This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. Introducing the next generation of SageMaker The rise of generative AI is changing how data and AI teams work together.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
Dataarchitectures to support reporting, business intelligence, and analytics have evolved dramatically over the past 10 years. Download this TDWI Checklist report to understand: How your organization can make this transition to a modernized dataarchitecture. The decision making around this transition.
Cloudinary struggled to use this data for additional teams who had more online, real time, lower-granularity, dynamic usage requirements. Making petabytes of data accessible for ad-hoc reports became a challenge as query time increased and costs skyrocketed along with growing compute resource requirements. 5 seconds $0.08
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
The Gartner Magic Quadrant evaluates 20 data integration tool vendors based on two axesAbility to Execute and Completeness of Vision. Discover, prepare, and integrate all your data at any scale AWS Glue is a fully managed, serverless data integration service that simplifies data preparation and transformation across diverse data sources.
But, even with the backdrop of an AI-dominated future, many organizations still find themselves struggling with everything from managing data volumes and complexity to security concerns to rapidly proliferating data silos and governance challenges.
With data becoming the driving force behind many industries today, having a modern dataarchitecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
We also examine how centralized, hybrid and decentralized dataarchitectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
Need for a data mesh architecture Because entities in the EUROGATE group generate vast amounts of data from various sourcesacross departments, locations, and technologiesthe traditional centralized dataarchitecture struggles to keep up with the demands for real-time insights, agility, and scalability.
Tens of thousands of customers use Amazon Redshift every day to run analytics, processing exabytes of data for business insights. times better price performance than other cloud data warehouses. After assessment of the source SQL files, it generates a comprehensive report that provides valuable insights into the migration effort.
Corporate ESG reporting is getting real for companies around the globe. Enacted and proposed regulations in the EU, US, and beyond are deepening reporting requirements in an effort to change business behavior. The foundation for ESG reporting, of course, is data. The foundation for ESG reporting, of course, is data.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
This solution only replicates metadata in the Data Catalog, not the actual underlying data. To have a redundant datalake using Lake Formation and AWS Glue in an additional Region, we recommend replicating the Amazon S3-based storage using S3 replication , S3 sync, aws-s3-copy-sync-using-batch or S3 Batch replication process.
In particular, companies that were leaders at using data and analytics had three times higher improvement in revenues, were nearly three times more likely to report shorter times to market for new products and services, and were over twice as likely to report improvement in customer satisfaction, profits, and operational efficiency.
For example, teams working under the VP/Directors of Data Analytics may be tasked with accessing data, building databases, integrating data, and producing reports. Data scientists derive insights from data while business analysts work closely with and tend to the data needs of business units.
However, they do contain effective data management, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Warehouse, datalake convergence. Meet the data lakehouse.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
They often report to data infrastructure and data science leads. Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects.
Several factors determine the quality of your enterprise data like accuracy, completeness, consistency, to name a few. But there’s another factor of data quality that doesn’t get the recognition it deserves: your dataarchitecture. How the right dataarchitecture improves data quality.
Ingestion: Datalake batch, micro-batch, and streaming Many organizations land their source data into their datalake in various ways, including batch, micro-batch, and streaming jobs. Amazon AppFlow can be used to transfer data from different SaaS applications to a datalake.
She decided to bring Resultant in to assist, starting with the firm’s strategic data assessment (SDA) framework, which evaluates a client’s data challenges in terms of people and processes, data models and structures, dataarchitecture and platforms, visual analytics and reporting, and advanced analytics.
Today, the way businesses use data is much more fluid; data literate employees use data across hundreds of apps, analyze data for better decision-making, and access data from numerous locations. Then, it applies these insights to automate and orchestrate the data lifecycle.
The data products used inside the company include insights from user journeys, operational reports, and marketing campaign results, among others. The data platform serves on average 60 thousand queries per day. The data volume is in double-digit TBs with steady growth as business and data sources evolve.
Leaders rely less on data mart deployment than on lean, flexible architectures and usable data based on cloud services, a complementary datalake, data governance, data hubs and data catalogs. Leaders obviously strive towards a leaner architecture and a flexible infrastructure.
Amazon Redshift enables data warehousing by seamlessly integrating with other data stores and services in the modern data organization through features such as Zero-ETL , data sharing , streaming ingestion , datalake integration , and Redshift ML.
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
Each data producer within the organization has its own datalake in Apache Hudi format, ensuring data sovereignty and autonomy. These datasets are pivotal for reporting and analytics use cases, powered by services like Amazon Redshift and tools like Power BI.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Zero-ETL integration also enables you to load and analyze data from multiple operational database clusters in a new or existing Amazon Redshift instance to derive holistic insights across many applications. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. The delays impact delivery of the reports to senior management, who are responsible for making business decisions based on the dashboard. A DataOps implementation project consists of three steps.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
Model, understand, and transform the data Comcast faced the challenge of collecting large amounts of information about potential security and reliability issues but with no easy way to make sense of it all, says Noopur Davis, corporate EVP, CISO, and chief product privacy officer.
That data team, dubbed ’73 after Re/Max’s 1973 founding year, has about 30 IT pros building sophisticated dataarchitectures and advanced applications, including a cloud-native stack that has been running on AWS for several years. billion in 2022, resource industries $82.1 billion in 2022.
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
The Data Impact Awards 2021 aim to recognize and reward the various organizations taking advantage of the latest Big Data services to successfully manage large amounts of data and thus improve their own organizations and the world. . The company needed a modern dataarchitecture to manage the growing traffic effectively. .
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Estimated Carbon Footprint = Amount of money spent on truck transport * Emission Factor [1] Although these computations are very easy to make from general ledgers or other financial records, they are most valuable for initial estimates or for reporting minor sources of greenhouse gases.
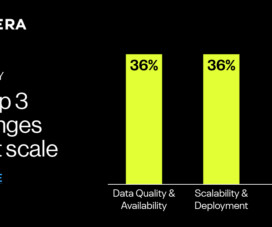
Trusted data is what makes the outputs of AI not just accurate, but impactful in decision making. Ensuring data is trustworthy comes with its own complications. Cloudera’s State of Enterprise AI and Modern DataArchitecture survey identified several challenges when it comes to data.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content