This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post focuses on introducing an active-passive approach using a snapshot and restore strategy. Snapshot and restore in OpenSearch Service The snapshot and restore strategy in OpenSearch Service involves creating point-in-time backups, known as snapshots , of your OpenSearch domain.
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
One-time and complex queries are two common scenarios in enterprise dataanalytics. Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. file, enter the preprocessing code for the raw lineage data.
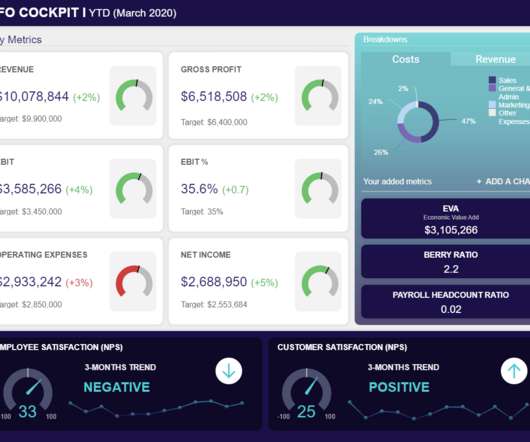
By including this cohesive mix of visual information, every CFO, regardless of sector, can gain a clear snapshot of the company’s fiscal performance within the first quarter of the year. By focusing on these key areas and working with the right tools, you will ensure that your CFO dataanalytics are a success from the outset.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
For more information, refer SQL models. Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your data warehouse using the dbt seed command. A Redshift cluster.
Data lakes are not transactional by default; however, there are multiple open-source frameworks that enhance data lakes with ACID properties, providing a best of both worlds solution between transactional and non-transactional storage mechanisms. The referencedata is continuously replicated from MySQL to DynamoDB through AWS DMS.
That’s a fair point, and it places emphasis on what is most important – what best practices should data teams employ to apply observability to dataanalytics. We see data observability as a component of DataOps. In our definition of data observability, we put the focus on the important goal of eliminating data errors.
Step 3: Verify the initial SEED load The SEED load refers to the initial loading of the tables that you want to ingest into an Amazon SageMaker Lakehouse using zero-ETL integration. He is passionate about helping customers build scalable, secure and high-performance data solutions in the cloud. Kamen Sharlandjiev is a Sr.
This is the first post to a blog series that offers common architectural patterns in building real-time data streaming infrastructures using Kinesis Data Streams for a wide range of use cases. In this post, we will review the common architectural patterns of two use cases: Time Series Data Analysis and Event Driven Microservices.
In this post, we discuss ways to modernize your legacy, on-premises, real-time analytics architecture to build serverless dataanalytics solutions on AWS using Amazon Managed Service for Apache Flink. For the template and setup information, refer to Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator.
Whenever there is an update to the Iceberg table, a new snapshot of the table is created, and the metadata pointer points to the current table metadata file. At the top of the hierarchy is the metadata file, which stores information about the table’s schema, partition information, and snapshots. This makes the overall writes slower.
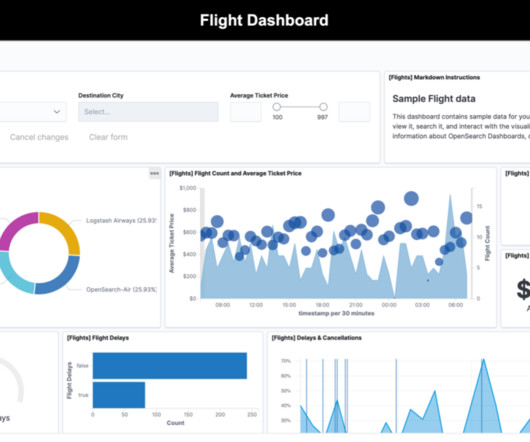
For instructions to create an OpenSearch Service domain, refer to Getting started with Amazon OpenSearch Service. Choose the Sample flight data dataset and choose Add data. Under Generate the link as , select Snapshot and choose Copy iFrame code. The domain creation takes around 15–20 minutes. Solutions Architect at AWS.
BI tools access and analyze data sets and present analytical findings in reports, summaries, dashboards, graphs, charts, and maps to provide users with detailed intelligence about the state of the business. BI aims to deliver straightforward snapshots of the current state of affairs to business managers.
The connectors were only able to reference hostnames in the connector configuration or plugin that are publicly resolvable and couldn’t resolve private hostnames defined in either a private hosted zone or use DNS servers in another customer network. For instructions, refer to create key-pair here. For instructions, refer to here.
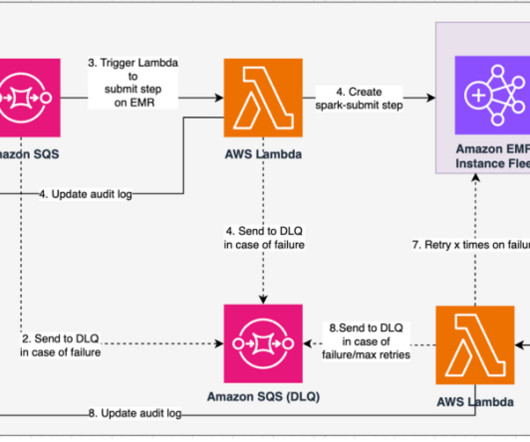
For complete getting started guides, refer to Working with Aurora zero-ETL integrations with Amazon Redshift and Working with zero-ETL integrations. Refer to Connect to an Aurora PostgreSQL DB cluster for the options to connect to the PostgreSQL cluster. The following diagram illustrates the architecture implemented in this post.
You can see the time each task spends idling while waiting for the Redshift cluster to be created, snapshotted, and paused. Refer to the Configuration reference in the User Guide for detailed configuration values. To learn more about Setup and Teardown tasks, refer to the Apache Airflow documentation.
But what is the state of AI and Big Data, right now? In this article, we take a snapshot look at the world of information processing as it stands in the present. Big data and AI have what is referred to as a synergistic relationship. Data Democratization. Data is no longer solely the asset of very large businesses.
Furthermore, data events are filtered, enriched, and transformed to a consumable format using a stream processor. The result is made available to the application by querying the latest snapshot. For more information, refer to Notions of Time: Event Time and Processing Time. For more information, refer to Dynamic Tables.
This means that if data is moved from a bucket in the source Region to another bucket in the target Region, the data access permissions need to be reapplied in the target Region. AWS Glue Data Catalog The AWS Glue Data Catalog is a central repository of metadata about data stored in your data lake.
Amazon Redshift only supports Delta Symlink tables (see Creating external tables for data managed in Delta Lake for more information). Refer to Working with other AWS services in the Lake Formation documentation for an overview of table format support when using Lake Formation with other AWS services.
This post presents a reference architecture for real-time queries and decision-making on AWS using Amazon Kinesis DataAnalytics for Apache Flink. In addition, we explain why the Klarna Decision Tooling team selected Kinesis DataAnalytics for Apache Flink for their first real-time decision query service.
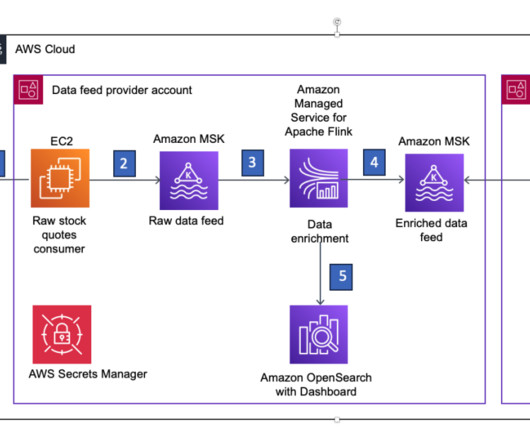
Apache Flink is an opensource distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing, event time semantics, checkpointing, snapshots and rollback. We refer to this as the producer account.
Valid values for OP field are: c = create u = update d = delete r = read (applies to only snapshots) The following diagram illustrates the solution architecture: The solution workflow consists of the following steps: Amazon Aurora MySQL has a binary log (i.e., He works with AWS customers to design and build real time data processing systems.
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time dataanalytics, considering the growing velocity and volume of data being collected. Refer appendix section for more information on this feature. Refer to the first stack’s output.
By analyzing the historical report snapshot, you can identify areas for improvement, implement changes, and measure the effectiveness of those changes. For instructions, refer to Amazon DataZone quickstart with AWS Glue data. To learn more about Amazon DataZone, refer to the Amazon DataZone User Guide.
For more details, refer to the What’s New Post. In this post, we provide step-by-step guidance on how to get started with near-real time operational analytics using this feature. For this illustration, we use a provisioned Aurora database and an Amazon Redshift Serverless data warehouse.
This post is designed to be implemented for a real customer use case, where you get full snapshotdata on a daily basis. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, DataAnalytics, and Data Science.
Many customers migrate their data warehousing workloads to Amazon Redshift and benefit from the rich capabilities it offers, such as the following: Amazon Redshift seamlessly integrates with broader data, analytics, and AI or machine learning (ML) services on AWS , enabling you to choose the right tool for the right job.
You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes. Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run open-source big dataanalytics frameworks without configuring, managing, and scaling clusters or servers.
NOTE: Cloudera Data Platform (CDP) is a hybrid data platform designed for unmatched freedom to choose—any cloud, any analytics, any data. CDP delivers faster and easier data management and dataanalytics for data anywhere, with optimal performance, scalability, security, and governance.
The AWS CLI command below demonstrates how to upload the sample data folders into the S3 target location. aws s3 cp /path/to/local/file s3://bucket-name/path/to/destination The snapshot of the S3 console shows two newly added folders that contains the files. She is also very passionate about dataanalytics and machine learning.
Top line revenue refers to the total value of sales of an organization’s services or products. In this post, we share how Poshmark improved CX and accelerated revenue growth by using a real-time analytics solution. Poshmark selected Kinesis DataAnalytics for Apache Flink to run the data enrichment application.
Depending on your enterprise’s culture and goals, your migration pattern of a legacy multi-tenant data platform to Amazon Redshift could use one of the following strategies: Leapfrog strategy – In this strategy, you move to an AWS modern data architecture and migrate one tenant at a time. The following figure shows a daily usage KPI.
For more information to create key using KMS, refer to Creating keys. Complete the following steps to create a Multi-AZ deployment restored from a snapshot: On the Amazon Redshift console, in the navigation pane, choose Clusters. Choose the Maintenance Select a snapshot and choose Restore snapshot , Restore to provisioned cluster.
At present, 53% of businesses are in the process of adopting big dataanalytics as part of their core business strategy – and it’s no coincidence. To win on today’s information-rich digital battlefield, turning insight into action is a must, and online data analysis tools are the very vessel for doing so. click to enlarge**.
Amazon EMR stands as a dynamic force in the cloud, delivering unmatched capabilities for organizations seeking robust big data solutions. Its seamless integration, powerful features, and adaptability make it an indispensable tool for navigating the complexities of dataanalytics and ML on AWS.
Most businesses store their critical data in a data lake, where you can bring data from various sources to a centralized storage. Change Data Capture (CDC) in the context of a data lake refers to the process of capturing and propagating changes made to source data.
You also have this year’s approved budget on hand for reference. The source data in this scenario represents a snapshot of the information in your ERP system. During this process, you notice that maintenance and repair expenses were especially high in June and July.
Running HBase on Amazon S3 has several added benefits, including lower costs, data durability, and easier scalability. And during HBase migration, you can export the snapshot files to S3 and use them for recovery. HBase provided by other cloud platforms doesn’t support snapshots.
This means data teams can focus on analysis and insights rather than infrastructure management. Furthermore, Iceberg tables managed through PyIceberg are compatible with AWS dataanalytics services. For example, they might need to compare historical snapshots with current data to analyze trends over time.
To optimize their security operations, organizations are adopting modern approaches that combine real-time monitoring with scalable dataanalytics. They are using data lake architectures and Apache Iceberg to efficiently process large volumes of security data while minimizing operational overhead.
Time Travel: Reproduce a query as of a given time or snapshot ID, which can be used for historical audits, validating ML models, and rollback of erroneous operations, as examples. Please reference user documentation for installation and configuration of Cloudera Public Cloud. Follow the steps below to setup Cloudera: 1.
Although this provides immediate consistency and simplifies reads (because readers only access the latest snapshot of the data), it can become costly and slow for write-heavy workloads due to the need for frequent rewrites. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content