This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenSearch Service seamlessly integrates with other AWS offerings, providing a robust solution for building scalable and resilient search and analytics applications in the cloud. This post focuses on introducing an active-passive approach using a snapshot and restore strategy.
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
One-time and complex queries are two common scenarios in enterprise dataanalytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. has('lineage_node', 'node_name', '{node}').fold().coalesce(unfold(),
As we enter into a new month, the Cloudera team is getting ready to head off to the Gartner Data & Analytics Summit in Orlando, Florida for one of the most important events of the year for Chief DataAnalytics Officers (CDAOs) and the field of data and analytics.
Amazon CloudWatch , a monitoring and observability service, collects logs and metrics from the data integration process. Amazon EventBridge , a serverless event bus service, triggers a downstream process that allows you to build event-driven architecture as soon as your new data arrives in your target.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
It aims to provide a framework to create low-latency streaming applications on the AWS Cloud using Amazon Kinesis Data Streams and AWS purpose-built dataanalytics services. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
AWS-powered data lakes, supported by the unmatched availability of Amazon Simple Storage Service (Amazon S3), can handle the scale, agility, and flexibility required to combine different data and analytics approaches. It will never remove files that are still required by a non-expired snapshot.
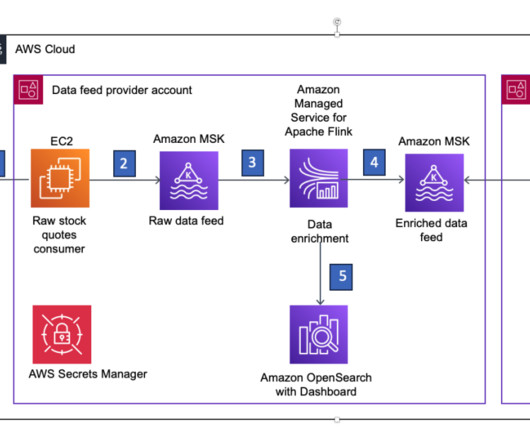
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless dataanalytics solutions on AWS using Amazon Managed Service for Apache Flink. This may require frequent truncation in certain tables to retain only the latest stream of events.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. Debezium MySQL source Kafka Connector reads these change events and emits them to the Kafka topics in Amazon MSK.
This post presents a reference architecture for real-time queries and decision-making on AWS using Amazon Kinesis DataAnalytics for Apache Flink. In addition, we explain why the Klarna Decision Tooling team selected Kinesis DataAnalytics for Apache Flink for their first real-time decision query service.
Introduction Many modern application designs are event-driven. An event-driven architecture enables minimal coupling, which makes it an optimal choice for modern, large-scale distributed systems. This service is required to do the following operations with the data: Persist the order data into its own local storage.
For example, in a chatbot, dataevents could pertain to an inventory of flights and hotels or price changes that are constantly ingested to a streaming storage engine. Furthermore, dataevents are filtered, enriched, and transformed to a consumable format using a stream processor.
A typical example of this is time series data (for example sensor readings), where each event is added as a new record to the dataset. Offers different query types , allowing to prioritize data freshness (Snapshot Query) or read performance (Read Optimized Query). The following table summarizes the features.
If they’re working on a product you have some interest in, or you’re looking to offer your talents or recruit some of theirs, you’ve got nothing to lose and everything to gain by reaching out beforehand and planning for some face time during the event. million positions available in dataanalytics alone.
You will also want to apply incremental updates with change data capture (CDC) from the source system to the destination. To make data-driven decisions in a timely manner, you need to account for missed records and backpressure, and maintain event ordering and integrity, especially if the reference data also changes rapidly.
Data migration must be performed separately using methods such as S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication. This utility has two modes for replicating Lake Formation and Data Catalog metadata: on-demand and real-time. All relevant events are then stored in a DynamoDB table.
For applications that read from a Kinesis Data Streams source, you can use the metric millisBehindLatest. If using a Kafka source, you can use records lag max for scaling events. This process may result in downtime for the application, depending on the state size, but there will be no data loss.
Apache Kafka is a high-throughput, low-latency distributed event streaming platform. Financial exchanges such as Nasdaq and NYSE are increasingly turning to Kafka to deliver their data feeds because of its exceptional capabilities in handling high-volume, high-velocity data streams.
You can see the time each task spends idling while waiting for the Redshift cluster to be created, snapshotted, and paused. The trigger runs in a parent process called a triggerer , a service that runs an asyncio event loop. She is passionate about dataanalytics and networking.
In this post, we share how Poshmark improved CX and accelerated revenue growth by using a real-time analytics solution. High-level challenge: The need for real-time analytics Previous efforts at Poshmark for improving CX through analytics were based on batch processing of analyticsdata and using it on a daily basis to improve CX.
CREATE DATABASE aurora_pg_zetl FROM INTEGRATION ' ' DATABASE zeroetl_db; The integration is now complete, and an entire snapshot of the source will reflect as is in the destination. About the Authors Raks Khare is an Analytics Specialist Solutions Architect at AWS based out of Pennsylvania.
This post is designed to be implemented for a real customer use case, where you get full snapshotdata on a daily basis. Open the function and configure a test event, with the default hello-world template event JSON as seen in the following screenshot.
Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between SaaS applications, like Salesforce, SAP, Zendesk, Slack, and ServiceNow, and AWS services like Amazon Simple Storage Service (Amazon S3) and Amazon Redshift in just a few clicks.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time dataanalytics, considering the growing velocity and volume of data being collected. The ETL job continuously consumes data from the Kafka topics, so it’s always up to date with the latest streaming data.
Solution overview Let’s consider TICKIT , a fictional website where users buy and sell tickets online for sporting events, shows, and concerts. The transactional data from this website is loaded into an Aurora MySQL 3.03.1 (or Analyze the near-real time transactional data Now we can run analytics on TICKIT’s operational data.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, data integrity is of paramount importance.
Many customers migrate their data warehousing workloads to Amazon Redshift and benefit from the rich capabilities it offers, such as the following: Amazon Redshift seamlessly integrates with broader data, analytics, and AI or machine learning (ML) services on AWS , enabling you to choose the right tool for the right job.
Auto recovery of multi-AZ deployment In the unlikely event of an Availability Zone failure, Amazon Redshift Multi-AZ deployments continue to serve your workloads by automatically using resources in the other Availability Zone. Choose the Maintenance Select a snapshot and choose Restore snapshot , Restore to provisioned cluster.
Select Augmented Analytics with Anomaly Monitoring and Alerts! Anomaly detection in dataanalytics is defined as the identification of rare items, events or observations which deviate significantly from the majority of the data and do not conform to a well-defined notion of normal behavior.
Ahead of the Chief DataAnalytics Officers & Influencers, Insurance event we caught up with Dominic Sartorio, Senior Vice President for Products & Development, Protegrity to discuss how the industry is evolving. Can you tell me a bit more about your role at Protegrity?
On the Code tab, choose Test , then Configure test event. Configure a test event with the default hello-world template event JSON. Provide an event name without any changes to the template and save the test event. Provide an event name without any changes to the template and save the test event.
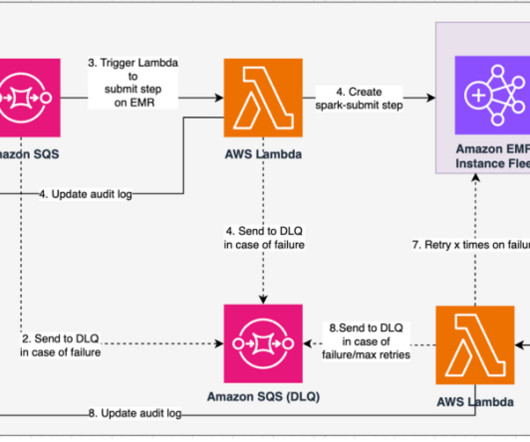
The inherent fault tolerance in PySpark and Amazon EMR promotes robustness, even in the event of node failures, making it a scalable, cost-effective, and high-performance choice for parallel data processing on AWS. In case of request failures, the Amazon SQS dead-letter queue (DLQ) retains the event.
Rather than listing facts, figures, and statistics alone, people used gripping, imaginative timelines, bestowing raw data with real context and interpretation. In turn, this gripped listeners, immersing them in the narrative, thereby offering a platform to absorb a series of events in their mind’s eye precisely the way they unfolded.
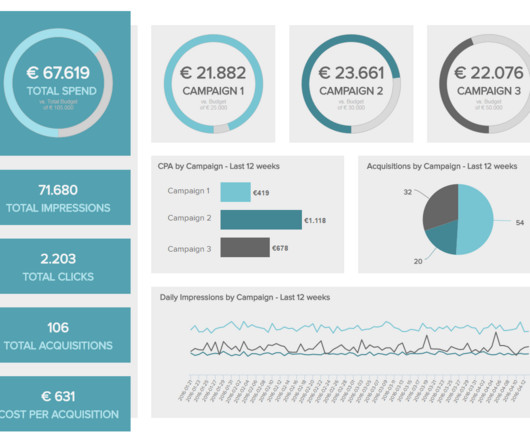
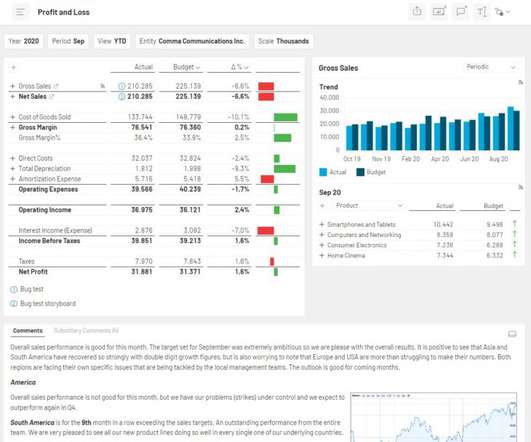
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. Step 6: Drill Into the Data. Moreover, they’re constantly updated as new information becomes available. Privacy Policy.
Every time you do an export from your ERP system, you’re taking a snapshot of the data that only reflects a single moment in time. That means having rapid access to information so that management can monitor events in real time and act quickly when the situation calls for it. We live in a rapidly changing world. Privacy Policy.
This might include a recap of the company’s strategic priorities, a summary of major events that have occurred over the past year, and a brief overview of market dynamics for your industry. The reports created within static spreadsheets are based on a snapshot of reality, taken the moment the data was exported from ERP.
All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. I agree to receive digital communications from insightsoftware containing, news, product information, promotions, or event invitations. Manual Processes Are Prone to Errors. Privacy Policy.
There is yet another problem with manual processes: the resulting reports only reflect a snapshot in time. As soon as you export data from your ERP software or other business systems, it’s obsolete. I agree to receive digital communications from insightsoftware containing, news, product information, promotions, or event invitations.
The source data in this scenario represents a snapshot of the information in your ERP system. I agree to receive digital communications from insightsoftware containing, news, product information, promotions, or event invitations. It’s not updated when someone records new transactions, and you can’t drill down to the details.
And that is only a snapshot of the benefits your finance users will enjoy with Angles for Deltek. Angles has been effective to providing us real-time financial and operational data that otherwise we would have to manually parse together. Tools to configure custom views for the remaining 20% of your team’s operational reporting needs.
For example, you can write some records using a batch ETL Spark job and other data from a Flink application at the same time and into the same table. Third, it allows scenarios such as time travel and rollback, so you can run SQL queries on a point-in-time snapshot of your data, or rollback data to a previously known good version.
To optimize their security operations, organizations are adopting modern approaches that combine real-time monitoring with scalable dataanalytics. They are using data lake architectures and Apache Iceberg to efficiently process large volumes of security data while minimizing operational overhead.
Although this provides immediate consistency and simplifies reads (because readers only access the latest snapshot of the data), it can become costly and slow for write-heavy workloads due to the need for frequent rewrites. The process involves simulating IoT data ingestion, deduplication, and querying performance using Athena.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content