This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While traditional extract, transform, and load (ETL) processes have long been a staple of dataintegration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS. The Redshift publish zone is a different set of tables in the same Redshift provisioned cluster. 2 GB into the landing zone daily.
We also examine how centralized, hybrid and decentralized dataarchitectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
With this launch, you can query data regardless of where it is stored with support for a wide range of use cases, including analytics, ad-hoc querying, data science, machine learning, and generative AI. We’ve simplified dataarchitectures, saving you time and costs on unnecessary data movement, data duplication, and custom solutions.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. Layering technology on the overall dataarchitecture introduces more complexity. Data and cloud strategy must align.
They give data scientists tools to instantiate development sandboxes on demand. They automate the data operations pipeline and create platforms used to test and monitor data from ingestion to published charts and graphs.
Data fabric and data mesh are emerging data management concepts that are meant to address the organizational change and complexities of understanding, governing and working with enterprise data in a hybrid multicloud ecosystem. The good news is that both dataarchitecture concepts are complimentary.
AWS Glue A dataintegration service, AWS Glue consolidates major dataintegration capabilities into a single service. These include data discovery, modern ETL, cleansing, transforming, and centralized cataloging. Its also serverless, which means theres no infrastructure to manage.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Components of a Data Mesh. Key Design Principles of a Data Mesh. Introduction.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
The data resides on Amazon S3, which reduces the storage costs significantly. Centralized catalog for publisheddata – Multiple producers release data currently governed by their respective entities. For consumer access, a centralized catalog is necessary where producers can publish their data assets.
This blog post presents an architecture solution that allows customers to extract key insights from Amazon S3 access logs at scale. We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights.
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
Satori accelerates implementing data security controls on datawarehouses like Amazon Redshift, is straightforward to integrate, and doesn’t require any changes to your Amazon Redshift data, schema, or how your users interact with data. Lisa Levy is a Content Specialist at Satori.
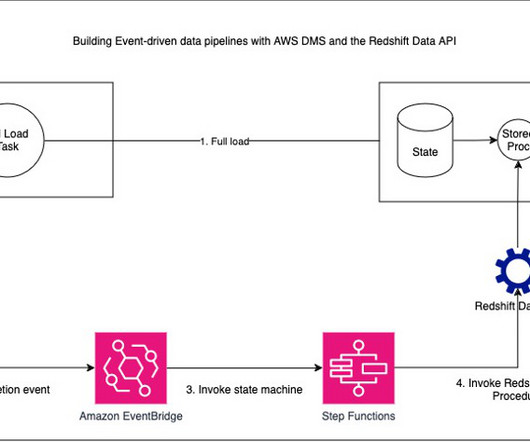
It also provides timely refreshes of data in your data warehouse. AWS DMS publishes the replicationtaskstopped event to EventBridge when the replication task is complete, which invokes an EventBridge rule. He has worked with building databases and data warehouse solutions for over 15 years.
And each of these gains requires dataintegration across business lines and divisions. Limiting growth by (dataintegration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. We call this the Bad Data Tax.
Processing terabytes or even petabytes of increasing complex omics data generated by NGS platforms has necessitated development of omics informatics. gene expression; microbiome data) and any tabular data (e.g., clinical) using a range of machine learning models.
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift data warehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 AWS Glue 5.0 Apache Iceberg 1.6.1,
For example, a node in an LPG with a given label does not guarantee anything about its properties and data type (because it is a string and represents no semantics). LPG lacks schema and semantics, which makes it inappropriate for publishing and sharing of data. This makes LPGs inflexible. LPGs are rudimentary knowledge graphs.
For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred dataintegration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
I try to relate as much published research as I can in the time available to draft a response. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend. – In the webinar and Leadership Vision deck for Data and Analytics we called out AI engineering as a big trend.
Data Environment First off, the solutions you consider should be compatible with your current dataarchitecture. We have outlined the requirements that most providers ask for: Data Sources Strategic Objective Use native connectivity optimized for the data source.
We cover batch ingestion methods, share practical examples, and discuss best practices to help you build optimized and scalable data pipelines on AWS. Overview of solution AWS Glue is a serverless dataintegration service that simplifies data preparation and integration tasks for analytics, machine learning, and application development.
This often leaves business insights and opportunities lost among a tangled complexity of meaningless, siloed data and content. Knowledge graphs help overcome these challenges by unifying data access, providing flexible dataintegration, and automating data management.
The Challenge of Capturing Human Input Modern dataarchitectures, like Microsoft Fabric, excel in collecting and processing system-generated data. Whether transactional data, operational metrics, or system logs, these platforms are optimized to deliver analytical insights from structured sources.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content