This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cloudera, together with Octopai, will make it easier for organizations to better understand, access, and leverage all their data in their entire data estate – including data outside of Cloudera – to power the most robust data, analytics and AI applications.
This week on the keynote stages at AWS re:Invent 2024, you heard from Matt Garman, CEO, AWS, and Swami Sivasubramanian, VP of AI and Data, AWS, speak about the next generation of Amazon SageMaker , the center for all of your data, analytics, and AI. The relationship between analytics and AI is rapidly evolving.
To handle such scenarios you need a transalytical graph database – a database engine that can deal with both frequent updates (OLTP workload) as well as with graph analytics (OLAP). Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. Metadata about Relationships Come in Handy. Schemas are powerful.
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
In addition to real-time analytics and visualization, the data needs to be shared for long-term dataanalytics and machine learning applications. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
As 2019 comes to a close, we think it’s the perfect time to review trends in metadata management as well as look at some of Octopai’s own highlights. What a flashback to see all that we’ve achieved this year in data governance, risk and compliance, data analysis and reporting. View more news from 2019 and beyond here.
Open data is the future. And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. A few solutions manage both.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Institutional Data & AI Platform architecture The Institutional Division has implemented a self-service data platform to enable the domain teams to build and manage data products autonomously. The following diagram illustrates the building blocks of the Institutional Data & AI Platform.
Pricing and availability Amazon MWAA pricing dimensions remains unchanged, and you only pay for what you use: The environment class Metadata database storage consumed Metadata database storage pricing remains the same. Over the years, he has helped multiple customers on data platform transformations across industry verticals.
The IAM role ARN must be the same for both the OpenSearch Servicer sink definition and the Kinesis Data Streams source definition. You can control what data gets indexed in different indexes using the index definition in the sink.
Dataanalytics is the linchpin of digital business strategies in the 21st Century. Sensible companies need to know how to properly utilize dataanalytics to take full advantage of all of their digital resources. The Intersection Between DataAnalytics and Digital Asset Management.
You lose the roots, all of the rich, business, context and metadata and security and hierarchies, and then you have to try and recreate it in the new environment. But the problem with that is that it’s like ripping a tree out of the forest and trying to get it to grow in a different environment.
This is the first event Octopai and Cloudera join forces to bring to the market the only true hybrid platform for data, analytics, and AI as well as the best-in-class data lineage and metadata management platform.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. Start using this enhanced search capability today and experience the difference it brings to your data discovery journey.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
Data scientists are analyticaldata experts who use data science to discover insights from massive amounts of structured and unstructured data to help shape or meet specific business needs and goals. Data scientist job description. Semi-structured data falls between the two.
reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints. Priyanka Chaudhary is a Senior Solutions Architect and dataanalytics specialist. Other benefits in KCL 3.0
Third-generation – more or less like the previous generation but with streaming data, cloud, machine learning and other (fill-in-the-blank) fancy tools. It’s no fun working in dataanalytics/science when you are the bottleneck in your company’s business processes. See the pattern?
In today’s digital world, the ability to make data-driven decisions and develop strategies that are based on dataanalytics is critical to success in every industry. The IDH will be a game-changing platform that allows us to make data available to data scientists and data analysts across the company.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
The domain also includes code that acts upon the data, including tools, pipelines, and other artifacts that drive analytics execution. The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., ….
. – Property insurers are using troves of geographical, geological, climate, and other data to assess all kinds of hazard risks. – All types of insurance companies are leveraging dataanalytics to detect and prosecute fraud. Insurance Metadata Management. Both of these two keys deal with metadata.
This is where metadata, or the data about data, comes into play. Having a data catalog is the cornerstone of your data governance strategy, but what supports your data catalog? Your metadata management framework provides the underlying structure that makes your data accessible and manageable.
They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.
In this post, we walk you through the top analytics announcements from re:Invent 2024 and explore how these innovations can help you unlock the full potential of your data. S3 Metadata is designed to automatically capture metadata from objects as they are uploaded into a bucket, and to make that metadata queryable in a read-only table.
The results of our new research show that organizations are still trying to master data governance, including adjusting their strategies to address changing priorities and overcoming challenges related to data discovery, preparation, quality and traceability. And close to 50 percent have deployed data catalogs and business glossaries.
Most data governance tools today start with the slow, waterfall building of metadata with data stewards and then hope to use that metadata to drive code that runs in production. In reality, the ‘active metadata’ is just a written specification for a data developer to write their code.
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless dataanalytics solutions on AWS using Amazon Managed Service for Apache Flink. It shows a call center streaming data source that sends the latest call center feed in every 15 seconds.
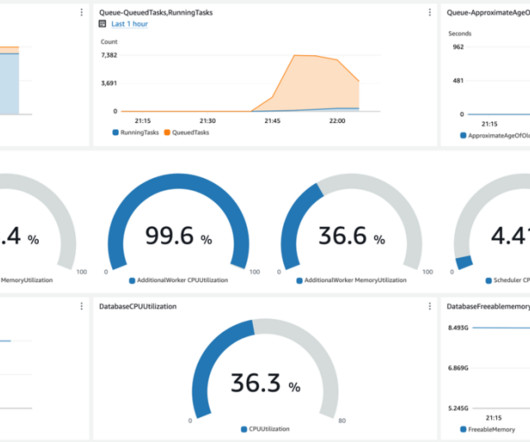
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
“The data catalog is critical because it’s where business manages its metadata,” said Venkat Rajaji, Senior Vice President of Product Management at Cloudera. There’s been a ton of innovation lately around the Iceberg REST catalog because the data turf war is over. But the metadata turf war is just getting started.”
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. Old metadata files are kept for history by default.
The following are the key components and steps in the integration process: Zero-ETL extracts and loads the data into Amazon S3 , a highly scalable object storage service. The data is also registered in the Glue Data Catalog , a metadata repository. Kamen Sharlandjiev is a Sr.
For sectors such as industrial manufacturing and energy distribution, metering, and storage, embracing artificial intelligence (AI) and generative AI (GenAI) along with real-time dataanalytics, instrumentation, automation, and other advanced technologies is the key to meeting the demands of an evolving marketplace, but it’s not without risks.
BladeBridge offers a comprehensive suite of tools that automate much of the complex conversion work, allowing organizations to quickly and reliably transition their dataanalytics capabilities to the scalable Amazon Redshift data warehouse. She is passionate about dataanalytics and data science.
The best part about data workflow management is that you can take a task and develop a custom solution to bring clarity to the entire team on what needs to be done and, most importantly, how. It’s a good idea to record metadata. The metadata describes exactly how observations were collected, formatted, and organized.
The program must introduce and support standardization of enterprise data. Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
The AWS Glue Studio visual editor is a low-code environment that allows you to compose data transformation workflows, seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine, and inspect the schema and data results in each step of the job.
The biggest challenge is broken data pipelines due to highly manual processes. Figure 1 shows a manually executed dataanalytics pipeline. First, a business analyst consolidates data from some public websites, an SFTP server and some downloaded email attachments, all into Excel. Monitoring Job Metadata.
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. This benchmark uses unmodified TPC-DS data schema and table relationships. He has been focusing in the big dataanalytics space since 2014.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content