This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
Amazon Redshift is a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. The system had an integration with legacy backend services that were all hosted on premises.
Manish Limaye Pillar #1: Data platform The data platform pillar comprises tools, frameworks and processing and hosting technologies that enable an organization to process large volumes of data, both in batch and streaming modes. The choice of vendors should align with the broader cloud or on-premises strategy.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the dataanalytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Amaterasu — is a deployment tool for data pipelines.
You can now generate data integration jobs for various data sources and destinations, including Amazon Simple Storage Service (Amazon S3) data lakes with popular file formats like CSV, JSON, and Parquet, as well as modern table formats such as Apache Hudi , Delta , and Apache Iceberg.
Business leaders, developers, data heads, and tech enthusiasts – it’s time to make some room on your business intelligence bookshelf because once again, datapine has new books for you to add. We have already given you our top data visualization books , top business intelligence books , and best dataanalytics books.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a datawarehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau.
The AaaS model accelerates data-driven decision-making through advanced analytics, enabling organizations to swiftly adapt to changing market trends and make informed strategic choices. times better price-performance than other cloud datawarehouses. Data processing jobs enrich the data in Amazon Redshift.
Tens of thousands of customers use Amazon Redshift for modern dataanalytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. She has experience in product vision and strategy in industry-leading data products and platforms.
“BI is about providing the right data at the right time to the right people so that they can take the right decisions” – Nic Smith. Dataanalytics isn’t just for the Big Guys anymore; it’s accessible to ventures, organizations, and businesses of all shapes, sizes, and sectors.
Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your datawarehouse using the dbt seed command. This includes the host, port, database name, user name, and password. An Amazon Simple Storage (Amazon S3) bucket to host documentation files. project-dir.
Today, in order to accelerate and scale dataanalytics, companies are looking for an approach to minimize infrastructure management and predict computing needs for different types of workloads, including spikes and ad hoc analytics. Prerequisites To complete the integration, you need a Redshift Serverless datawarehouse.
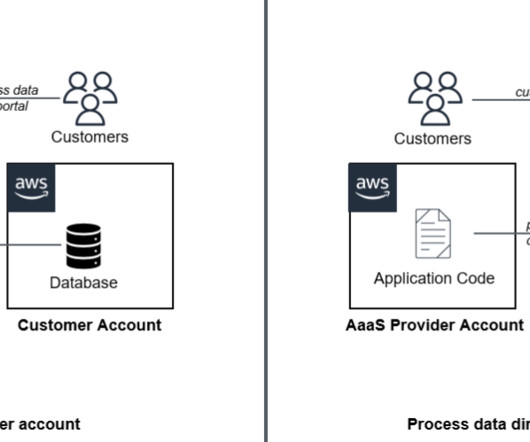
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. The producer account will host the EMR cluster and S3 buckets.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse that provides the flexibility to use provisioned or serverless compute for your analytical workloads. Modern analytics is much wider than SQL-based data warehousing. Fault tolerance is built in. Any hardware failures are automatically replaced.
The formats are basically abstraction layers that give business analysts and data scientists the ability to mix and match whatever data stores they need, wherever they may lie, with whatever processing engine they choose. The data itself remains intact, uncopied and unaltered. And the table formats will keep track of all of it.
Large-scale datawarehouse migration to the cloud is a complex and challenging endeavor that many organizations undertake to modernize their data infrastructure, enhance data management capabilities, and unlock new business opportunities. This makes sure the new data platform can meet current and future business goals.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Data Science is used in different areas of our life and can help companies to deal with the following situations: Using predictive analytics to prevent fraud Using machine learning to streamline marketing practices Using dataanalytics to create more effective actuarial processes. Where to Use Data Mining?
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3) , further empowering your dataanalytics and insights. Choose Store a new secret.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
Because Gilead is expanding into biologics and large molecule therapies, and has an ambitious goal of launching 10 innovative therapies by 2030, there is heavy emphasis on using data with AI and machine learning (ML) to accelerate the drug discovery pipeline. This data volume is expected to increase monthly and is fully refreshed each month.
A host with the installed MySQL utility, such as an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Cloud9 , your laptop, and so on. The host is used to access an Amazon Aurora MySQL-Compatible Edition cluster that you create and to run a Python script that sends sample records to the Kinesis data stream.
The data lakehouse architecture combines the flexibility, scalability and cost advantages of data lakes with the performance, functionality and usability of datawarehouses to deliver optimal price-performance for a variety of data, analytics and AI workloads.
Improved employee satisfaction: Providing business users access to data without having to contact analysts or IT can reduce friction, increase productivity, and facilitate faster results. BI analysts use dataanalytics, data visualization, and data modeling techniques and technologies to identify trends.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. Many customers ensure that their internal DNS applications are not publicly resolvable.
These nodes can implement analytical platforms like data lake houses, datawarehouses, or data marts, all united by producing data products. By treating the data as a product, the outcome is a reusable asset that outlives a project and meets the needs of the enterprise consumer.
Without real-time insight into their data, businesses remain reactive, miss strategic growth opportunities, lose their competitive edge, fail to take advantage of cost savings options, don’t ensure customer satisfaction… the list goes on. This should also include creating a plan for data storage services. Ensure data literacy.
Azure Data Lake Storage Gen2 is based on Azure Blob storage and offers a suite of big dataanalytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between data lakes and datawarehouses. Conclusion.
Each data producer within the organization has its own data lake in Apache Hudi format, ensuring data sovereignty and autonomy. These datasets are pivotal for reporting and analytics use cases, powered by services like Amazon Redshift and tools like Power BI.
Amazon Redshift is a fast, scalable cloud datawarehouse built to serve workloads at any scale. This integration positions Amazon Redshift as an IAM Identity Center-managed application, enabling you to use database role-based access control on your datawarehouse for enhanced security. Open Tableau Desktop.
On the flip side, if you enjoy diving deep into the technical side of things, with the right mix of skills for business intelligence you can work a host of incredibly interesting problems that will keep you in flow for hours on end. This could involve anything from learning SQL to buying some textbooks on datawarehouses.
Fast-track streaming ETL with AWS streaming data services: Learn how to build streaming data pipelines across data lakes and datawarehouses. Learn best practices for performance, scale, and cost control in Amazon Kinesis Data Streams, Amazon MSK, Amazon Redshift streaming ingestion, and AWS Glue streaming.
The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your data lake and the datawarehouse. About the Authors Ismail Makhlouf is a Senior Specialist Solutions Architect for DataAnalytics at AWS.
Supported AI models and services The SQL AI Assistant is not bundled with a specific LLM; instead it supports various LLMs and hosting services. The model can run locally, be hosted on CML infra or in the infrastructure of a trusted service provider. Log in to the Cloudera DataWarehouse service as DWAdmin.
The ingested data gets transformed and analyzed in near real time using Amazon Managed Service for Apache Flink. Stream data can further be enriched using lookup datahosted in a datawarehouse such as Amazon Redshift. Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in DataAnalytics.
Apache Hive is a distributed, fault-tolerant datawarehouse system that enables analytics at a massive scale. Spark SQL is an Apache Spark module for structured data processing. host') export PASSWORD=$(aws secretsmanager get-secret-value --secret-id $secret_name --query SecretString --output text | jq -r '.password')
As the queries finish running, an UNLOAD operation is invoked from the Redshift datawarehouse to the S3 bucket in Account A. Cross-account access has been set up between S3 buckets in Account A with resources in Account B to be able to load and unload data. role_arn={5}&database={6}®ion={7}'.format(conn_type,
About the Authors Raj Patel is AWS Lead Consultant for DataAnalytics solutions based out of India. He specializes in building and modernising analytical solutions. His background is in datawarehouse/data lake – architecture, development and administration.
Amazon Redshift and Tableau empower data analysis. Amazon Redshift is a cloud datawarehouse that processes complex queries at scale and with speed. Tableau’s extensive capabilities and enterprise connectivity help analysts efficiently prepare, explore, and share data insights company-wide. Open Tableau Desktop.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. We saw a record number of entries and incredible examples of how customers were using Cloudera’s platform and services to unlock the power of data. SECURITY AND GOVERNANCE LEADERSHIP.
Thousands of customers rely on Amazon Redshift to build datawarehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Data loading is one of the key aspects of maintaining a datawarehouse.
It’s no wonder then that Macmillan needs sophisticated business intelligence (BI) and dataanalytics. This data is leveraged by departments throughout the organization and is essential to their business operations. As business processes grew more complex, the data transparency and visibility suffered.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content