This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ?
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important dataintegrity (and a whole host of other aspects of data management) is. What is dataintegrity?
The challenge is that these architectures are convoluted, requiring diverse and multiple models, sophisticated retrieval-augmented generation stacks, advanced dataarchitectures, and niche expertise,” they said. They predicted more mature firms will seek help from AI service providers and systems integrators.
We also examine how centralized, hybrid and decentralized dataarchitectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
This post describes how HPE Aruba automated their Supply Chain management pipeline, and re-architected and deployed their data solution by adopting a modern dataarchitecture on AWS. The new solution has helped Aruba integratedata from multiple sources, along with optimizing their cost, performance, and scalability.
DataOps Engineers implement the continuous deployment of data analytics. They give data scientists tools to instantiate development sandboxes on demand. They automate the data operations pipeline and create platforms used to test and monitor data from ingestion to published charts and graphs.
Deploying higher quality data sources with the appropriate structural veracity: Automate and enforce data model design tasks to ensure dataintegrity. From regulatory compliance and business intelligence to target marketing, data modeling maintains an automated connection back to the source.
Being locked into a dataarchitecture that can’t evolve isn’t acceptable.” Aurora built a cloud testing environment on AWS to better understand the safety of its technology by seeing how it would react to scenarios too dangerous or rare to simulate in the real world.
Advanced analytics and new ways of working with data also create new requirements that surpass the traditional concepts. Many companies are therefore forced to put these concepts to the test. But what are the right measures to make the data warehouse and BI fit for the future? What role do technology and IT infrastructure play?
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time.
It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless dataintegration is a key requirement in a modern dataarchitecture to break down data silos. AWS Glue released version 4.0 runtime ( 3.5 AWS Glue released version 4.0
Vyaire developed a custom dataintegration platform, iDataHub, powered by AWS services such as AWS Glue , AWS Lambda , and Amazon API Gateway. In this post, we share how we extracted data from SAP ERP using AWS Glue and the SAP SDK. Test the connection with SAP using the wheel file. Create the PyRFC wheel file.
Our approach The migration initiative consisted of two main parts: building the new architecture and migrating data pipelines from the existing tool to the new architecture. Often, we would work on both in parallel, testing one component of the architecture while developing another at the same time.
This blog post presents an architecture solution that allows customers to extract key insights from Amazon S3 access logs at scale. We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights.
Test access to the producer cataloged Amazon S3 data using EMR Serverless in the consumer account. Test access using Athena queries in the consumer account. Test access using SageMaker Studio in the consumer account. It is recommended to use test accounts. The catalog account will host Lake Formation and AWS Glue.
As Gameskraft’s portfolio of gaming products increased, it led to an approximate five-times growth of dedicated data analytics and data science teams. Consequently, there was a fivefold rise in dataintegrations and a fivefold increase in ad hoc queries submitted to the Redshift cluster.
Over the years, data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for enterprise data and are a common choice for a large set of users who query data for a variety of analytics and machine leaning use cases. Analytics use cases on data lakes are always evolving.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
Many of the tests to check performance and volumes of data scanned have used Athena because it provides a simple to use, fully serverless, cost effective, interface without the need to setup infrastructure. This approach was deemed efficient and effectively mitigated Amazon S3 throttling problems.
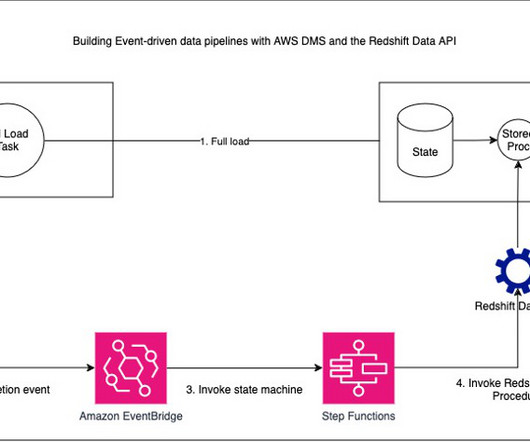
It also provides timely refreshes of data in your data warehouse. The following architecture diagram highlights the end-to-end solution using AWS services. For Name , enter a name (for example, dms-test ). Test the solution Run the task and wait for the workload to complete. Choose Create rule. Choose Create rule.
Satori accelerates implementing data security controls on datawarehouses like Amazon Redshift, is straightforward to integrate, and doesn’t require any changes to your Amazon Redshift data, schema, or how your users interact with data. Then complete the following steps to connect to Amazon Redshift: Log in to Satori.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Components of a Data Mesh. How CDF enables successful Data Mesh Architectures.
Amazon Redshift Serverless, generally available since 2021, allows you to run and scale analytics without having to provision and manage the data warehouse. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms.
To earn the Salesforce Data Architect certification , candidates should be able to design and implement data solutions within the Salesforce ecosystem, such as data modelling, dataintegration and data governance. Prerequisites include earning Salesforce Application Architect certification (see above).
Amazon SageMaker Lakehouse provides an open dataarchitecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift data warehouses, and third-party and federated data sources. connection testing, metadata retrieval, and data preview.
Integrating third-party SaaS applications is often complicated and requires significant effort and development. Developers need to understand the application APIs, write implementation and test code, and maintain the code for future API changes. Amazon AppFlow , which is a low-code/no-code AWS service, addresses this challenge.
The gold standard in data modeling solutions for more than 30 years continues to evolve with its latest release, highlighted by: PostgreSQL 16.x Migration and modernization : It enables seamless transitions between legacy systems and modern platforms, ensuring your dataarchitecture evolves without disruption.
Perhaps the biggest challenge of all is that AI solutions—with their complex, opaque models, and their appetite for large, diverse, high-quality datasets—tend to complicate the oversight, management, and assurance processes integral to data management and governance. Formalize ethics and bias testing.
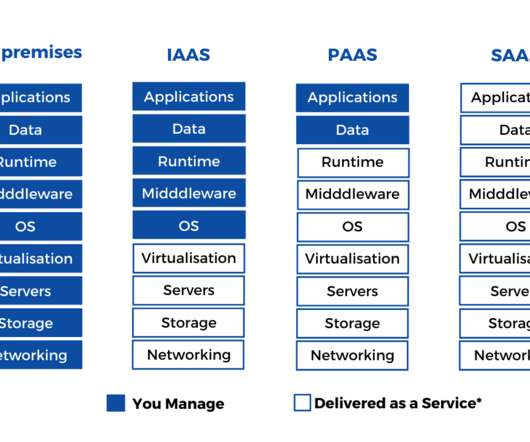
IaaS provides a platform for compute, data storage and networking capabilities. IaaS is mainly used for developing softwares (testing and development, batch processing), hosting web applications and data analysis. To try and test the platforms in accordance with data strategy and governance.
A data fabric orchestrates various data sources across a hybrid and multicloud landscape to provide business-ready data in support of analytics, AI and other applications. How IBM built its own data fabric . When I rejoined IBM in 2016, enterprise-level data and its use was having a pivotal moment.
Business analytics: Data and insights help knowledge workers make informed decisions and find new opportunities. While Big Data and artificial intelligence (AI) provide the numbers, knowledge workers are key to understanding them. The aim is to break down silos between departments with better data management and integration.
Gartner is explicit: Data catalogs play a foundational role in the data fabric. And leaders are recognizing the value of a strong data foundation. Indeed, the foundation of your dataarchitecture and strategy – and thus your business strategy – begins with choosing the best data catalog to support your business.
Through meticulous testing and research, we’ve curated a list of the ten best BI tools, ensuring accessibility and efficacy for businesses of all sizes. In essence, the core capabilities of the best BI tools revolve around four essential functions: dataintegration, data transformation, data visualization, and reporting.
The Project Kernel framework utilizes templates and AI augmentation to streamline coding processes, with the AI augmentation generating test cases using training models built on the organization’s data, use cases, and past test cases. This enabled the team to expose the technology to a small group of senior leaders to test.
Data Environment First off, the solutions you consider should be compatible with your current dataarchitecture. We have outlined the requirements that most providers ask for: Data Sources Strategic Objective Use native connectivity optimized for the data source. Build your first set of reports.
More companies have realized there is an opportunity to integrate, enhance, and present this SaaS data to improve internal operations and gain valuable insights on their data. From there, they can perform meaningful analytics, gain valuable insights, and optionally push enriched data back to external SaaS platforms.
In the digital world, dataintegrity faces similar threats, from unauthorized access to manipulation and corruption, requiring strict governance and validation mechanisms to ensure reliability and trust. Moreover, the very nature of supply and demand forced manufacturers to rethink how they produced and delivered goods.
We cover batch ingestion methods, share practical examples, and discuss best practices to help you build optimized and scalable data pipelines on AWS. Overview of solution AWS Glue is a serverless dataintegration service that simplifies data preparation and integration tasks for analytics, machine learning, and application development.
This seamless integration particularly benefits existing AWS customers who already use the Data Catalog and Lake Formation, because they can immediately take advantage of SageMaker Lakehouse capabilities. AWS Glue is a serverless service that makes dataintegration simpler, faster, and cheaper. We launched AWS Glue 5.0
DataOps Observability includes monitoring and testing the data pipeline, data quality, datatesting, and alerting. Datatesting is an essential aspect of DataOps Observability; it helps to ensure that data is accurate, complete, and consistent with its specifications, documentation, and end-user requirements.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content