This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
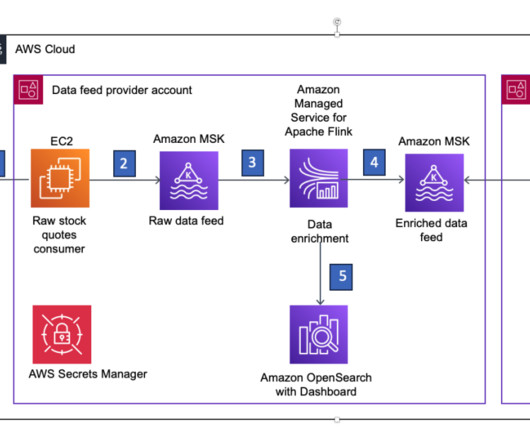
An enriched data feed can combine data from multiple sources, including financial news feeds, to add information such as stock splits, corporate mergers, volume alerts, and moving average crossovers to a basic feed. To run the application, choose Run , select Run with latest snapshot , and choose Run.
The status and statistics of the SEED load are published into CloudWatch and the data ingested by zero-ETL integration can be accessed in AWS using a set of services such Amazon Sagemaker Unified Studio , Amazon QuickSight , and others. The status and statistics of the CDC load are published into CloudWatch.
Amazon Managed Service for Apache Flink , formerly known as Amazon Kinesis DataAnalytics, is the AWS service offering fully managed Apache Flink. Each of the distributed components of an application asynchronously snapshots its state to an external persistent datastore. This is a two-phase operation.
This post presents a reference architecture for real-time queries and decision-making on AWS using Amazon Kinesis DataAnalytics for Apache Flink. In addition, we explain why the Klarna Decision Tooling team selected Kinesis DataAnalytics for Apache Flink for their first real-time decision query service.
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless dataanalytics solutions on AWS using Amazon Managed Service for Apache Flink. In this traditional architecture, a relational database is used to store data from streaming data sources.
The Outbox Pattern The general idea behind this pattern is to have an “outbox” table in the service’s data store. When the service receives a request, it not only persists the new entity, but also a record representing the message that will be published to the event bus. It is implemented in Java using the Spring framework.
In this example, we use Amazon EMR Serverless in combination with the open source library Pydeequ to act as an external system for data quality. If the asset has AWS Glue Data Quality enabled, you can now quickly visualize the data quality score directly in the catalog search pane.
The Economic Input-Output Life Cycle Assessment (EIO LCA) method is a spend-based method that combines expenditure data with monetary-based emission factors to estimate the emissions produced. The emission factors are published by the U.S. She is also very passionate about dataanalytics and machine learning.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time dataanalytics, considering the growing velocity and volume of data being collected. Upon success, update the AWS Glue Data Catalog table using the updated schema. page in the GitHub repository. $
Analyze the near-real time transactional data Now we can run analytics on TICKIT’s operational data. In order to view the integration-related metrics published to Amazon CloudWatch, navigate to Amazon Redshift console. He is passionate about helping customers architect big data solutions to process data at scale.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects.
A loading team builds a producer-consumer architecture in Amazon Redshift to process concurrent near real-time publishing of data. This requires a dedicated team of 3–7 members building and publishing refined datasets in Amazon Redshift. When the wave is complete, the people from that wave will move to another wave.
Originally published on December 9th, 2022. Amazon Redshift is a fully managed, petabyte scale cloud data warehouse that enables you to analyze large datasets using standard SQL. Choose the Maintenance Select a snapshot and choose Restore snapshot , Restore to provisioned cluster. See the required steps as below.
Change Data Capture (CDC) in the context of a data lake refers to the process of capturing and propagating changes made to source data. Source systems often lack the capability to publishdata that is modified or changed. His core area of expertise include Technology Strategy, DataAnalytics, and Data Science.
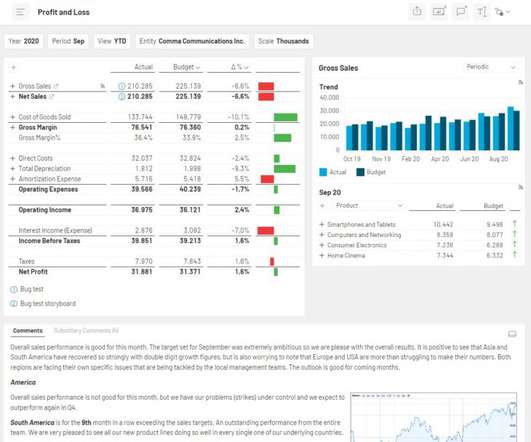
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. Step 6: Drill Into the Data. Moreover, they’re constantly updated as new information becomes available.
What’s even worse is that these kinds of errors are often overlooked until after an erroneous report has been presented to management or published to an external audience. Every time you do an export from your ERP system, you’re taking a snapshot of the data that only reflects a single moment in time.
All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. Perhaps just as importantly, they lead to a time delay between the moment something happens in the business and the time it shows up on a report. Manual Processes Are Prone to Errors.
There is yet another problem with manual processes: the resulting reports only reflect a snapshot in time. As soon as you export data from your ERP software or other business systems, it’s obsolete.
The source data in this scenario represents a snapshot of the information in your ERP system. Researching that question requires substantial additional effort if your organization uses manual planning and budgeting processes. It’s not updated when someone records new transactions, and you can’t drill down to the details.
Microsoft Excel offers flexibility, but it’s missing so many of the elements required to assemble data quickly and easily for powerful (and accurate) financial narratives. The reports created within static spreadsheets are based on a snapshot of reality, taken the moment the data was exported from ERP.
And that is only a snapshot of the benefits your finance users will enjoy with Angles for Deltek. Angles has been effective to providing us real-time financial and operational data that otherwise we would have to manually parse together. Tools to configure custom views for the remaining 20% of your team’s operational reporting needs.
For example, you can write some records using a batch ETL Spark job and other data from a Flink application at the same time and into the same table. Third, it allows scenarios such as time travel and rollback, so you can run SQL queries on a point-in-time snapshot of your data, or rollback data to a previously known good version.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content