

The next generation of Amazon SageMaker: The center for all your data, analytics, and AI
AWS Big Data
DECEMBER 4, 2024
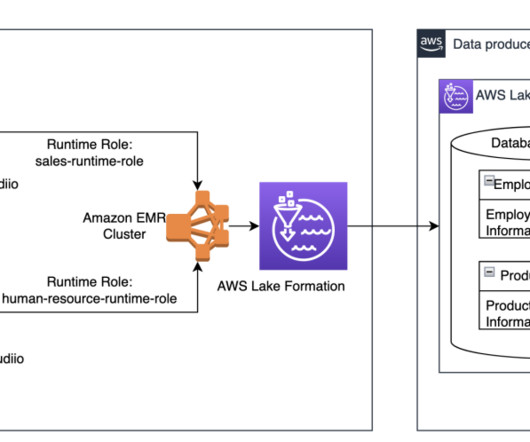
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.

















































Let's personalize your content