
Introducing Amazon MWAA larger environment sizes
AWS Big Data
APRIL 16, 2024
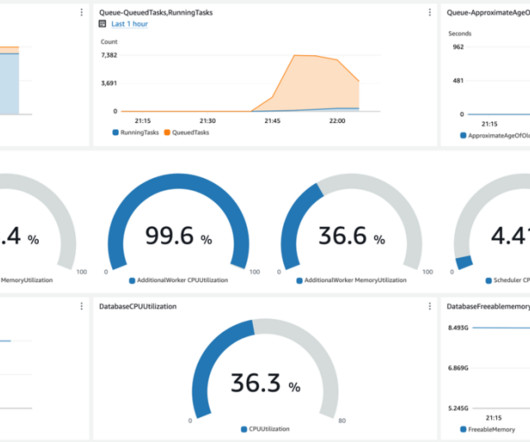
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.











































Let's personalize your content