This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prerequisites Complete the following prerequisites before setting up the solution: Create a bucket in Amazon S3 called zero-etl-demo- - (for example, zero-etl-demo-012345678901-us-east-1 ). Create an AWS Glue database , such as zero_etl_demo_db and associate the S3 bucket zero-etl-demo- - as a location of the database.
Amazon Kinesis DataAnalytics makes it easy to transform and analyze streaming data in real time. In this post, we discuss why AWS recommends moving from Kinesis DataAnalytics for SQL Applications to Amazon Kinesis DataAnalytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities.
It’s no secret that the key to having a successful onboarding process is data. Hence, dataanalytics is the main basis for product management decisions. Let’s not wait any further and find out how dataanalytics can help us maximize the customer onboarding process to the maximum level. Wrapping it up.
However, if you would like to implement this demo in your existing Amazon Redshift data warehouse, download Redshift query editor v2 notebook, Redshift Query profiler demo , and refer to the Data Loading section later in this post. To change the distribution styles, run cell #14 of demo notebook to alter table commands.
Speaker: Javier Ramírez, Senior AWS Developer Advocate, AWS
In this session, we address common pitfalls of building data lakes and show how AWS can help you manage data and analytics more efficiently. Javier Ramirez will present: The typical steps for building a data lake. A live demo of lake formation. Navigating idle clusters and bottlenecks.
Automated DataAnalytics (ADA) on AWS is an AWS solution that enables you to derive meaningful insights from data in a matter of minutes through a simple and intuitive user interface. ADA offers an AWS-native dataanalytics platform that is ready to use out of the box by data analysts for a variety of use cases.
In June of 2020, Database Trends & Applications featured DataKitchen’s end-to-end DataOps platform for its ability to coordinate data teams, tools, and environments in the entire dataanalytics organization with features such as meta-orchestration , automated testing and monitoring , and continuous deployment : DataKitchen [link].
Data engineers A platform engineer performs a search for "temp_" or "backup_" to identify and clean up unused or legacy assets created during extract, transform, and load (ETL) workflows. This supports data hygiene and infrastructure cost optimization. The following screenshot shows an example of the data product.
This post explores how you can use BladeBridge , a leading data environment modernization solution, to simplify and accelerate the migration of SQL code from BigQuery to Amazon Redshift. Contact BladeBridge through Request demo and obtain an Analyzer key for your organization. For more details, refer to the BladeBridge Analyzer Demo.
It also helps you securely access your data in operational databases, data lakes, or third-party datasets with minimal movement or copying of data. Tens of thousands of customers use Amazon Redshift to process large amounts of data, modernize their dataanalytics workloads, and provide insights for their business users.
Many consumer internet companies invest heavily in analytics infrastructure, instrumenting their online product experience to measure and improve user retention. It turns out that type of data infrastructure is also the foundation needed for building AI products. AI doesn’t fit that model.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. This approach supports both the immediate needs of visualization tools such as Tableau and the long-term demands of digital twin and IoT dataanalytics.
You will also understand the importance of big data. Learn about the market with dataanalytics. There is no excuse for this in 2020, because dataanalytics have made it much easier to learn the basics easily. To make matters worse, they don’t use dataanalytics to guide their trading strategies.
create external schema datalake_mv_demo from data catalog database 'datalake-mv-demo' iam_role default; Create an external table named customer in the external schema datalake_mv_demo created in the preceding step. About the authors Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania.
Mito is the powerhouse of your dataanalytics workflow. We built Mito to be the first analytics tool that’s easy to use, super powerful, and designed to keep your workflow yours forever. When it comes to dataanalytics , not much is easier to use than a spreadsheet. Or something. Biology was a long time ago.
For Description , enter Parameter group for demo Aurora MySQL database. About the authors Manish Kola is a Data Lab Solutions Architect at AWS, where he works closely with customers across various industries to architect cloud-native solutions for their dataanalytics and AI needs. Choose Create.
These basic steps will enable you to deliver agile dataanalytics and BI methodology into practice, no matter the size of your company. Top 10 Tips For Agile BI & Analytics Development. Agile analytical tools can help teams in automating any process that’s done more than once. Automate as much as possible.
Dataanalytics are essential to the successful evolution of your growing business in today's modern world. You have to be able to see the forest for the trees, and it's only with dataanalytics that you can make this perspective possible. Without a proper dataanalytics strategy.
And that’s where data, analytics, and automation tools come in. SAPinsider has an idea for striking the perfect balance between agility and resiliency in supply chain management, and it involves a trio of powerhouse tools: data, analytics, and automation.
The stages involved in this big data software development methodology include: Requirement Analysis: The development team looks into the client’s requirement and takes into account the purpose, budget, time frame and other constraints to establish a complete understanding of the software.
Why is dataanalytics important for travel organizations? With dataanalytics , travel organizations can gain real-time insights about customers to make strategic decisions and improve their travel experience. How is dataanalytics used in the travel industry?
Agriculture is among those multiple industries that considerably benefit from big dataanalytics : Vegetation indices help assess crop health. Most agricultural apps are easy to understand and offer demo accounts to see how everything works. Despite all the benefits of big data, not everyone can enjoy it.
From the earliest demos of ChatGPT to the current state of play where new AI co-pilots and point solutions are launching every day, it’s been all about the tools – how can this new AI-powered widget make me faster, more efficient, and more competitive? To learn more, visit us here.
Did you know that the market for financial analytics services is worth over $25 billion ? This figure is growing every year, as more financial organizations are discovering the benefits dataanalytics technology offers. Dataanalytics has become a crucial part of the modern financial industry. Testing the bot.
With the right Big Data Tools and techniques, organizations can leverage Big Data to gain valuable insights that can inform business decisions and drive growth. What is Big Data? What is Big Data? It is an ever-expanding collection of diverse and complex data that is growing exponentially.
Big data has radically changed the accounting profession. They are also using more advanced dataanalytics tools to make more meaningful insights into the nature of their clients’ financial matters. The lease accounting profession has been particularly influenced by advances in big data.
For Role name , enter a role name (for this post, GlueJobRole-recipe-demo ). On the Job Details tab, under Basic properties, specify the IAM role that the job will use ( GlueJobRole-recipe-demo ). For S3 URL , specify s3://aws-bigdata-blog/generated_synthetic_reviews/data/product_category=Apparel/. Choose Next. Choose Save.
It is open source and you can try it out in your browser with the demo.Net introduces the DataFrame If you are familar with R or Python for data analysis, then you should be familiar with the concept of a DataFrame. Amazon Kinesis DataAnalytics now supports Apache Flink 1.8 Now.Net has a DataFrame object as well.
Request a Demo. DataRobot AI Cloud is powered by a global ecosystem of strategic, technology, solution, consulting, and integrator partners, including Amazon Web Services, AtScale, BCG, Deloitte, Factset, Google Cloud, HCL, Hexaware, Intel, Microsoft Azure, Palantir, Snowflake, and ThoughtSpot. See DataRobot AI Cloud in Action.
Tracking such user queries as part of the centralized governance of the data warehouse helps stakeholders understand potential risks and take prompt action to mitigate them following the operational excellence pillar of the AWS DataAnalytics Lens. In this post, all the Amazon Redshift data warehouses are provisioned clusters.
Dataanalytics are essential to the successful evolution of your growing business in today's modern world. You have to be able to see the forest for the trees, and it's only with dataanalytics that you can make this perspective possible. Without a proper dataanalytics strategy.
percent) cite culture – a mix of people, process, organization, and change management – as the primary barrier to forging a data-driven culture, it is worth examining data democratization efforts within your organization and the business user’s experience throughout the dataanalytics stack. Humans are explorers at heart.
And get a head start on upping your analytics knowledge by exploring the TIBCO Community Blog and Spotfire demo gallery. Product Training and Demos: Build up your skills with TIBCO and ibi products. For more on what to expect, check out the highlights from TAF 2019 on the TAF community homepage.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced dataanalytics capabilities. He works on the intersection of data lakes and data warehouses.
They are being increasingly challenged to improve efficiency and cost savings, embrace automation, and engage in data-driven decision making that helps their organization stand out from the competition. Advantages of event-driven solutions This is where event-driven solutions excel.
Create source and target endpoints in AWS DMS: The source endpoint demo-sourcedb points to the Oracle instance. The target endpoint demo-targetdb is an Amazon S3 location where the relational database will be stored in Apache Parquet format. The following screenshot shows the configurations for demo-targetdb.
Due to the benefits of automated technologies powered by artificial intelligence and dataanalytics, sales staff may now concentrate on the most vital aspects of the sales cycle. This is where dataanalytics is going to come in handy. There are a lot of data-driven tools that can make this easier.
There’s something new happening in the data sciences practically daily — and if somebody gets invited to speak at a conference, it’s most likely because they’re at the forefront of one of those developments. million positions available in dataanalytics alone. IBM predicts that by the end of 2020, in the U.S.,
If data shows that a customer is engaged, then AI can suggest the next best action to take with them. When there are multiple paths that could be taken after analyzing marketing data, analytics can suggest which product or service is the most appropriate to offer next. AI in Customer Analytics: Tapping Your Data for Success.
When the stack is complete, copy the AWS Glue scripts to the S3 bucket job-bookmark-keys-demo-. s3://job-bookmark-keys-demo- /scenario_1_job.py s3://job-bookmark-keys-demo- /scenario_2_job.py Add sample data and run AWS Glue jobs In this section, we connect to the RDS for PostgreSQL instance via AWS Lambda and create two tables.
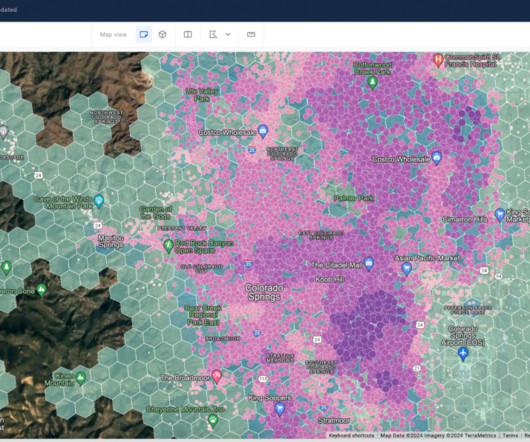
Figure 5 – Diagram illustrating the process of using H3-powered analytics for strategic decision-making Let’s talk about your use case You can experience the future of location intelligence firsthand by requesting a demo from CARTO today.
S3FileIO" } } This sets the following Spark session configurations: spark.sql.catalog.demo – Registers a Spark catalog named demo, which uses the Iceberg Spark catalog plugin. spark.sql.catalog.demo.catalog-impl – The demo Spark catalog uses AWS Glue as the physical catalog to store Iceberg database and table information.
Surfacing relevant information to end-users in a concise and digestible format is crucial for maximizing the value of data assets. Automatic document summarization, natural language processing (NLP), and dataanalytics powered by generative AI present innovative solutions to this challenge. Run sam delete from CloudShell.
The goal is to define, implement and offer a data lifecycle platform enabling and optimizing future connected and autonomous vehicle systems that would train connected vehicle AI/ML models faster with higher accuracy and delivering a lower cost. In addition, join us for industry 4.0- challenges.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content