This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. This enables you to extract insights from your data without the complexity of managing infrastructure.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) datalakes and Amazon Redshift data warehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Some customers build custom in-house data parity frameworks to validate data during migration.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
AWS Glue DataQuality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug dataquality issues. An AWS Glue crawler crawls the results.
While traditional extract, transform, and load (ETL) processes have long been a staple of data integration due to its flexibility, for common use cases such as replication and ingestion, they often prove time-consuming, complex, and less adaptable to the fast-changing demands of modern dataarchitectures.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
But, even with the backdrop of an AI-dominated future, many organizations still find themselves struggling with everything from managing data volumes and complexity to security concerns to rapidly proliferating data silos and governance challenges. The benefits are clear, and there’s plenty of potential that comes with AI adoption.
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Previously, there were three types of data structures in telco: .
Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Dataquality issues deter trust and hinder accurate analytics. Modern dataarchitectures. Deploying modern dataarchitectures. Forrester ). Forrester ).
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce dataquality.
In modern dataarchitectures, Apache Iceberg has emerged as a popular table format for datalakes, offering key features including ACID transactions and concurrent write support.
A big part of preparing data to be shared is an exercise in data normalization, says Juan Orlandini, chief architect and distinguished engineer at Insight Enterprises. Data formats and dataarchitectures are often inconsistent, and data might even be incomplete. They have data swamps,” he says.
The following are the key components of the Bluestone Data Platform: Data mesh architecture – Bluestone adopted a data mesh architecture, a paradigm that distributes data ownership across different business units. This enables data-driven decision-making across the organization.
Today, the way businesses use data is much more fluid; data literate employees use data across hundreds of apps, analyze data for better decision-making, and access data from numerous locations. Then, it applies these insights to automate and orchestrate the data lifecycle.
Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables better decision-making by improving dataquality, reducing data management costs, and ensuring secure access to data for stakeholders.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments.
Migrating to Amazon Redshift offers organizations the potential for improved price-performance, enhanced data processing, faster query response times, and better integration with technologies such as machine learning (ML) and artificial intelligence (AI).
Too often the design of new dataarchitectures is based on old principles: they are still very data-store-centric. They consist of many physical data stores in which data is stored repeatedly and redundantly. Over time, new types of data stores,
Solution To address the challenge, ATPCO sought inspiration from a modern data mesh architecture. Part 1: Set up account governance and identity management Before you start, compare your current cloud environment, including dataarchitecture, to ATPCO’s environment. Enter a name, such as Sales – Datalake blueprint.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake. What is a data fabric?
After countless open-source innovations ushered in the Big Data era, including the first commercial distribution of HDFS (Apache Hadoop Distributed File System), commonly referred to as Hadoop, the two companies joined forces, giving birth to an entire ecosystem of technology and tech companies.
Full-stack observability is a critical requirement for effective modern data platforms to deliver the agile, flexible, and cost-effective environment organizations are looking for. RI is a global leader in the design and deployment of large-scale, production-level modern data platforms for the world’s largest enterprises.
Data fabric and data mesh are emerging data management concepts that are meant to address the organizational change and complexities of understanding, governing and working with enterprise data in a hybrid multicloud ecosystem. The good news is that both dataarchitecture concepts are complimentary.
As part of their cloud modernization initiative, they sought to migrate and modernize their legacy data platform. This process has been scheduled to run daily, ensuring a consistent batch of fresh data for analysis. AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 datalake.
Birgit Fridrich, who joined Allianz as sustainability manager responsible for ESG reporting in late 2022, spends many hours validating data in the company’s Microsoft Sustainability Manager tool. Dataquality is key, but if we’re doing it manually there’s the potential for mistakes.
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
Data has become an invaluable asset for businesses, offering critical insights to drive strategic decision-making and operational optimization. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
This is especially beneficial when teams need to increase data product velocity with trust and dataquality, reduce communication costs, and help data solutions align with business objectives. In most enterprises, data is needed and produced by many business units but owned and trusted by no one.
In fact, AMA collects a huge amount of structured and unstructured data from bins, collection vehicles, facilities, and user reports, and until now, this data has remained disconnected, managed by disparate systems and interfaces, through Excel spreadsheets.
Real-Time Intelligence, on the other hand, takes that further by supporting data in AWS, Google Cloud Platform, Kafka installations, and on-prem installations. “We We introduced the Real-Time Hub,” says Arun Ulagaratchagan, CVP, Azure Data at Microsoft. You can monitor and act on the data and you can set thresholds.”
Big Data technology in today’s world. Did you know that the big data and business analytics market is valued at $198.08 Or that the US economy loses up to $3 trillion per year due to poor dataquality? quintillion bytes of data which means an average person generates over 1.5 megabytes of data every second?
Bad data tax is rampant in most organizations. Currently, every organization is blindly chasing the GenAI race, often forgetting that dataquality and semantics is one of the fundamentals to achieving AI success. Sadly, dataquality is losing to data quantity, resulting in “ Infobesity ”. “Any
Gartner defines “dark data” as the data organizations collect, process, and store during regular business activities, but doesn’t use any further. Gartner also estimates 80% of all data is “dark”, while 93% of unstructured data is “dark.”.
At Databricks, we’re focused on enabling customers to adopt the data lakehouse, and that’s an open dataarchitecture that combines the best of the data warehouse and the datalake into one platform,” Ferguson says. “[The And data governance is critical to driving adoption.”.
Control of Data to ensure it is Fit-for-Purpose. This refers to a wide range of activities from Data Governance to Data Management to DataQuality improvement and indeed related concepts such as Master Data Management. DataArchitecture / Infrastructure. Best practice has evolved in this area.
A data fabric utilizes an integrated data layer over existing, discoverable, and inferenced metadata assets to support the design, deployment, and utilization of data across enterprises, including hybrid and multi-cloud platforms. Data fabric does not replace data warehouses, datalakes, or data lakehouses.
Data mesh solves this by promoting data autonomy, allowing users to make decisions about domains without a centralized gatekeeper. It also improves development velocity with better data governance and access with improved dataquality aligned with business needs.
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data. In that sense, data modernization is synonymous with cloud migration. Only then can you extract insights across fragmented dataarchitecture.
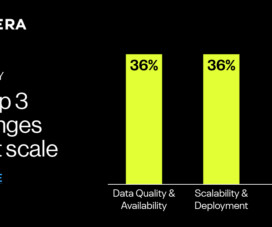
Enterprises need a “NEW DEAL” between data producers and data consumers that effectively addresses the top three challenges to improving data handling – time spent, a lack of transparency of data value and insufficient dataquality. In addition, their architecture must be made fit for digitalization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content