This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. Customers use datalake tables to achieve cost effective storage and interoperability with other tools. The sample files are ‘|’ delimited text files.
The need for streamlined data transformations As organizations increasingly adopt cloud-based datalakes and warehouses, the demand for efficient data transformation tools has grown. This enables you to extract insights from your data without the complexity of managing infrastructure.
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Model developers will test for AI bias as part of their pre-deployment testing. Quality test suites will enforce “equity,” like any other performance metric. Data Gets Meshier.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. They are the same.
This post was co-written with Dipankar Mazumdar, Staff Data Engineering Advocate with AWS Partner OneHouse. Dataarchitecture has evolved significantly to handle growing data volumes and diverse workloads. Data and metadata are shown in blue in the following detail diagram.
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
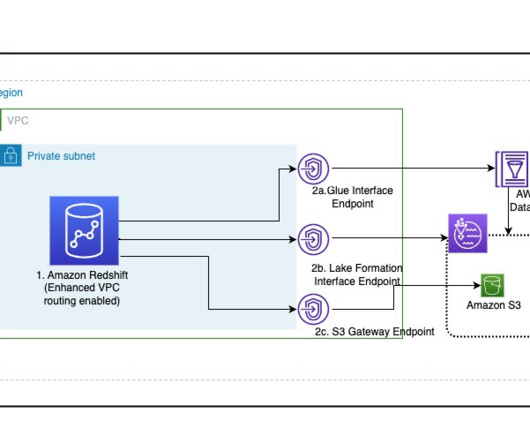
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 datalake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your datalake, enabling you to run analytical queries.
Over the years, organizations have invested in creating purpose-built, cloud-based datalakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple datalakes, each built on different technology stacks.
Many of the tests to check performance and volumes of data scanned have used Athena because it provides a simple to use, fully serverless, cost effective, interface without the need to setup infrastructure. This approach was deemed efficient and effectively mitigated Amazon S3 throttling problems.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
A modern dataarchitecture enables companies to ingest virtually any type of data through automated pipelines into a datalake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.
The Analytics specialty practice of AWS Professional Services (AWS ProServe) helps customers across the globe with modern dataarchitecture implementations on the AWS Cloud. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.
As organizations across the globe are modernizing their data platforms with datalakes on Amazon Simple Storage Service (Amazon S3), handling SCDs in datalakes can be challenging.
There’s a recent trend toward people creating datalake or data warehouse patterns and calling it data enablement or a data hub. DataOps expands upon this approach by focusing on the processes and workflows that create data enablement and business analytics. DataOps Process Hub.
This leads to having data across many instances of data warehouses and datalakes using a modern dataarchitecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation. Take note of this role’s ARN to use later in the steps.
As part of that transformation, Agusti has plans to integrate a datalake into the company’s dataarchitecture and expects two AI proofs of concept (POCs) to be ready to move into production within the quarter. Today, we backflush our datalake through our data warehouse. We’re still in that journey.”
We also examine how centralized, hybrid and decentralized dataarchitectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
Dataarchitecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and datalakes.
First, you must understand the existing challenges of the data team, including the dataarchitecture and end-to-end toolchain. The data engineer then emails the BI Team, who refreshes a Tableau dashboard. Figure 1: Example data pipeline with manual processes. Figure 2: Example data pipeline with DataOps automation.
Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights. From enhancing datalakes to empowering AI-driven analytics, AWS unveiled new tools and services that are set to shape the future of data and analytics.
Many customers are extending their data warehouse capabilities to their datalake with Amazon Redshift. They are looking to further enhance their security posture where they can enforce access policies on their datalakes based on Amazon Simple Storage Service (Amazon S3). Choose Create endpoint.
Today, customers are embarking on data modernization programs by migrating on-premises data warehouses and datalakes to the AWS Cloud to take advantage of the scale and advanced analytical capabilities of the cloud. Compare ongoing data that is replicated from the source on-premises database to the target S3 datalake.
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in datalakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your datalake.
We had been talking about “Agile Analytic Operations,” “DevOps for Data Teams,” and “Lean Manufacturing For Data,” but the concept was hard to get across and communicate. I spent much time de-categorizing DataOps: we are not discussing ETL, DataLake, or Data Science.
To bring their customers the best deals and user experience, smava follows the modern dataarchitecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
Amazon Redshift Serverless, generally available since 2021, allows you to run and scale analytics without having to provision and manage the data warehouse. Use one click to access your datalake tables using auto-mounted AWS Glue data catalogs on Amazon Redshift for a simplified experience.
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
Advanced analytics and new ways of working with data also create new requirements that surpass the traditional concepts. Many companies are therefore forced to put these concepts to the test. But what are the right measures to make the data warehouse and BI fit for the future? What role do technology and IT infrastructure play?
Success criteria alignment by all stakeholders (producers, consumers, operators, auditors) is key for successful transition to a new Amazon Redshift modern dataarchitecture. The success criteria are the key performance indicators (KPIs) for each component of the data workflow.
As Belcorp considered the difficulties it faced, the R&D division noted it could significantly expedite time-to-market and increase productivity in its product development process if it could shorten the timeframes of the experimental and testing phases in the R&D labs. This allowed us to derive insights more easily.”
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. Additionally, data is extracted from vendor APIs that includes data related to product, marketing, and customer experience.
You might be modernizing your dataarchitecture using Amazon Redshift to enable access to your datalake and data in your data warehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. Select the data share and choose Authorize.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Carrefour Spain , a branch of the larger company (with 1,250 stores), processes over 3 million transactions every day, giving rise to challenges like creating and managing a datalake and honing down key demographic information. . Working with Cloudera, Carrefour Spain was able to create a unified datalake for ease of data handling.
Real-Time Intelligence, on the other hand, takes that further by supporting data in AWS, Google Cloud Platform, Kafka installations, and on-prem installations. “We We introduced the Real-Time Hub,” says Arun Ulagaratchagan, CVP, Azure Data at Microsoft. Morrone notes that in the next race, the company will test Azure Private 5G Core.
The biggest challenge for any big enterprise is organizing the data that has organically grown across the organization over the last several years. Everyone has datalakes, data ponds – whatever you want to call them. How do you get your arms around all the data you have? So, real-time data has become air.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 datalake.
It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless data integration is a key requirement in a modern dataarchitecture to break down data silos. We observed that our TPC-DS tests on Amazon S3 had a total job runtime on AWS Glue 4.0
Test the connection with SAP using the wheel file. Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in big data services. He is passionate about helping customers build modern dataarchitecture on the AWS Cloud. The high-level steps are as follows: Clone the PyRFC module from GitHub.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
Tens of thousands of customers run business-critical workloads on Amazon Redshift , AWS’s fast, petabyte-scale cloud data warehouse delivering the best price-performance. With Amazon Redshift, you can query data across your data warehouse, operational data stores, and datalake using standard SQL.
Clean up After you complete all the steps and finish testing, complete the following steps to delete resources to avoid incurring costs: On the AWS CloudFormation console, choose the stack you created. He also understands how to apply technologies to solve big data problems and build a well-designed dataarchitecture.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content