrators often need to implement fine-grained access controls for different user profiles.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue.
The combination of a datalake in a serverless paradigm brings significant cost and performance benefits. By monitoring application logs, you can gain insights into job execution, troubleshoot issues promptly to ensure the overall health and reliability of data pipelines.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
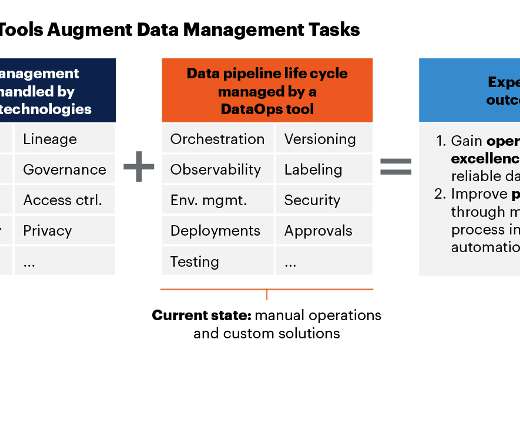
The domain also includes code that acts upon the data, including tools, pipelines, and other artifacts that drive analytics execution. The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., ….
Previously, the consulting team had been using a patchwork of ETL to consolidate data from disparate sources into a datalake. In dataanalytics, automated orchestrations can handle data operations, testing, observability, data integration and all manner of data pipelines.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. The new Recipes run, and BOOM! Conclusion.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. See the pattern?
A DataOps process hub offers a way for business analytics teams to cope with fast-paced requirements without expanding staff or sacrificing quality. Analytics Hub and Spoke. The dataanalytics function in large enterprises is generally distributed across departments and roles. DataOps Process Hub.
Therefore, we will walk you through this beginner’s guide on agile business intelligence and analytics to help you understand how they work and the methodology behind them. Your Chance: Want to test an agile business intelligence solution? What Is Agile Analytics And BI? Agile Business Intelligence & Analytics Methodology.
Marketing invests heavily in multi-level campaigns, primarily driven by dataanalytics. This analytics function is so crucial to product success that the data team often reports directly into sales and marketing. The Otezla team built a system with tens of thousands of automated tests checking data and analytics quality.
For instance, for a variety of reasons, in the short term, CDAOS are challenged with quantifying the benefits of analytics’ investments. Some of the work is very foundational, such as building an enterprise datalake and migrating it to the cloud, which enables other more direct value-added activities such as self-service.
Amazon Kinesis DataAnalytics makes it easy to transform and analyze streaming data in real time. In this post, we discuss why AWS recommends moving from Kinesis DataAnalytics for SQL Applications to Amazon Kinesis DataAnalytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Upon checking the S3 data target, we can see the S3 path is now a placeholder and the output format is Parquet. Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS.
Carhartt’s signature workwear is near ubiquitous, and its continuing presence on factory floors and at skate parks alike is fueled in part thanks to an ongoing digital transformation that is advancing the 133-year-old Midwest company’s operations to make the most of advanced digital technologies, including the cloud, dataanalytics, and AI.
Then the data is consumed by SaaS-based computational tools, but it still sits within our organization and sits within the controls of our cloud-based solutions.” Much of Regeneron’s data, of course, is confidential. For that reason, many of its data tools — and even its datalake — were built in-house using AWS. “We
The biggest challenge is broken data pipelines due to highly manual processes. Figure 1 shows a manually executed dataanalytics pipeline. First, a business analyst consolidates data from some public websites, an SFTP server and some downloaded email attachments, all into Excel.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. This zero-ETL integration reduces the complexity and operational burden of data replication to let you focus on deriving insights from your data.
The two things we are most excited about are: First, DataOps is distinct from all DataAnalytic tools. As founders, we sat in a room eight years ago (when all the rage was Hadoop, data prep, and datalakes) and debated — will there ever be an ‘ops’ layer that sits next to all the current data tools?
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. options(**additional_options).mode("append").save(s3_output_folder)
The rapid adoption of software as a service (SaaS) solutions has led to data silos across various platforms, presenting challenges in consolidating insights from diverse sources. This solution also allows you to update certain fields of the account object in the datalake and push it back to Salesforce.
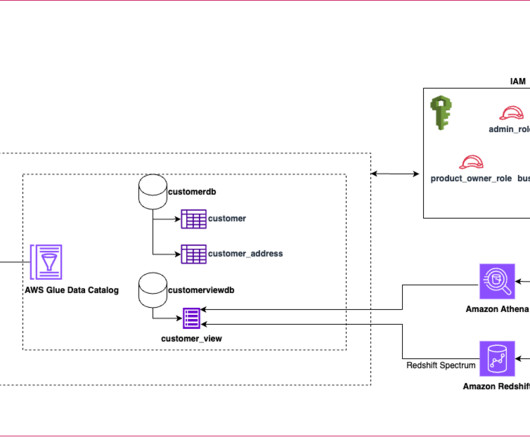
Amazon Redshift integrates with AWS HealthLake and datalakes through Redshift Spectrum and Amazon S3 auto-copy features, enabling you to query data directly from files on Amazon S3. This means you no longer have to create an external schema in Amazon Redshift to use the datalake tables cataloged in the Data Catalog.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science.
In the dataanalytics space, organizations often deal with many tables in different databases and file formats to hold data for different business functions. Apache Hudi supports ACID transactions and CRUD operations on a datalake. You don’t alter queries separately in the datalake. and save it.
Today’s enterprise dataanalytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Testing Methodology. Data Generation at Scale.
With the ever-increasing volume of data available, Dafiti faces the challenge of effectively managing and extracting valuable insights from this vast pool of information to gain a competitive edge and make data-driven decisions that align with company business objectives. We started with 115 dc2.large
Today’s datalakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption. Choose Grant.
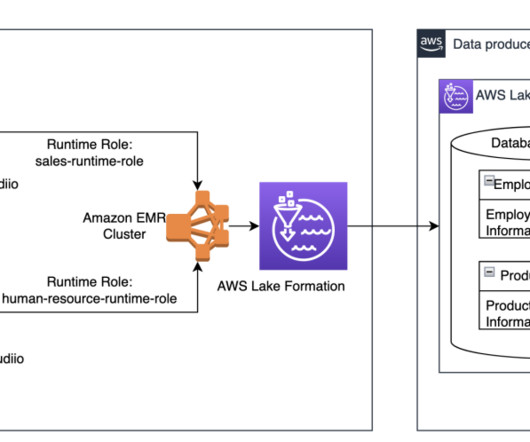
You can attach an EMR Studio Workspace to an EMR cluster, and use the compute power of the EMR cluster and run data science jobs on the cluster. Data is often stored in datalakes managed by AWS Lake Formation , enabling you to apply fine-grained access control through a simple grant or revoke mechanism.
Safety features Amazon Q generative SQL has built-in safety features to warn if a generated SQL statement will modify data and will only run based on user permissions. To test this, let’s ask Amazon Q to “delete data from web_sales table.” Amazon Q gives a message “I detected that this query changes your database.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content