This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient dataanalytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue. This concept makes Iceberg extremely versatile. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. It will never remove files that are still required by a non-expired snapshot.
The following are the key components and steps in the integration process: Zero-ETL extracts and loads the data into Amazon S3 , a highly scalable object storage service. The data is also registered in the Glue Data Catalog , a metadata repository. Kamen Sharlandjiev is a Sr.
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless dataanalytics solutions on AWS using Amazon Managed Service for Apache Flink. It shows a call center streaming data source that sends the latest call center feed in every 15 seconds.
Iceberg doesn’t optimize file sizes or run automatic table services (for example, compaction or clustering) when writing, so streaming ingestion will create many small data and metadata files. Offers different query types , allowing to prioritize data freshness (Snapshot Query) or read performance (Read Optimized Query).
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant data lake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
Al needs machine learning (ML), ML needs data science. Data science needs analytics. And they all need lots of data. The takeaway – businesses need control over all their data in order to achieve AI at scale and digital business transformation. Doing data at scale requires a data platform. .
Using Apache Iceberg’s compaction results in significant performance improvements, especially for large tables, making a noticeable difference in query performance between compacted and uncompacted data. These files are then reconciled with the remaining data during read time.
This is the first post to a blog series that offers common architectural patterns in building real-time data streaming infrastructures using Kinesis Data Streams for a wide range of use cases. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
You can see the time each task spends idling while waiting for the Redshift cluster to be created, snapshotted, and paused. Airflow will cache variables and connections locally so that they can be accessed faster during DAG parsing, without having to fetch them from the secrets backend, environments variables, or metadata database.
If the asset has AWS Glue Data Quality enabled, you can now quickly visualize the data quality score directly in the catalog search pane. By selecting the corresponding asset, you can understand its content through the readme, glossary terms , and technical and business metadata.
However, there is a fundamental challenge standing in the way of being successful: data. Optimized for analytics: Iceberg tables are designed to deliver analytics faster and more effectively. The metadata-driven approach ensures quick query planning so defenders don’t have to deal with slow processes when they need fast answers.
The record in the “outbox” table contains information about the event that happened inside the application, as well as some metadata that is required for further processing or routing. NOTE: Cloudera Data Platform (CDP) is a hybrid data platform designed for unmatched freedom to choose—any cloud, any analytics, any data.
Furthermore, data events are filtered, enriched, and transformed to a consumable format using a stream processor. The result is made available to the application by querying the latest snapshot. This allows the model to adapt to the latest changes in price and availability.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time dataanalytics, considering the growing velocity and volume of data being collected. For more information about checkpointing, see the appendix at the end of this post.
You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes. Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run open-source big dataanalytics frameworks without configuring, managing, and scaling clusters or servers.
We fetch the metadata of the users_xxxxxx table from Athena. The following are a few important considerations regarding how the Lambda function handles Iceberg table metadata changes: In this approach, target metadata takes precedence during DML operations. It’s imperative that the source and target metadata match.
Running HBase on Amazon S3 has several added benefits, including lower costs, data durability, and easier scalability. And during HBase migration, you can export the snapshot files to S3 and use them for recovery. HBase provided by other cloud platforms doesn’t support snapshots.
The open data lakehouse is quickly becoming the standard architecture for unified multifunction analytics on large volumes of data. It combines the flexibility and scalability of data lake storage with the dataanalytics, data governance, and data management functionality of the data warehouse.
However, there is a fundamental challenge standing in the way of being successful: data. Optimized for analytics: Iceberg tables are designed to deliver analytics faster and more effectively. The metadata-driven approach ensures quick query planning so defenders don’t have to deal with slow processes when they need fast answers.
To optimize their security operations, organizations are adopting modern approaches that combine real-time monitoring with scalable dataanalytics. They are using data lake architectures and Apache Iceberg to efficiently process large volumes of security data while minimizing operational overhead.
REST Catalog Value Proposition It provides open, metastore-agnostic APIs for Iceberg metadata operations, dramatically simplifying the Iceberg client and metastore/engine integration. It provides real time metadata access by directly integrating with the Iceberg-compatible metastore. spark.sql(SELECT * FROM airlines_data.carriers).show()
For example, you can write some records using a batch ETL Spark job and other data from a Flink application at the same time and into the same table. Third, it allows scenarios such as time travel and rollback, so you can run SQL queries on a point-in-time snapshot of your data, or rollback data to a previously known good version.
OTFs, such as Iceberg, address key limitations in traditional data lakes by offering features like ACID transactions, which maintain data consistency across concurrent operations, and compaction, which helps manage the issue of small files by merging them efficiently. The data is sent to Amazon MSK, which acts as a streaming table.
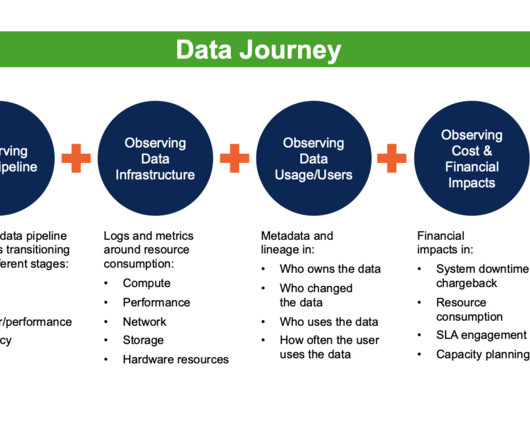
Data Observability leverages five critical technologies to create a data awareness AI engine: data profiling, active metadata analysis, machine learning, data monitoring, and data lineage. It’s primarily used to understand where data came from and its transformations.
To capture a more complete picture of the data’s journey, it is important to have a DataOps Observability system in place. Data lineage is static and often lags by weeks or months. Data lineage is often considered static because it is typically based on snapshots of data and metadata taken at a specific time.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content