This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern dataarchitecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Open AWS Glue Studio. Choose ETL Jobs.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Data Gets Meshier. 2022 will bring further momentum behind modular enterprise architectures like data mesh. The data mesh addresses the problems characteristic of large, complex, monolithic dataarchitectures by dividing the system into discrete domains managed by smaller, cross-functional teams.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Previously, there were three types of data structures in telco: .
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
A big part of preparing data to be shared is an exercise in data normalization, says Juan Orlandini, chief architect and distinguished engineer at Insight Enterprises. Data formats and dataarchitectures are often inconsistent, and data might even be incomplete. They have data swamps,” he says.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business.
Each data producer within the organization has its own datalake in Apache Hudi format, ensuring data sovereignty and autonomy. This enables data-driven decision-making across the organization.
To bring their customers the best deals and user experience, smava follows the modern dataarchitecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
The technological linchpin of its digital transformation has been its Enterprise DataArchitecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
HEMA has a bespoke enterprise architecture, built around the concept of services. Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. The following figure illustrates the data mesh architecture.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables. Sudipta Bagchi is a Sr.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Building datalakes from continuously changing transactional data of databases and keeping datalakes up to date is a complex task and can be an operational challenge. You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes.
Cost and resource efficiency – This is an area where Acast observed a reduction in data duplication, and therefore cost reduction (in some accounts, removing the copy of data 100%), by reading data across accounts while enabling scaling.
These inputs reinforced the need of a unified data strategy across the FinOps teams. We decided to build a scalable data management product that is based on the best practices of modern dataarchitecture. Our source system and domain teams were mapped as data producers, and they would have ownership of the datasets.
“Always the gatekeepers of much of the data necessary for ESG reporting, CIOs are finding that companies are even more dependent on them,” says Nancy Mentesana, ESG executive director at Labrador US, a global communications firm focused on corporate disclosure documents.
The AWS modern dataarchitecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse.
This approach has several benefits, such as streamlined migration of data from on-premises to the cloud, reduced query tuning requirements and continuity in SRE tooling, automations, and personnel. This enabled data-driven analytics at scale across the organization 4.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a datalake, transformed, and made available for analytics, machine learning (ML), and visualization. The job runs in the target account.
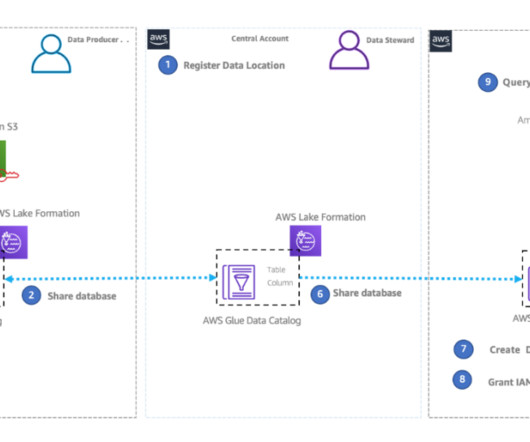
This will include how to configure Okta, AWS Lake Formation , and a business intelligence tool to enable SAML-based federated use of Athena for an enterprise BI activity. When building a scalable dataarchitecture on AWS, giving autonomy and ownership to the data domains are crucial for the success of the platform.
But Barnett, who started work on a strategy in 2023, wanted to continue using Baptist Memorial’s on-premise data center for financial, security, and continuity reasons, so he and his team explored options that allowed for keeping that data center as part of the mix.
Many organizations build and operate enterprise-wide data mesh architectures using the AWS Glue Data Catalog and AWS Lake Formation for their Amazon Simple Storage Service (Amazon S3) based datalakes. AWS Glue is a serverless service that makes data integration simpler, faster, and cheaper.
In modern dataarchitectures, the need to manage and query vast datasets efficiently, consistently, and accurately is paramount. For organizations that deal with big data processing, managing metadata becomes a critical concern. Suvojit Dasgupta is a Principal Data Architect at AWS.
Use existing AWS Glue tables This section has following prerequisites: A datalake administrator user by following Create a datalake administrator. For detailed instruction see Revoking permission using the Lake Formation console. Under Add a data source , choose Add connection , then choose Amazon Redshift.
This is the final part of a three-part series where we show how to build a datalake on AWS using a modern dataarchitecture. This post shows how to process data with Amazon Redshift Spectrum and create the gold (consumption) layer. The following diagram illustrates the different layers of the datalake.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content