This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At AWS, we are committed to empowering organizations with tools that streamline data analytics and transformation processes. This integration enables data teams to efficiently transform and manage data using Athena with dbt Cloud’s robust features, enhancing the overall data workflow experience.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. DataOps helps the data mesh deliver greater business agility by enabling decentralized domains to work in concert. . But first, let’s define the data mesh design pattern.
DataOps adoption continues to expand as a perfect storm of social, economic, and technological factors drive enterprises to invest in process-driven innovation. Many in the data industry recognize the serious impact of AI bias and seek to take active steps to mitigate it. Data Gets Meshier. Companies Commit to Remote.
Amazon Redshift has established itself as a highly scalable, fully managed cloud data warehouse trusted by tens of thousands of customers for its superior price-performance and advanced data analytics capabilities. Since consumers access the shared data in-place, they always access the latest state of the shared data.
In an effort to be data-driven, many organizations are looking to democratize data. However, they often struggle with increasingly larger data volumes, reverting back to bottlenecking data access to manage large numbers of data engineering requests and rising data warehousing costs.
Data is the foundation of innovation, agility and competitive advantage in todays digital economy. As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Data quality is no longer a back-office concern.
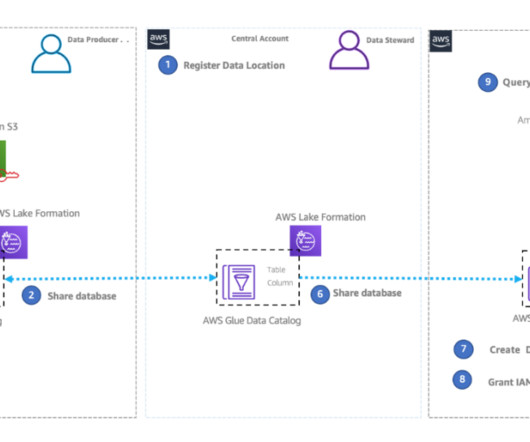
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. Customers are using AWS and Snowflake to develop purpose-built dataarchitectures that provide the performance required for modern analytics and artificial intelligence (AI) use cases.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Together, these capabilities enable terminal operators to enhance efficiency and competitiveness in an industry that is increasingly datadriven.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
In the ever-evolving world of finance and lending, the need for real-time, reliable, and centralized data has become paramount. Bluestone , a leading financial institution, embarked on a transformative journey to modernize its data infrastructure and transition to a data-driven organization.
At a time when AI is exploding in popularity and finding its way into nearly every facet of business operations, data has arguably never been more valuable. As organizations continue to navigate this AI-driven world, we set out to understand the strategies and emerging dataarchitectures that are defining the future.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. In this post, we discuss a common use case in relation to operational data processing and the solution we built using Apache Hudi and AWS Glue.
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Data is the fuel that drives government, enables transparency, and powers citizen services. That should be easy, but when agencies don’t share data or applications, they don’t have a unified view of people. Legacy data sharing involves proliferating copies of data, creating data management, and security challenges.
Truly data-driven companies see significantly better business outcomes than those that aren’t. But to get maximum value out of data and analytics, companies need to have a data-driven culture permeating the entire organization, one in which every business unit gets full access to the data it needs in the way it needs it.
Data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This leads to having data across many instances of data warehouses and datalakes using a modern dataarchitecture in separate AWS accounts.
The landscape of big data management has been transformed by the rising popularity of open table formats such as Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake. These formats, designed to address the limitations of traditional data storage systems, have become essential in modern dataarchitectures.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Data tables from IT and other data sources require a large amount of repetitive, manual work to be used in analytics. The data analytics function in large enterprises is generally distributed across departments and roles. Figure 1: Data analytics challenge – distributed teams must deliver value in collaboration.
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. We think of this concept as inside-out data movement. Example Corp.
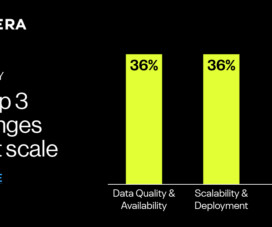
Poor data quality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from data quality issues.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes. Iterations of the lakehouse.
Data democratization, much like the term digital transformation five years ago, has become a popular buzzword throughout organizations, from IT departments to the C-suite. It’s often described as a way to simply increase data access, but the transition is about far more than that. What is data democratization?
While many organizations understand the business need for a data and analytics cloud platform , few can quickly modernize their legacy data warehouse due to a lack of skills, resources, and data literacy. One modern data platform solution that provides simplicity and flexibility to grow is Snowflake’s data cloud and platform.
When companies embark on a journey of becoming data-driven, usually, this goes hand in and with using new technologies and concepts such as AI and datalakes or Hadoop and IoT. Suddenly, the data warehouse team and their software are not the only ones anymore that turn data […].
By George Trujillo, Principal Data Strategist, DataStax I recently had a conversation with a senior executive who had just landed at a new organization. He had been trying to gather new data insights but was frustrated at how long it was taking. Real-time AI involves processing data for making decisions within a given time frame.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes. Iterations of the lakehouse.
We are excited to announce the general availability of Apache Iceberg in Cloudera Data Platform (CDP). These tools empower analysts and data scientists to easily collaborate on the same data, with their choice of tools and analytic engines. Why integrate Apache Iceberg with Cloudera Data Platform?
This is a guest post co-written by Alex Naumov, Principal Data Architect at smava. smava believes in and takes advantage of data-driven decisions in order to become the market leader. smava believes in and takes advantage of data-driven decisions in order to become the market leader.
In the final part of this three-part series, we’ll explore ho w data mesh bolsters performance and helps organizations and data teams work more effectively. Usually, organizations will combine different domain topologies, depending on the trade-offs, and choose to focus on specific aspects of data mesh.
Data governance is the collection of policies, processes, and systems that organizations use to ensure the quality and appropriate handling of their data throughout its lifecycle for the purpose of generating business value.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
Data warehousing is getting on in years. Concepts and architectures have been applied more or less unchanged since the 1990s. However, data warehousing and BI applications are only considered moderately successful. But what are the right measures to make the data warehouse and BI fit for the future?
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
The company also provides a variety of solutions for enterprises, including data centers, cloud, security, global, artificial intelligence (AI), IoT, and digital marketing services. Supporting Data Access to Achieve Data-Driven Innovation Due to the spread of COVID-19, demand for digital services has increased at SoftBank.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business.
Amazon Redshift is a fully managed cloud data warehouse that’s used by tens of thousands of customers for price-performance, scale, and advanced data analytics. We’ll then explore how Amazon Redshift data sharing powered the data mesh architecture that allowed Getir to achieve this transformative vision.
For those in the data world, this post provides a curated guide for all analytics sessions that you can use to quickly schedule and build your itinerary. A shapeshifting guardian and protector of data like Data Lynx? Or a digitally clairvoyant master of data insights like Cloud Sight?
During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. In fact, each of the 29 finalists represented organizations running cutting-edge use cases that showcase a winning enterprise data cloud strategy. Data Champions .
In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers. ATPCO’s reach is impressive, with its fare data covering over 89% of global flight schedules.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content